Download
1 / 38
380 likes | 398 Views
Learn about modeling multivariate time series data in a state-space framework using machine learning estimation in the Kalman Filter. Explore first-order autoregressive structures and VARMA models, as well as latent factors, covariance matrices, and regression parameters.

E N D
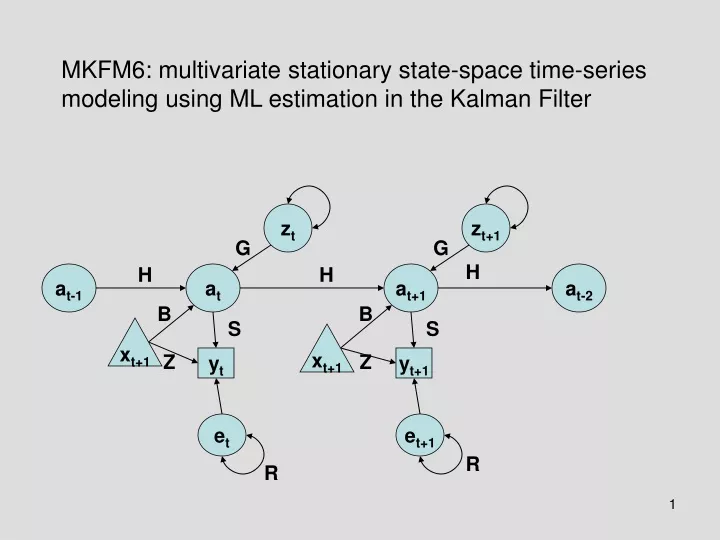
zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt+1 xt+1 Z Z yt yt+1 et et+1 R R MKFM6: multivariate stationary state-space time-series modeling using ML estimation in the Kalman Filter
y[t] an ny dimensional random vector repeatedly observed at occasion t-1...t...t+1 in a sample of N=1 or N>1 Q Q zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt xt+1 Z Z yt yt+1 et et+1 t=1.....T R R
y[t] = Sa[t] S=I Q Q zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt xt+1 Z Z yt yt+1 et et+1 R R
y[t] = Sa[t] a[t+1] = Ha[t+1] + Gz[t+1] G=I Q Q zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt xt+1 Z Z yt yt+1 et et+1 1st Order Autoregressive in structure, Markov model VARMA(p,q) models R R
y[t] = Sa[t] + e[t] S≠I a[t+1] = Ha[t+1] + Gz[t+1] Q Q at latent (as in factor analysis) zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt xt+1 Z Z yt yt+1 yt observed et et+1 R R
y[t] = Sa[t] + e[t] + Zx[t] a[t+1] = Ha[t+1] + Gz[t+1] covariance matrices regression parameters Q Q zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt xt+1 yt yt+1 Z Z et et+1 R R x is fixed regressor (e.g., if x=1, Z are means)
y[t] = Sa[t] + e[t] + Zx[t] a[t+1] = Ha[t+1] + Gz[t+1] + Bx[t+1] covariance matrices regression parameters Q Q zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt xt+1 yt yt+1 Z Z et et+1 R R
y[t] = Sa[t] + d+ e[t] + Zx[t] a[t+1] = Ha[t+1] + c + Gz[t+1] + Bx[t+1] d and c superfluous, but convenient Q Q zt zt+1 G G H H H at-1 at at+1 at-2 B B S S xt xt+1 Z yt Z yt+1 et et+1 R R
y[t] = Sa[t] + d+ e[t] + Zx[t] a[t+1] = Ha[t+1] + c + Gz[t+1] + Bx[t+1] d and c superfluous, but convenient Q Q zt zt+1 G G H H H at-1 at at+1 at-2 c c S S 1 1 d yt d yt+1 et et+1 R R
zt-1 zt zt+1 at-1 at at+1 y y y y y y y y y e e e e e e e e e time subject yt-11yt1yt+11 ....... yT1 ..... yt-1NytNyt+1N ....... yTN N Groups T type Software large ≥1 small SEM LISREL, M+, Mx small ≥1 intermediate hybrid MKFM 1 ≥1 large Timeseries Many, MKFM Acually all structural equation modeling, the details dictate computational strategies
Q Q Q zt-1 zt zt+1 G G G at-1 at at+1 1 H H d S S S y y y y y y y y y e e e e e e e e e R R R Syntax nm=1 se=yes mo=1 ny=4 ne=1 nx=0 df=ts1 rf=no ns=1 mi=-9 S=1 R=1 H=1Q=1d=1 c=0 Z=0 P=1 B=0 G=1
S=1 R=1 H=1Q=1d=1 c=0 Z=0 P=1 B=0 G=1 R fi di 0 0 0 0 R fr di 1 2 3 4 G fi di 1 G fr di 0 d fr 11 12 13 14 d fi 0 0 0 0 H fi 0 H fr 21 Q fi fu 1 Q fr fu 31 S fi 1 0 0 0 S fr 0 41 42 43 Syntax
Model 1 of 1 S parameters 1.000 0.934 0.812 0.683 R parameters - diagonal 0.395 0.453 0.563 0.500 H parameters 0.799 Q parameters 0.348 d parameters 4.936 5.081 5.030 4.947 G parameters - diagonal 1.000 output Q zt-1 G at-1 H 1 d S y y y y e e e e R
Colored lines - observed series Black line - estimated latent series (Kalman Filter)
Q Q Q zt-1 zt zt+1 G G G at-1 at at+1 H H 1 d S S S y y y y y y y y y e e e e e e e e e R R R Q: what if H is zero?
