Download

1 / 31
340 likes | 597 Views
Hidden Markov Model (HMM) Tagging. Using an HMM to do POS tagging HMM is a special case of Bayesian inference. Hidden Markov Model (HMM) Taggers. Goal: maximize P(word|tag) x P(tag|previous n tags) P(word|tag) word/lexical likelihood probability that given this tag, we have this word

E N D
Hidden Markov Model (HMM) Tagging • Using an HMM to do POS tagging • HMM is a special case of Bayesian inference
Hidden Markov Model (HMM) Taggers • Goal: maximize P(word|tag) x P(tag|previous n tags) • P(word|tag) • word/lexical likelihood • probability that given this tag, we have this word • NOT probability that this word has this tag • modeled through language model (word-tag matrix) • P(tag|previous n tags) • tag sequence likelihood • probability that this tag follows these previous tags • modeled through language model (tag-tag matrix) Lexical information Syntagmatic information
POS tagging as a sequence classification task • We are given a sentence (an “observation” or “sequence of observations”) • Secretariat is expected to race tomorrow. • sequence of n words w1…wn. • What is the best sequence of tags which corresponds to this sequence of observations? • Probabilistic/Bayesian view: • Consider all possible sequences of tags • Out of this universe of sequences, choose the tag sequence which is most probable given the observation sequence of n words w1…wn.
Getting to HMM • Let T = t1,t2,…,tn • Let W = w1,w2,…,wn • Goal: Out of all sequences of tags t1…tn, get the the most probable sequence of POS tags T underlying the observed sequence of words w1,w2,…,wn • Hat ^ means “our estimate of the best = the most probable tag sequence” • Argmaxxf(x) means “the x such that f(x) is maximized” it maximizes our estimate of the best tag sequence
Bayes Rule We can drop the denominator: it does not change for each tag sequence; we are looking for the best tag sequence for the same observation, for the same fixed set of words
Likelihood and prior Further Simplifications 1. the probability of a word appearing depends only on its own POS tag, i.e, independent of other words around it n 2. BIGRAM assumption: the probability of a tag appearing depends only on the previous tag 3. The most probable tag sequence estimated by the bigram tagger
Likelihood and prior Further Simplifications 2. BIGRAM assumption: the probability of a tag appearing depends only on the previous tag. Bigrams are groups of two written letters, two syllables, or two words; they are a special case of N-gram. Bigrams are used as the basis for simple statistical analysis of text The bigram assumption is related to the first-order Markov assumption
Likelihood and prior Further Simplifications 3. The most probable tag sequence estimated by the bigram tagger --------------------------------------------------------------------------------------------------------------- n biagram assumption
Probability estimates • Tag transition probabilities p(ti|ti-1) • Determiners likely to precede adjectives and nouns • That/DT flight/NN • The/DT yellow/JJ hat/NN • So we expect P(NN|DT) and P(JJ|DT) to be high
Estimating probability • Tag transition probabilities p(ti|ti-1) • Compute P(NN|DT) by counting in a labeled corpus: # of times DT is followed by NN
Two kinds of probabilities • Word likelihood probabilities p(wi|ti) • P(is|VBZ) = probability of VBZ (3sg Pres verb) being “is” • Compute P(is|VBZ) by counting in a labeled corpus: If we were expecting a third person singular verb, how likely is it that this verb would be is?
An Example: the verb “race” Two possible tags: • Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NR • People/NNS continue/VB to/TO inquire/VB the/DT reason/NN for/IN the/DTrace/NN for/IN outer/JJ space/NN How do we pick the right tag?
Disambiguating “race” • P(NN|TO) = .00047 • P(VB|TO) = .83 The tag transition probabilities P(NN|TO) and P(VB|TO) answer the question: ‘How likely are we to expect verb/noun given the previous tag TO?’ • P(race|NN) = .00057 • P(race|VB) = .00012 Lexical likelihoods from the Brown corpus for ‘race’ given a POS tag NN or VB.
