Download

1 / 93
960 likes | 1.29k Views
Hands-on Data Science and OSS. Driving Business Value with Open Source and Data Science Kevin Crocker, @_ K_C_Pivotal # datascience , # oscon Data Science Education Lead Pivotal Software Inc. @pivotal. Everything oscon2014. VM info. Everything is ‘ oscon2014 ’

E N D
Hands-on Data Science and OSS • Driving Business Value with • Open Source and Data Science • Kevin Crocker, @_K_C_Pivotal • #datascience, #oscon • Data Science Education Lead • Pivotal Software Inc. @pivotal
Everything • oscon2014
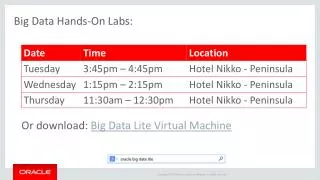
VM info • Everything is ‘oscon2014’ • User:password –> oscon2014:oscon2014 • PostgreSQL 9.2.8 dbname -> oscon2014 • Root password -> oscon2014 • Installed software: postgresql 9.2.8, R, MADlib, pl/pythonu, pl/pgpsl, anaconda ( /home/oscon2014/anaconda), pgadmin3, Rstudio, pyMADlib, and more to come in v1.1
Objective of Data Science DRIVE AUTOMATED LOW LATENCY ACTIONS IN RESPONSE TO EVENTS OF INTEREST
What Matters: Apps. Data. Analytics. Apps power businesses, and those apps generate data Analytic insights from that data drive new app functionality, which in-turn drives new data The faster you can move around that cycle, the faster you learn, innovate & pull away from the competition
What Matters: OSS at the core Apps power businesses, and those apps generate data Analytic insights from that data drive new app functionality, which in-turn drives new data The faster you can move around that cycle, the faster you learn, innovate & pull away from the competition
End Game: Drive Business Value with OSS • interesting problems that can’t easily be solved with current technology • Use (find) the right tool for the job • If they don’t exist, create them • Prefer OSS if it fits the need • Drive business value through distributed, MPP analytics • Operationalization (O16n) of your Analytics • Create interesting solutions that drive business value
PIVOTAL DATA SCIENCE TOOLKIT • Visualization • python-matplotlib • python-networkx • D3.js • Tableau • GraphViz • Gephi • R (ggplot2, lattice, shiny) • Excel Run Code Find Data 3 1 Implement Algorithms 5 • Interfaces • pgAdminIII • psql • psycopg2 • Terminal • Cygwin • Putty • Winscp • Platforms • Pivotal Greenplum DB • Pivotal HD • Hadoop (other) • SAS HPA • AWS • In-Database • SQL • PL/Python • PL/Java • PL/R • PL/pgSQL • Hadoop • HAWQ • Pig • Hive • Java • Libraries • MADlib • Java • Mahout • R • (Too many to list!) • Text • OpenNLP • NLTK • GPText • C++ • opencv • Python • NumPy • SciPy • scikit-learn • Pandas • Programs • Alpine Miner • Rstudio • MATLAB • SAS • Stata • Sharing Tools • Chorus • Confluence • Socialcast • Github • Google Drive & Hangouts Write Code for Big Data Write Code 4 2 Collaborate Show Results 7 6 • Editing Tools • Vi/Vim • Emacs • Smultron • TextWrangler • Eclipse • Notepad++ • IPython • Sublime • Languages • SQL • Bash scripting • C • C++ • C# • Java • Python • R A large and varied tool box!
