Download
1 / 106
1.06k likes | 1.17k Views
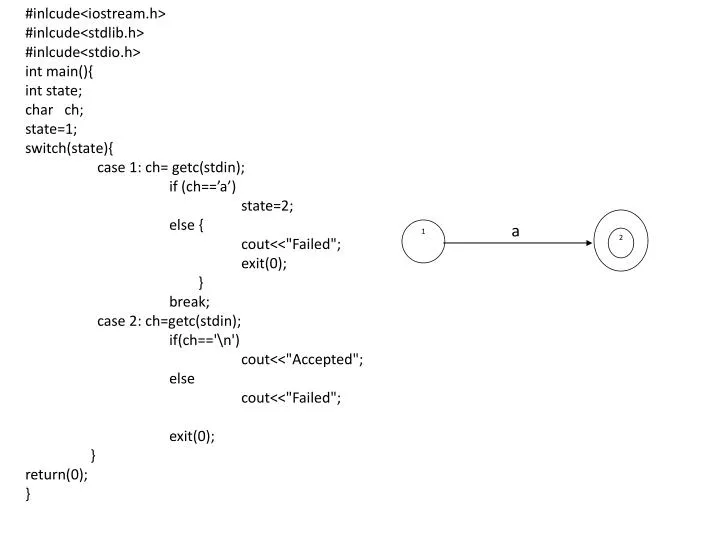
#inlcude<iostream.h> #inlcude<stdlib.h> #inlcude<stdio.h> int main(){ int state; char ch; state=1; switch(state){ case 1: ch= getc(stdin); if (ch==’a’) state=2; else { cout<<"Failed"; exit(0); } break; case 2: ch=getc(stdin); if(ch=='<br>')

E N D
#inlcude<iostream.h> #inlcude<stdlib.h> #inlcude<stdio.h> int main(){ int state; char ch; state=1; switch(state){ case 1: ch= getc(stdin); if (ch==’a’) state=2; else { cout<<"Failed"; exit(0); } break; case 2: ch=getc(stdin); if(ch=='\n') cout<<"Accepted"; else cout<<"Failed"; exit(0); } return(0); } 2 a 1
b 2 1 a #inlcude<iostream.h> #inlcude<stdlib.h> #inlcude<stdio.h> int main(){ int state; char ch; state=1; while(1){ switch(state){ case 1: ch = getc(stdin); if (ch==’a’) state=1; else if(ch == 'b')state=2; else { cout<<"Failed"; exit(0); } break; case 2: ch=getc(stdin); if(ch=='\n')cout<<"Accepted"; else cout<<"Failed"; exit(0); } } return(0); }
[a-zA-Z0-9] 2 1 [a-zA-Z] #inlcude<iostream.h> #inlcude<stdlib.h> #inlcude<stdio.h> int main(){ int state; char ch; state=1; while(1){ switch(state){ case 1: ch = getc(stdin); if ((ch>=’a’ && 'z'>=ch )|| (ch>=’A’ && 'Z'>=ch) ) state=2; else { cout<<"Failed"; exit(0); } break; case 2:ch = getc(stdin); if(ch=='\n'){ cout<<"Accepted"; exit(0); } else if ((ch>=’a’ && 'z'>=ch )|| (ch>=’A’ && 'Z'>=ch) || (ch>=’0’ && '9'>=ch)) state=2; else { cout<<"Failed"; exit(0); } exit(0); break; } return(0); } [a-zA-Z
[0-9] [a-zA-Z0-9] 7 2 6 1 [0-9] [a-zA-Z] [1-9] [1-9] 3 4 5 [ \n] 8 [0-9] . 4
int fail(int start) • { • intnextstart; • switch(start){ • case 1:nextstart=3; // اعداد اعشاري • break; • case 3:nextstart=6; // اعداد صحيح • break; • case 6:nextstart=8; // فضاي خالي • break; • } • return nextstart; • }
int main{ int state,start,loc; char ch; FILE *fp; fp=fopen("source.txt","r"); state=1; start=1; while(1) switch(state){ case 1: loc=ftell(fp); ch=getc(fp); if((ch>='a' && ch<='z') || (ch>='A' && ch<='Z')) state=2; else{ start=fail(start); state=start; fseek(fp,loc,SEEK_SET); } break;
case 2:ch=getc(fp); if((ch>='a' && ch<='z') || (ch>='A' && ch<='Z') || (ch>='0' && ch<='9')) state=2; else if (ch==' '|| ch=='\n'|| ch==EOF){ cout<<"ID "; state=8; } else{ start=fail(start); state=start; fseek(fp,loc,SEEK_SET); } break; case 3: loc=ftell(fp); ch=getc(fp); if(ch>='1' && ch<='9') state=4; else { start=fail(start); state=start; fseek(fp,loc,SEEK_SET); } break;
اولویت ها ممكن است بخشي از يك دنباله از كاراكترها با يك عبارت باقاعده و بخش ديگریبا عبارت باقاعده ديگري منطبق شود. به عنوان مثال دنباله 123.65و دو عبارت با قاعده ذيل را در نظر مي گيريم. [1-9][0-9]* [1-9][0-9]*. [0-9][1-9]* . پذيرش طولاني ترين دنباله است
ممكن يك دنباله از كاراكترها (نه بخشي از يك دنباله) با دو يا چند عبارت باقاعده منطبق شود به عنوان مثال رشته if مي تواند توسط دو عبارت باقاعده ذيل توليد شود. if [a-zA-Z][a-zA-Z0-9]* عبارت با قاعده اي كه اولويت بيشتري دارد، ابتدا مقايسه مي شود.
