Download
1 / 29
300 likes | 536 Views
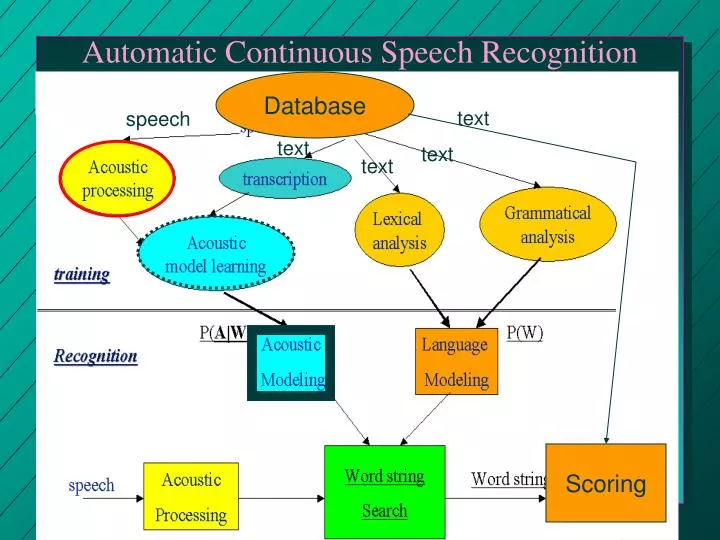
Database. text. speech. text. text. text. Scoring. Automatic Continuous Speech Recognition. Automatic Continuous Speech Recognition. Problems with isolated word recognition: Every new task contains novel words without any available training data.

E N D
Database text speech text text text Scoring Automatic Continuous Speech Recognition
Automatic Continuous Speech Recognition • Problems with isolated word recognition: • Every new task contains novel words without any available training data. • There are simply too many words, and this words may have different acoustic realizations. Increases variability • coarticulation of “words” • Speech velocity • we don´t know the limits of the words.
In CSR, should we use words? Or what is the basic unit to represent salient acoustic and phonetic information?
Model Units Issues • Accurate. • Represent the acoustic realization that appears in different contexts. • Trainable • Generalizable: • New words can be derived
Comparison of Different Units • Words: • Small task. • accurate, trainable, no-generalizable • Large Vocabulary: • accurate, non-trainable, no-generalizable. • Phonemes: • Large Vocabulary: • No-accurate, trainable, over-generalizable
Syllables • English: 30,000 • No-very-accurate, no-trainable, generalizable • Chinese: 1200 tone-dependent syllables • Japanese: 50 syllables for • accurate, trainable, generalizable • Allophones: Realizations of phonemes in different context. • accurate, no-trainable, generalizable • Triphones: Example of allophone.
Traning in Sphinx phonemes set is trained triphones are created triphones are trained senons are created senons are prunned senons are trained: 1-gaussians to 8_or_16-gaussinas
Context Independent: Phonemes • SPHINX: model_architecture/Telefonica.ci.mdef • Context Dependent:Triphone: • SPHINX: model_architecture/Telefonica.untied.mdef
Clustering Acoustic-Phonetic Units • Many Phones have similar effects on the neighboring phones, hence, many triphones have very similar Markov states. • A senone is a cluster of similar Markov states. • Advantages: • More training data. • Less memory used.
Senonic Decision Tree (SDT) • SDT Classify Markov States of Triphones represented in the training corpus by asking Linguistic Questions composed of Conjuntions, Disjunctions and/or negations of a set of predetermined questions.
Decision Tree for Classifying the second state of k-triphone Is left phone (LP) a sonorant or nasal? yes Is LP /s,z,sh,sh/? Is right phone (RP) a back-R? Is RF voiced? Senone 5 Senone 1 Senone 6 Is LP back L or ( LC neither a nasal or RF A LAX-vowel)? Senone 4 Senone 3 Senone 2
When applied to the word welcome Is left phone (LP) a sonorant or nasal? yes Is left phone /s,z,sh,sh/? Is right phone (RP) a back-R? Is RF voiced? Senone 5 Senone 1 Senone 6 Is LP back L or ( LC neither a nasal or RF A LAX-vowel)? Senone 4 Senone 3 Senone 2
The tree can automatically constructed by searching, for each node, the question that the maximum entropy decrease • Sphinx: • Construction: $base_dir/ c_scripts/03.bulidtrees. • Results: $base_dir/trees/Telefonica.unpruned/A-0.dtree • When the tree grows, it needs to be pruned • Sphinx: • $base_dir/ c_scripts/ 04.bulidtrees. • Results:aA • $base_dir/trees/Telefonica.500/A-0.dtree • $base_dir/Telefonica_arquitecture/Telefonica.500.mdef
Words • Words can be modeled using composite HMMs • A null transition is used to go from one subword unit to the following /sil/ /uw/ /sil/ /t/
Database text speech text text text Scoring Continuous Speech Training
For each utterance to train, the subword units are concatenated to form words model. • Sphinx: Dictionary • $base_dir/training_input/dict.txt • $base_dir/training_input/train.lbl
/o/ /sil/ /sil/ /f/ /r/ /s/ /x/ /uw/ /t/ /i/ • Let’s assume we are going to train the phonemes in the sentence: • Two four six. • The phonems of this sentence are: • /t//w//o//f//o//r//s//i//x/ • Therefore the HMM will be:
We can estimate the parameters for each HMM using the forward-backward reestimation formulas already definded.
The ability to automatically align each individual HMM to the corresponding unsegmented speech observation sequence is one of the most powerful features in the forward-backward algorithm.
Database text speech text text text Scoring Language Models for Large Vocabulary Speech Recognitin
Instead of using: • The recongition can be imporved using the calculating the Maximum Posteriory Probability: Viterbi Languaje Model
Language Models for Large Vocabulary Speech Recognitin • Goal: • Provide an estimate of the probability of a “word” sequence (w1 w2 w3 ...wQ) for the given recognition task. • This can be solved as follows:
Since, it is impossible to reliable estimate the conditional probabilities, • hence in practice it is used an N-gram language model: • En practice, realiable estimators are obtained for N=1 (unigram) N=2 (bigram) or possible N=3 (trigram). j
Examples: • Unigram: P(Maria loves Pedro)=P(Maria)P(loves)P(Pedro) • Bigram: P(Maria|<sil>)P(loves|Maria)P(Pedro|loves)P(</sil>|Pedro)
CMU-Cambridge Language Modeling Tools • $base_dir/c_scripts/languageModelling
Database text speech text text text Scoring
C(Wi-2 Wi-1 Wi ) P(Wi| Wi-2,Wi-1)= C(Wi-2 Wi-1) where C(Wi-2 Wi-1 )=Total Number Sequence Wi-2 Wi-1 was observed C(Wi-2 Wi-1 Wi ) =Total Number Sequence Wi-2 Wi-1 Wi was observed




