Disambiguating “race” • P(NR|VB) = .0027 • P(NR|NN) = .0012 tag sequence probability for the likelihood of an adverb occurring given the previous tag verb or noun • P(VB|TO)P(NR|VB)P(race|VB) = .00000027 • P(NN|TO)P(NR|NN)P(race|NN)=.00000000032 Multiply the lexical likelihoods with the tag sequence probabilities: the verb wins
Hidden Markov Models • What we’ve described with these two kinds of probabilities is a Hidden Markov Model (HMM) • Let’s just spend a bit of time tying this into the model • In order to define HMM, we will first introduce the Markov Chain, or observable Markov Model.
Definitions • A weighted finite-state automaton adds probabilities to the arcs • The sum of the probabilities leaving any arc must sum to one • A Markov chain is a special case of a WFST in which the input sequence uniquely determines which states the automaton will go through • Markov chains can’t represent inherently ambiguous problems • Useful for assigning probabilities to unambiguous sequences
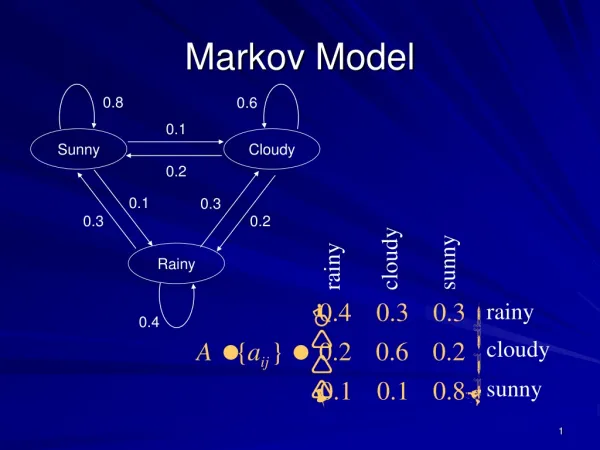
Hidden Markov Models Formal definition • States Q = q1, q2…qN; • Observations O = o1, o2…oN; • Each observation is a symbol from a vocabulary V = {v1,v2,…vV} • Transition probabilities (prior) • Transition probability matrix A = {aij} • Observation likelihoods (likelihood) • Output probability matrix B={bi(ot)} a set of observation likelihoods, each expressing the probability of an observation ot being generated from a state i, emission probabilities • Special initial probability vector i the probability that the HMM will start in state i, each i expresses the probability p(qi|START)
Assumptions • Markov assumption: the probability of a particular state depends only on the previous state • Output-independence assumption: the probability of an output observation depends only on the state that produced that observation
HMM Taggers • Two kinds of probabilities • A transition probabilities (PRIOR) • B observation likelihoods (LIKELIHOOD) • HMM Taggers choose the tag sequence which maximizes the product of word likelihood and tag sequence probability
HMM Taggers • The probabilities are trained on hand-labeled training corpora (training set) • Combine different N-gram levels • Evaluated by comparing their output from a test set to human labels for that test set (Gold Standard)
The Viterbi Algorithm • best tag sequence for "John likes to fish in the sea"? • efficiently computes the most likely state sequence given a particular output sequence • based on dynamic programming
A smaller example a b b a 0.2 0.8 0.4 • What is the best sequence of states for the input string “bbba”? • Computing all possible paths and finding the one with the max probability is exponential 0.6 0.7 end start r q 1 1 0.5 0.3 0.5
Possible improvements • in bigram POS tagging, we condition a tag only on the preceding tag • why not... • use more context (ex. use trigram model) • more precise: • “is clearly marked” --> verb, past participle • “he clearly marked” --> verb, past tense • combine trigram, bigram, unigram models • condition on words too • but with an n-gram approach, this is too costly (too many parameters to model)
Further issues with Markov Model tagging • Unknown words are a problem since we don’t have the required probabilities. Possible solutions: • Assign the word probabilities based on corpus-wide distribution of POS ??? • Use morphological cues (capitalization, suffix) to assign a more calculated guess. • Using higher order Markov models: • Using a trigram model captures more context • However, data sparseness is much more of a problem.