int fail(int start){ int nextstart; switch(start){ case 1:nextstart=6; // اعداد صحيح break; case 3:nextstart=8; break; case 6:nextstart=3; // اعداد اعشاري break; } return (nextstart); }
توليد خودكار تحليلگر لغوي • استفاده از ابزارها داراي مزايا و معايبي است كه عبارتند از: • افزايش سرعت ايجاد تغييرات • كاهش زمان ساخت تحليلگر لغوي • افزايش محدوديتها
برنامه به زبان FLex كامپايل بوسيله Flex برنامه به زبان C يا پاسكال كامپايل بوسيله كامپايلر C تحليلگر لغوي پياده سازي تحليلگر لغوي به وسيله توليدكننده تحليلگر لغوي
c:\> flex pascal.l scanner.c • بعد از کامپایل و تولید فایل اجرایی • c:\> scanner.exe< p1 • c:\> scanner.exe <p1> result • c:\> scanner.exe رشته هاي مورد نظر
flexساختار برنامه به زبان • تعاريف • %% • ترجمه ها • %% • توابع
مثال digit [0-9] lower [a-z] upper [A-Z] letter lower|upper var {letter}|({letter}|{digit})* ws [ \n\t]+ %% ws {} “if” {printf(“I found ‘IF’ keyword”);} “else” {printf(“I found ‘ELSE’ keyword”);} var {printf(“I found variable “);} %%
اگر متن ذيل به عنوان ورودي به اين تحليلگر داده شود. • if temp else if id 34 • خروجي به صورت ذيل خواهد بود. • I found ‘if’ keyword • I found variable • I found ‘ELSE’ keyword • I found ‘if’ keyword • I found variable
%option noyywrap %{ intnchar,nline; %} %% [\n] {nline++;} . {nchar++;} } %% int main(void){ yylex(); printf("%d %d",nchar,nline+1); return (0); }
کلمات کلیدی روش اول [a-zA-Z]([a-zA-Z0-9])* printf("ID "); "program" printf("PROGRAM "); "var" printf("VAR "); "begin" printf("BEGIN "); "end" printf("END ");
کلمات کلیدی روش دوم void toupper(char k[]) { int i; for(i=0;i<=strlen(k);++i) if(k[i]<='z' && k[i]>='a') k[i]-=32; } int is_keyword(char id[]) { char keyword[40][20]={"AND", "ARRAY","BEGIN","CASE","CONST","DIV","DO","DOWNTO","ELSE","END","EXTERNAL","EXTERN","FILE", "FOR","FORWARD","FUNCTION","GOTO","IF","IN","LABEL","MOD","NIL","NOT","OF","OR","OTHERWISE", "PROCEDURE", "PROGRAM","RECORD","REPEAT","THEN","TO","TYPE","UNTIL","VAR","WHILE","WITH"}; int i; for(i=0;i<40;i++) if(strcmp(id,keyword[i])==0) return i; return -1; } %}
[a-zA-Z]([a-zA-Z0-9])* {toupper(yytext); if (is_keyword(yytext)!=-1) printf("keword=%s",yytext); else printf("ID "); }
حساس به حالت • A [aA] • B [bB] • C [cC] • D [dD] • E [eE] . . .
{A}{N}{D} return(AND); • {A}{R}{R}{A}{Y} return(ARRAY); • {C}{A}{S}{E} return(CASE); • {C}{O}{N}{S}{T} return(CONST); • {D}{I}{V} return(DIV); • {D}{O} return(DO);
حساس به حالت روش دوم [a-zA-Z]([a-zA-Z0-9])* {toupper(yytext); if (is_keyword(yytext)!=-1) return (KW); else return(IDENTIFIER ); }
فاكتور گيري چپ • براي يك غير پايانه ممكن است انتخابهاي مختلفي وجود داشته باشد به طوريكه شروع يكسان داشته باشند. به عنوان مثال به گرامرهاي ذيل دقت كنيد. • A a B | aD • و يا • A cd B | cdg D
حذف بازگشتی چپ • A 1 | 2 | 3 ... | n • : شروع مشترك • :i قسمت غير مشترك • گرامر فوق را میتوان به صورت ذيل نشان داد كه همان زبان را توليد میكند: • A R • R 1 | 2 | 3 | ..
