Download

1 / 26
270 likes | 488 Views
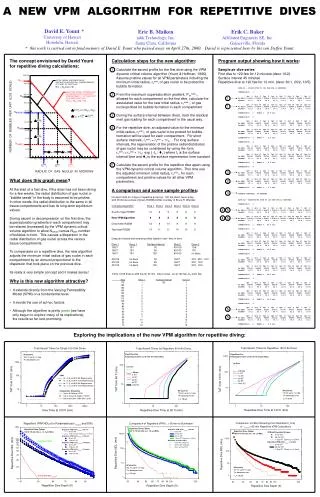
A new speaker-intrinsic vowel normalisation algorithm for sociophonetics. Anne Fabricius*, Dominic Watt † & Jillian Oddie † *Roskilde Universitetscenter † University of York. 0. Overview. background purpose of the present study data and methods results discussion

E N D
A new speaker-intrinsic vowel normalisation algorithm for sociophonetics Anne Fabricius*, Dominic Watt† & Jillian Oddie† *Roskilde Universitetscenter †University of York
0. Overview • background • purpose of the present study • data and methods • results • discussion • directions for future work
1. Background Why normalise? • to eliminate variation caused by physiological differences among speakers • to preserve sociolinguistic/dialectal/cross-linguistic differences in vowel quality • to preserve phonological distinctions among vowels • to model the cognitive processes that allow human listeners to normalize vowels uttered by different speakers Thomas & Kendall (2007), quoting Disner (1980) and Thomas (2002)
1. Background Why normalise? • to eliminate variation caused by physiological differences among speakers • to preserve sociolinguistic/dialectal/cross-linguistic differences in vowel quality • to preserve phonological distinctions among vowels • to model the cognitive processes that allow human listeners to normalise vowels uttered by different speakers Thomas & Kendall (2007), quoting Disner (1980) and Thomas (2002)
1. Background • Watt & Fabricius (2002) method • developed on basis of interest in variation and change in British English vowel systems (e.g. Watt & Tillotson 2001) • acknowledges that even speakers of a single accent may have quite differently configured vowel systems • seeks estimate of F1 and F2 maxima and minima for each speaker in sample • centroid S (after Koopmans-van Beinum 1980) derived from these corner points • all formant measurements then expressed relative to S
F2 (Hz) min F2(= min F1) min F1,max F2 u i S F1 (Hz) a max F1 1. Background
1. Background • Already compared with Bark (Traunmüller 1997) in Watt & Fabricius (2002) • RP Data from Deterding 1997 (one male, one female speaker) • Evaluated S-normalised data relative to raw Hz values and Bark values on following parameters: • Area agreement • Overlap of vowel spaces • W&F performed better than Bark and Hertz
1. Background • Plethora of normalisation methods in the literature • typology of methods (Adank 2003) • Uses intrinsic vs. extrinsic as methodological distinction • speaker • vowel • formant • Like Adank’s most successful methods, W&F method is speaker intrinsic, vowel extrinsic, formant intrinsic
2. Purpose of the present study • Road-test the W&F method further relative to other typologically similar normalisation methods • Carry out comparisons with Lobanov (z-score) and Nearey (log-mean speaker intrinsic) • Examine larger data sets, more speakers, two varieties of British English • Refine and automate comparison procedures aimed at matching sociophonetic priorities
3. Methods • RP data from Hawkins & Midgley (2005) and Moreiras (2006); 20 speakers 20s and 60s • Aberdeen data collected by DW and JO • 16 speakers (8 per accent, range of ages) • All wordlist data • Comparisons carried out within groups of 4: usually 2 ♂ 2 ♀ • i.e. 6 comparisons per group x 4 data types (Hz, Lobanov, Nearey, W&F) = 24 x 4 = 96 comparisons • Normalised values derived using NORM (Thomas & Kendall 2007)
3. Methods • 2 measures of mapping improvement: • area agreement index (AAI = ratio of speaker 1 to speaker 2 vowel space polygons; spkr 1 male unless female pairs) • coextensiveness index (CI = percentage of the two speaker´s polygons that overlap) • Polygons defined by • RP : FLEECE, KIT, DRESS, TRAP, START, LOT, THOUGHT, GOOSE • Aberdeen: FLEECE, FACE, DRESS, TRAP, START, THOUGHT, GOOSE
3. Methods Hz Lobanov Nearey W&F
3. Methods • Polygon and overlap areas calculated from xy scatter plots using Image J • AAI, CI calculated for each talker pair on basis of area data • differences between normalised data types and Hz data calculated
4. Results 1: older RP Area Agreement improvement relative to Hertz
4. Results 1: older RP Coextensiveness improvement relative to Hertz
4. Results 2: Aberdeen set 1 Area Agreement improvement relative to Hertz