Toolkit? This image was created by Swami Chandresekaran, Enterprise Architect, IBM. He has a great article about what it takes to be a Data Scientist: Road Map to Data Scientist http://nirvacana.com/thoughts/becoming-a-data-scientist/
Open Source At Pivotal • Pivotal has a lot of open source projects (and people) involved in Open Source • PostgreSQL, Apache Hadoop (4) • MADlib (16), PivotalR (2), pyMADlib (4), Pandas via SQL (3), • Spring (56), Groovy (3), Grails (3) • Apache Tomcat (2) and HTTP Server (1) • Redis (1) • Rabbit MQ (4) • Cloud Foundry (90) • Open Chorus • We use a combination of our commercial software and OSS to drive business value through Data Science
Motivation • Our story starts with SQL – so naturally we try to use SQL for everything! Everything? • SQL is great for many things, but it’s not nearly enough • Straightforward way to query data • Not necessarily designed for data science • Data Scientists know otherlanguages – R, Python, …
Our challenge • MADlib • Open source • Extremely powerful/scalable • Growing algorithm breadth • SQL • R / Python • Open source • Memory limited • High algorithm breadth • Language/interface purpose-designed for data science • Want to leverage both the performance benefits of MADlib and the usability of languages like R and Python
How Pivotal Data Scientists Select Which Tool to Use Optimized for algorithm performance, scalability, & code overhead
Pivotal, MADlib, R, and Python • Pivotal & MADlib & R Interoperability • PivotalR • PL/R • Pivotal & MADlib & Python Interoperability • pyMADlib • PL/Python
MADlib • MAD stands for: • lib stands for library of: • advanced (mathematical, statistical, machine learning) • parallel & scalable • in-database functions • Mission: to foster widespread development of scalable analytic skills, by harnessing efforts from commercial practice, academic research, and open-source development
Developed as a partnership with multiple universities University of California-Berkeley University of Wisconsin-Madison University of Florida Compatibile with Postgres, Greenplum Database, and Hadoop via HAWQ Designed for Data Scientists to provide Scalable, Robust Analytics capabilities for their business problems. Homepage: http://madlib.net Documentation: http://doc.madlib.net Source: https://github.com/madlib Forum: http://groups.google.com/group/madlib-user-forum MADlib: A Community Project Open Source: BSD License Community
MADlib: Architecture Core Methods Linear Systems Generalized Linear Models Machine Learning Algorithms Matrix Factorization Support Modules Probability Functions Random Sampling Array Operations Sparse Vectors C++ Database Abstraction Layer Data Type Mapping Linear Algebra Exception Handling Memory Management Logging and Reporting Boost Support Database Platform Layer User Defined Functions User Defined Aggregates User Defined Types OLAP Window Functions User Defined Operators OLAP Grouping Sets
MADlib: Diverse User Experience SQL Python psql> madlib.linregr_train('abalone', 'abalone_linregr', 'rings', 'array[1,diameter,height]'); psql> select coef, r2 from abalone_linregr; -[ RECORD 1 ]---------------------------------------------- coef | {2.39392531944631,11.7085575219689,19.8117069108094} r2 | 0.350379630701758 from pymadlib.pymadlib import * conn = DBConnect() mdl = LinearRegression(conn) lreg.train(input_table, indepvars, depvar) cursor = lreg.predict(input_table, depvar) scatterPlot(actual,predicted, dataset) R Open Chorus
MADlib In-DatabaseFunctions Descriptive Statistics Support Modules Predictive Modeling Library • Machine Learning Algorithms • Principal Component Analysis (PCA) • Association Rules (Affinity Analysis, Market Basket) • Topic Modeling (Parallel LDA) • Decision Trees • Ensemble Learners (Random Forests) • Support Vector Machines • Conditional Random Field (CRF) • Clustering (K-means) • Cross Validation • Generalized Linear Models • Linear Regression • Logistic Regression • Multinomial Logistic Regression • Cox Proportional Hazards • Regression • Elastic Net Regularization • Sandwich Estimators (Huber white, clustered, marginal effects) Array Operations Sparse Vectors Random Sampling Probability Functions • Matrix Factoriization • Single Value Decomposition (SVD) • Low-Rank • Linear Systems • Sparse and Dense Solvers • Sketch-based Estimators • CountMin (Cormode-Muthukrishnan) • FM (Flajolet-Martin) • MFV (Most Frequent Values) • Correlation • Summary