Q Q Q zt-1 zt zt+1 G G G at-1 at at+1 1 d S S S y y y y y y y y y e e e e e e e e e R R R Q: what ifH is zero? A: data at each occasion are independent. If H is zero, I can fit the model in LISREL (or Mx, or M+) Or in MKFM6
Q zt+1 I at+1 S y y y e e e R H=0 S parameters 1.000 0.867 0.841 0.665 LAMBDA-Y 1.000 0.867 0.841 0.665 Q parameters 0.949 PSI 0.949 R parameters - diagonal 0.557 0.481 0.472 0.634 THETA-EPS 0.557 0.481 0.472 0.634
Similarities between the LISREL model and the MKF State- Space model. measurement (linear factor) model y[t] = Sa[t] + d + e[t] + Zx[t] y[i] = Lh[i] + t + e[i] structural regression model a[t+1] = Ha[t+1] + c + Gz[t+1] + Bx[t+1] h[i] = Bh[i] + a + Iz[t+1] cov(e) = Rcov(e) =Q regression parameters covariance matrices cov(z) = GQG' = Qcov(z) = Y Sy-Miin Chow et al. SEM 2010. next example VAR
x x B B Q a1t a1t+1 a2t a2t+1 H a3t a3t+1 d 1 1 Restricted vector autoregressive model, S=I y[t] and a[t] variables identical
regression on fixed x x x B B Q a1t a1t+1 a2t a2t+1 H a3t a3t+1 intercepts d 1 1 Effect of x on a2 and a3 via a1 (a causal model)
timeseries a1, a2, a3 x fixed variable gaps: 25% missing in each series
G fi di 1 1 1 G fr di 0 0 0 d fr 1 2 3 d fi 0 0 0 H fi 0 0 0 0 0 0 0 0 0 H fr 4 5 6 7 8 9 10 11 12 Q fi di 1 1 1 Q fr di 21 22 23 S fi di 1 1 1 S fr di 0 0 0 B fr 31 32 33 B fi 0 0 0 x x B B Q a1t a1t+1 a2t a2t+1 H a3t a3t+1 d 1 1 S=1 R=0 H=1Q=1d=1 c=0 Z=0 P=1 B=1G=1 next example latent var
D - depression, A anxiety D D A A S≠I: autoregressive / cross lagged regressive model - with indicators
D D A A D D A A D - depression, A anxiety wife husband
N=1 Meas. Inv. of indicators w.r.t. external variable x x x z z z z a a a a y y y y y y y y y y y y e e e e e e e e e e e e B S H d (not shown) i.e. intercepts G
N=1 Meas. Inv. of indicators w.r.t. external variable x x f(yi|a*) = f(yi|a*,xi) z z a a y y y y y y e e e e e e
N=1 Meas. Inv. of indicators w.r.t. external variable x two indicators biased w.r.t. x. x x z z z z a a a a y y y y y y y y y y y y e e e e e e e e e e e e B S H Z (bias with respect to x) f(yi|a*) ≠ f(yi|a*,xi) G
x x z z B B z z a a a a y y y y y y y y y y y y e e e e e e e e e e e e f(yi|a*) = f(yi|a*,subjecti) Are the indicators measurement invariant w.r.t. subject (e.g., N=2)? d is invariant (intercepts equal), B zero in subject 1, B free in subject 2 X could equal 1.
f(yi|a*) = f(yi|a*,xi) f(yi|a*) = f(yi|a*,subjecti) Definition of measurement invariance in N=1 or N=2. + Interpretation as an intra-individual causal model Relationship with inter-individual causal model Issue of power: simulation? exact simulation? is N=100, T=1 relevant to N=1, T=100. Application (real data)
T=50 Ny=4 N=250 ML parameter estimates R11 0.51000 R22 0.36000 R33 0.51000 R44 0.36000 D1 0.00000 D2 0.00000 D3 0.00000 D4 0.00000 H 0.00000 Q 1.00000 S21 0.80000 S31 0.70000 S41 0.80000 ML parameter estimates 0.50998 (.51) 0.35997 (.36) 0.50994 (.51) 0.36001 (.36) -0.00153 (.0) -0.00175 (.0) -0.00153 (.0) -0.00175 (.0) 0.79994 (.80) 0.37097 (.36) 0.79994 (.8) 0.69997 (.7) 0.79992 (.8)
Good points: N=1, N=few, N=many Multigroup, where group is N=1 or N>1 No limitation on length of timeseries T Can handle N=few T=intermediate (a niche!) Missing data no problem (under assumptions) Model quite flexible Freely available (FORTRAN 77 code) Easy-ish to use Bad points: Stationarity (cov structure) ML fixed effect only (no random effects) Continuous indicators, conditional normality Easy-ish to use
Estimation: Maximum Likelihood in the Kalman Filter (prediction error decomp.) Documentation: mkfm.doc (manual with examples: DFA, ARMA, includes FORTAN source code) j_adolf.doc (more examples incl meas. inv.) some technical doc (online; Ellen Hamaker) My main reference: A.C. Harvey (1996). Forecasting, structural time series models and the Kalman Filter. Cambridge: Cambridge Univ. Press. Other good references: Hamilton, Kim & Nelson. One or two articles using MKFM: Ellen Hamaker (UU).