4. Results 2: Aberdeen set 1 Coextensiveness improvement relative to Hertz
Preliminary conclusion • Lobanov method generally works most successfully for evaluative criteria chosen for this study (cf. Adank´s conclusions), but not in all cases • W&F performs better than Nearey in some, but not all, cases • Large amount of variability in results for speaker pairs; more data needed
4. Results 3: RP speakers • A second measure of area agreement on sample of 20 speakers • Comparisons between 5 male and 5 female RP speakers, older and younger groups (Hawkins and Midgley 2005, Moreiras 2006) • Calculated ratio female/male vowel space polygon area for all male-female pairs only (no same sex comparisons) • 25 comparisons, 4 data types (Hz, Lobanov, Nearey, W&F) • Analysed using one-way ANOVA plus Tukey-Kramer Minimum Significant Difference tests
4. Results 3: RP speakers • Analysis of variance significant among groups for both older and younger speaker sets • Tukey-Kramer MSD tests results: • For older speaker group: W&F and Lobanov, but not Nearey, perform significantly better than Hertz • For younger speakers, all three speaker-intrinsic algorithms perform better than Hertz but no differences among them. • On this set of data and for this comparison, W&F performs just as well as Lobanov
Normalisation is worth carrying out even on carefully elicited ‘lab speech’ data from same sex pairs Findings support an approach where values are expressed relative to formant ranges Rather than working from a priori assumptions about how vowel systems are configured For the tasks we set it, however, W&F does not do as well as a statistical approach based on z-scores 5. Discussion
6. Directions for future work • Remains to do: Testing performance of normalisation algorithms against Hertz according to distances and angles between corresponding points on perimeter of vowel spaces • Exclusion of F2 of [a] (or other F1 maximum) in calculation of S coordinates might avoid bias of F2 (which perhaps leads to skewing) if F1 maximum is not central (cf Thomas and Kendall 2007) • Carrying out this paper’s test procedures on the complete data set
References Adank, P. 2003. Vowel Normalization: A perceptual-acoustic study of Dutch Vowels. Ph.D. thesis, Katholieke Universiteit Nijmegen. Deterding, D. 1997.The Formants of Monophthong vowels in Standard Southern British English Pronunciation. JIPA. 27: 47-55. Disner, S. 1980. Evaluation of vowel normalization procedures. JASA. 67:253:61. Hawkins, S & Midgley, J. 2005. Formant frequencies of RP monophthongsin four age groups of speakers. JIPA. 30: 63-78. Koopmans-van Beinum, F. (1980). Vowel contrast reduction: an acoustical and perceptual study of Dutch vowels in various speech conditions. PhD thesis, University of Amsterdam. Lobanov, B.M. (1971). Classification of Russian vowels spoken by different speakers. JASA 49(2B): 606-8. Moreiras, C. 2006. An acoustic study of vowel change in female adult speakers of RP. Unpublished undergraduate dissertation, University College London. Nearey, T. 1977.Phonetic feature systems for vowels. Dissertation, University of Alberta. Thomas, E. 2002. Instrumental Phonetics. In J.K. Chambers, Peter Trudgill and Natalie Schilling-Estes. The Handbook of Language Variation and Change. Oxford, UK/Malsen, MA: Blackwell. 168-200. Thomas, E. & Kendall, T. 2007. NORM: the Vowel Normalization and Plotting Suite. URL: <http://ncslaap.lib.ncsu.edu/tools/norm/index.php> Traunmüller, H. 1997. Auditory scales of frequency representation. Online at http://www.ling.su.se/staff/hartmut/bark.htm Watt, D. & Fabricius, A. 2002. Evaluation of a technique for improving the mapping of multiple speakers’ vowel spaces in the F1 ~F2 plane. Leeds Working Papers in Linguistics and Phonetics 9: 159-73. Watt, D. and Tillotson, J. 2001. A spectrographic analysis of vowel fronting in Bradford English. English World-Wide. 22(2):269-302. Acknowledgements Thanks to Caroline Moreiras and Bronwen Evans for allowing us access to the female RP data, to Vic Watt for help with the Aberdeen data, and to Bernhard Fabricius for mathematical assistance.
A new speaker-intrinsic vowel normalisation algorithm for sociophonetics Anne Fabricius*, Dominic Watt† & Jillian Oddie† *Roskilde Universitetscenter †University of York