Download

1 / 8
80 likes | 186 Views
Quantitative Data Preparation Alasdair Crockett, ESDS Data Services Manager. What characterises a “good” quantitative dataset?. i) Accurate data ii) Well labelled data iii) Well documented data

E N D
Quantitative DataPreparationAlasdair Crockett, ESDSData Services Manager
What characterises a “good” quantitative dataset? i) Accurate data ii) Well labelled data iii) Well documented data iv) Data that can be stored in user-friendly “dissemination” formats, but can also be archived in a future-proof “preservation” format
Accuracy of data: validation checks Computer aided surveys (CAPI, CATI or CAWI) These are the most accurate way of gathering survey data, but the software (e.g. Blaise) and hardware (e.g. a laptop for every interviewer) may be beyond project resources Computer aided surveys allow one to build in as many logical checks - on question routing and responses - as is possible at the point of data creation. Non computer aided surveys Less control over initial responses, but checks can performed: • At the point of data entry/transcription if “data entry” software is used. However, there are few cheap data entry packages around. • The only feasible option may be to enter data without checks directly into a spreadsheet style interface (e.g. Excel worksheet, SPSS data view), and perform validation checks afterwards - via command files in statistical packages or Visual Basic code in Excel or Access
An example of data seemingly untouched by the human eye: Originating error in text variables: Occupation Description of Occupation ‘sole trader’ ‘purveyor of seafood’ Propagated error in derived numeric variables: • Respondent was coded under the standard occupational (SIC) code relating to food retailers: 52.2 Retail sale of food, beverages and tobacco in specialised stores
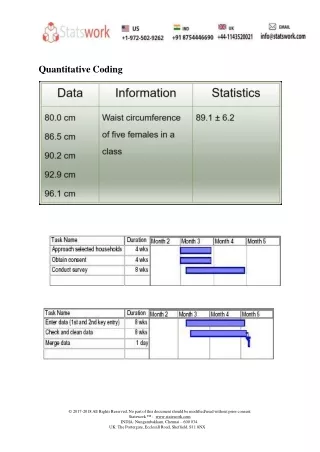
Labelling of data I • All variables should be named. Variable names should not exceed 8 characters where possible, as the most common format for disseminating data is SPSS. • All variables should be labelled. Labels should be brief (preferably < 80 characters), but precise and always make explicit the unit of measurement for continuous (interval) variables. Where possible, all variable labels should reference the question number (and if necessary questionnaire). For example, the variable q11bhexc might have the label “q11b: hours spent taking physical exercise in a typical week”. This gives the unit of measurement and a reference to the question number (q11b), so the user can quickly and easily cross-reference to it.
Labelling of data I • For categorical variables, all codes (values) should be given a brief label (preferably < 60 characters). For example, p1sex (gender of person 1) might have these value labels: 1 = male, 2 = female, -8 = don’t know, -9 = not answered. • Where possible, all such labelling should be created and supplied to the UKDA as part of the data file itself. This is the expectation with data supplied in one of the three major statistical packages - SPSS, STATA or SAS.
Documentation Core documentation: Questionnaire. Methodology: details of sample design, response rate, etc. “Codebook”, i.e. a comprehensive list of variable names, variable descriptions, code names and variable formatting information. This is essential If the package being used for data management does not allow the sort of variable and code labelling to be stored within the data file Technical report describing the research project. Other useful documentation that is seldom supplied: Code used to create derived variables or check data (e.g. SPSS, STATA or SAS “command files”).
Preferred format(s) Acceptable format(s) Problematic format(s) Data held in a statistical package SPSS - portable (.por) or system (.sav) file. STATA; SAS (with formats information), delimited text Fixed-width (undelimited) text format. Data held in a Spreadsheet Delimited text (tab delimited or comma separated), Excel, Lotus Quattro Pro Data held in a database Delimited text with SQL data definition statements,MSACCESS, dBase, FoxPro, SIR export, XML Filemaker Pro, Paradox Fixed-width (undelimited) text format. Documentation(e.g. questionnaires, codebooks, interviewers instructions, project description, etc.) Microsoft Word, Adobe PDF, Rich text format (RTF) SGML, HTML, XML, WordPerfect Hard copy (paper) Good and bad data documentation formats For full details for all types of data see: http://www.data-archive.ac.uk/depositingData/howtoDeposit.asp#format