To use: 1) Organize data input (manual) 2) Write input script (manual) 3) Run analysis in DOS window mkfm6-1 < inputfile > outputfile
title example simulated nm=1 se=yes mo=1 ny=4 ne=1 nx=1 df=ts1mi rf=no ns=1 mi=-999 B=1 S=1 R=1 H=1 Q=1 d=1 c=0 Z=0 P=1 G=1 R fi di 0 0 0 0 R fr di 1 2 3 4 G fi di 1 G fr di 0 d fr 11 12 13 14 d fi 0 0 0 0 H fi 0 H fr 21 Q fi 1 Q fr 31 Input #1: Model specification S fi 1 0 0 0 S fr 0 41 42 43 B fi 0 B fr 50 P fi 100 P fr 0 st ... lb ... ub ...
Input part #2: the data file data file: TS1MI 250 0 4.621209 5.754381 6.855362 7.026104 0 5.826427 6.732414 6.818705 5.448525 0 4.840544 4.112223 6.653377 7.070116 0 6.197258 7.596196 7.257844 3.101740 1 ..........
max nm= 5 nt=5000 ns= 10 ny=30 nx= 5 ne=30 npar=400 Read from input file title example simulated nm=1 se=yes mo=1 ny=4 ne=1 nx=1 df=ts1mi rf=no ns=1 mi=-999 B=1 S=1 R=1 H=1 Q=1 d=1 c=0 Z=0 P=1 G=1 =================== MKFv1 April 2010 =================== title example simulated Model 1 of 1 S fr parameters (nonzero) 0 11 12 13 R fr parameters (nonzero) - diagonal 1 2 3 4 H fr parameters (nonzero) 9 Q fr parameters (nonzero) 10 d fr parameters (nonzero) 5 6 7 8 B fr parameters (nonzero) 14 Output part#1: Model specification
Output part#2: Summary stats + parameter estimates, st errs, tvals DATA SUMMARY MODEL 1 of 1 NY= 4 NX= 1 NE= 1 Ncases= 1 START= 1 END= 1 CASE 1 T= 250 N of T missing= 0 datafile ts1mi State_0 0.00 var 1 2 3 4 %miss 0.2720 0.2640 0.2520 0.2880 mean 5.52 5.41 5.49 5.40 var 1.83 1.67 1.39 0.94 std 1.35 1.29 1.18 0.97 min 1.32 2.01 2.23 3.22 max 8.82 9.75 9.33 8.01 Number of fixed regressors 1 ML parameter estimates nr 1 0.55179 g 0.000026 se 0.0851 t 6.48 nr 2 0.51076 g 0.000012 se 0.0748 t 6.83 nr 3 0.68355 g 0.000048 se 0.0830 t 8.23 nr 4 0.44029 g 0.000038 se 0.0562 t 7.83 nr 5 4.47651 g 0.000020 se 0.2983 t 15.01 nr 6 4.47448 g 0.000051 se 0.2748 t 16.28 nr 7 4.73732 g -0.000049 se 0.2244 t 21.11 nr 8 4.71898 g -0.000096 se 0.1928 t 24.47 nr 9 0.72616 g -0.000106 se 0.0506 t 14.36 nr 10 0.48247 g -0.000055 se 0.0932 t 5.18 nr 11 0.92335 g 0.000051 se 0.0738 t 12.52 nr 12 0.71907 g -0.000143 se 0.0710 t 10.13 nr 13 0.62061 g -0.000031 se 0.0609 t 10.19 nr 14 0.95749 g -0.000021 se 0.1301 t 7.36 Logl -513.914 -2xLogL 1027.828 Inform(NPSOL) 0
title example simulated Model 1 of 1 S parameters 1.000 0.923 0.719 0.621 R parameters - diagonal 0.552 0.511 0.684 0.440 H parameters 0.726 Q parameters 0.482 P parameters 100.000 d parameters 4.477 4.474 4.737 4.719 G parameters - diagonal 1.000 B parameters 0.957 P(t|t) error cov 0.233 Output part#3: parameter estimates in parameter matrices