مثال • Acd B | cdg D • BbB | c • DdD | e • با توجه به AcdB|cdgD قسمت مشترك cd است در نتيجه: • = cd • 1=gD • 2=B • گرامر را میتوان به صورت ذيل نشان داد. • Acd R • R B | g D • BbB | c • DdD | e
تحليلگر لغوي برنامه مبدا را به دنبالهاي از نشانهها تبديل كرده و به تحليلگر نحوي ارسال میكند. اگر اين دنباله توسط گرامر زبان مبدا قابل توليد باشد، برنامه مبدا از نظر نحوي صحيح است در غير اين صورت داراي خطاي نحوي است.
تجزیه • فرايند تجزيه نشان میدهد آيا دنبالهاي از نشانهها توسط گرامر قابل توليد است يا خير. روالي كه فرايند تجزيه را انجام میدهد، تجزيه كننده ناميده می شود.
انواع تجزيه كنندهها • - تجزيه كنندههاي بالا به پايين • - تجزيه كنندههاي پايين به بالا
ترتیب ساخته شدن درخت تجزیه Preorderبالا به پایین: Postorderپایین به بالا:
ترتیب ساختن درخت تجزیه در روش بالا به پایین
ترتیب ساختن درخت تجزیه در روش پایین به بالا
مثال • E E + T | E - T | T • T T * F | T / F | F • F id • نحوه ساختن درخت تجزیه برای رشته : • Id+id+id
first() اگر دنبالهاي از پايانهها و غير پايانهها باشد، مجموعه first مربوط به پايانههايي را مشخص ميكند كه رشتههاي مشتق شده از با آنها شروع ميشوند. اگر بتواند را توليد كند، نيز به first() اضافه ميشود.
مثال A BCd B bB | e | C aC | به رشتههايي كه از BCd مشتق شدهاند دقت كنيد. BCdd BCdbBCd bBd bd BCdeCd ed BCdCd aCd ad first(BCd)={d,b,e,a}
با توجه به گرامر ذيل first(aA) و first(aB) را محاسبه كنيد. • A→ a A|a B • B→ b B| c • با توجه به گرامر، رشتههاي مشتق شده از aA فقط با a و رشتههاي مشتق شده از aB فقط با a شروع ميشوند، بنابراين: • first(aA) = {a } • first(aB) = {a }
firstقوانین محاسبه 1-اگر پايانه باشد آنگاهfirst() برابر مجموعه {} است. • مثال در گرامر فوق داريم: • first(a)={a} • first(b)={b}
2-اگر بتواند را توليد كند، آنگاه به مجموعه first() اضافه میگردد. 3- اگر X غير پايانه و XY1Y2Y3...Yn باشد و مجموعههاي first(Y1),first(Y2),...first(Yn) شامل باشند يعني همه Yi بتوانند تهي را توليد كنند. در نتيجه X نيز میتواند را توليد كند كه در اين صورت به مجموعه first(X) اضافه میگردد. مثال:first(X) • S AB • A aA | bB | a | • B bB | b |
4- اگر X غير پايانه و XY1Y2Y3...Yn باشد، مجموعه first(Y1) (به جز )به مجموعه first(X) اضافه میگردد. زيرا first(Y1) مجموعه پايانههايي هستند كه در شروع رشتههايي كه توسطY1 توليد میشوند قرار دارند از آنجاييكه X با Y1 شروع میشود، پس X با پايانههاي first(Y1) شروع ميشوند، در نتيجه first(Y1) به first(X) اضافه میگردد.
اگر X غير پايانه و XY1Y2Y3...Yn باشد و در مجموعه first(Y1) باشد (Y1 میتواند را توليد كند) در اين صورت علاوه بر first(Y1) (به جز) مجموعه first(Y2) (به جز) نيز به first(X) اضافه میگردد. • به گرامر ذيل دقت كنيد • A Bab • B c | d |
follow(A • مجموعه follow(A)پايانههايي را مشخص میكند كه در اشتقاقهاي مختلف بلافاصله در سمت راست A قرار میگيرند اين مجموعه را با follow(A) نشان می دهيم.
X aXAad | a A Ac | Af | محاسبه XaXAad XaXAad aXAcad XaXAad aXAcad aXAfcad با توجه به مراحل بالا میتوان نتيجه گرفت كه: • follow(A)={a,c,f}
قوانین • اگر S نماد شروع باشد $ ($ نشان دهنده آخر رشته ورودي است) به follow(S) اضافه میشود.