Calling MADlib Functions: Fast Training, Scoring Table containing training data MADlib model function • MADlib allows users to easily and create models without moving data out of the systems • Model generation • Model validation • Scoring (evaluation of) new data • All the data can be used in one model • Built-in functionality to create of multiple smaller models (e.g. regression/classification grouped by feature) • Open-source lets you tweak and extend methods, or build your own Table in which to save results SELECT madlib.linregr_train( 'houses’, 'houses_linregr’, 'price’, 'ARRAY[1, tax, bath, size]’, ‘bedroom’); Column containing dependent variable Features included in the model Create multiple output models (one for each value of bedroom)
Calling MADlib Functions: Fast Training, Scoring • MADlib allows users to easily and create models without moving data out of the systems • Model generation • Model validation • Scoring (evaluation of) new data • All the data can be used in one model • Built-in functionality to create of multiple smaller models (e.g. regression/classification grouped by feature) • Open-source lets you tweak and extend methods, or build your own SELECT madlib.linregr_train( 'houses’, 'houses_linregr’, 'price’, 'ARRAY[1, tax, bath, size]’); MADlib model scoring function SELECT houses.*, madlib.linregr_predict(ARRAY[1,tax,bath,size], m.coef )as predict FROM houses, houses_linregr m; Table with data to be scored Table containing model
K-Means Clustering Clustering refers to the problem of partitioning a set of objects according to some problem-dependent measure of similarity. In the k-means variant, given n points x1,…,xn∈ℝd, the goal is to position k centroids c1,…,ck∈ℝd so that the sum of distances between each point and its closest centroid is minimized. Each centroid represents a cluster that consists of all points to which this centroid is closest. So, we are trying to find the centroids which minimize the total distance between all the points and the centroids.
K-means Clustering Example Use Cases: Which Blogs are Spam Blogs? Given a user’s preferences, which other blog might she/he enjoy? What are our customers saying about us?
What are our customers saying about us? • Discern trends and categories on-line conversations? • Search for relevant blogs • ‘Fingerprinting’ based on word frequencies • Similarity Measure • Identify ‘clusters’ of documents
What are our customers saying about us? • Method • Construct document histograms • Transform histograms into document “fingerprints” • Use clustering techniques to discover similar documents.
What are our customers saying about us? Constructing document histograms • Parsing & extract html files • Using natural language processing for tokenization and stemming • Cleansing inconsistencies • Transforming unstructured data into structured data
What are our customers saying about us? “Fingerprinting” • Term frequency of words within a document vs. frequency that those words occur in all documents • Term frequency-inverse document frequency (tf-idf weight) • Easily calculated based on formulas over the document histograms. • The result is a vector in n-dim. Euclidean space.
K-Means Clustering – Training Function The k-means algorithm can be invoked in four ways, depending on the source of the initial set of centroids: • Use the random centroid seeding method. • Use the kmeans++ centroid seeding method. • Supply an initial centroid set in a relation identified by the rel_initial_centroids argument. • Provide an initial centroid set as an array expression in the initial_centroids argument.
Random Centroid seeding method kmeans_random( rel_source, expr_point, k, fn_dist, agg_centroid, max_num_iterations, min_frac_reassigned )
Kmeans++ centroid seeding method kmeanspp( rel_source, expr_point, k, fn_dist, agg_centroid, max_num_iterations, min_frac_reassigned )
Initial Centroid set in a relation kmeans( rel_source, expr_point, rel_initial_centroids, -- this is the relation expr_centroid, fn_dist, agg_centroid, max_num_iterations, min_frac_reassigned )
Initial centroid as an array kmeans( rel_source, expr_point, initial_centroids, -- this is the array fn_dist, agg_centroid, max_num_iterations, min_frac_reassigned )
K-Means Clustering – Cluster Assignment • After training, the cluster assignment for each data point can be computed with the help of the following function: closest_column( m, x )
Assessing the quality of the clustering A popular method to assess the quality of the clustering is the silhouette coefficient, a simplified version of which is provided as part of the k-means module. Note that for large data sets, this computation is expensive. The silhouette function has the following syntax: simple_silhouette( rel_source, expr_point, centroids, fn_dist )
What are our customers saying about us? • innovation • leader • design • bug • installation • download • speed • graphics • improvement
Pivotal, MADlib, R, and Python • Pivotal & MADlib & R Interoperability • PivotalR • PL/R • Pivotal & MADlib & Python Interoperability • pyMADlib • PL/Python