Download

1 / 19
190 likes | 377 Views
Paragon: Collaborative Speculative Loop Execution on GPU and CPU. Mehrzad Samadi 1 Amir Hormati 2 Janghaeng Lee 1 and Scott Mahlke 1. 1 University of Michigan - Ann Arbor 2 Microsoft Research, Microsoft. Amdahl’s Law. GPGPU may have <100x speedup but. 50%. 50%.

E N D
Paragon: Collaborative Speculative Loop Execution on GPU and CPU MehrzadSamadi1 Amir Hormati2 Janghaeng Lee1 and Scott Mahlke1 1University of Michigan - Ann Arbor 2Microsoft Research, Microsoft
Amdahl’s Law • GPGPU may have <100x speedup but... 50% 50% NO GPU utilization GPU Executable Even 1000x here does NOT bring more than 2x in overall NO GPU utilization Execution Time
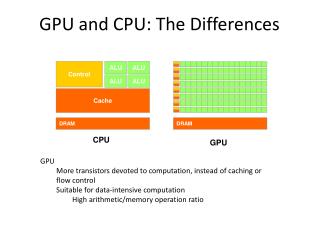
General Purpose Computing on GPU • Limitation of • Massive Data-Parallelism • Linear array access • NO Indirect array access • NO Pointers • Leaves GPUs underutilized • GPUs are not so much generalized GPU Executable How can GPUs be more GENERAL?
Motivation – More Generalization • Reduce Sections • Non-Linear array access • Indirect array access • Array access through pointers • Difficult for programmers to verify • Loop-Carried Dependencies NO GPU utilization for(y=0; y<ny; y++) for(x=0; x<nx; x++){xr = x %squaresize[XUP];yr = y %squaresize[YUP];i = xr + yr;lattice[i].x = x;lattice[i].y = y; } for(i=1; i<m; i++) for(j=iaL[i]; j<iaL[i+1]-1; j++) x[i] = x[i] - aL[j] * x[jaL[j]]; for(int i=0; i<n; i++){ *c = *a + *b; a++; b++; c++; }
Motivation – More Generalization • Reduce Sections • Non-Linear array access • Indirect array access • Array access through pointers • Difficult for programmers to verify • Loop-Carried Dependencies NO GPU utilization
Paragon Execution Loop 2 Sequential Loop 1 Loop 3 Sequential Sequential DO-ALL Possibly-Parallel DO-ALL Sequential CPU Sequential Sequential L2 CPU L3 L1 L2 GPU Conflict Check
Paragon Execution with Conflict Loop 2 Sequential Loop 1 Loop 3 Sequential Sequential DO-ALL Possibly-Parallel DO-ALL Sequential CPU Sequential Sequential L2 CPU L1 L2 L3 GPU Conflict
Paragon Process Flow Input: Sequential Code Offline Compilation Runtime Kernel Management Loop Classification Profiling Conflict Management Unit Instrumentation Executionwithout Profiling CUDA + pThread
Offline Compilation • Loop classification • Sequential Loops • Dependence determined at compile-time • Assign to CPU statically • DO-ALL Loops • Assign to GPU statically • Possible DO-ALL Loops • Dependence can be determined at RUNTIME
Runtime Profiling • Spawns thread on CPU • Sequential execution thread • Monitoring thread • Keeps track of memory foot print • Marks loop • Sequential • If many conflicts • Parallelizable • If no/few conflicts Assigned to CPU and GPU
Conflict Detection - Logging • Lazy conflict detection • Allocate memory when executing kernel • “write-set” for store • “read-set” for load intC_wr_log[sizeof_C]; boolC_rd_log[sizeof_C]; for (i = 0; i < N; i++){ idx = I[i]; C[idx] = A[idx] + B[idx]; } for (i = tid; i < N; i += ThreadCnt){ idx = I[i]; C[idx] = A[idx] + B[idx]; } AtomicInc(C_wr_log[idx]);
Conflict Detection - Checking • Done in parallel following kernel • Conflict if • Address written more than once • Address read and written at least once C_rd_log C_wr_log Thread 1 [0] [0] F 0 OK Thread 2 [1] [1] F 0 Thread 3 [2] [2] F 1 Thread 4 [3] [3] F 0 ... ... ... Conflict F T 0 Thread N F T 2 1 [N] [N]
Experimental Setup • CPU • Intel Core i7 • GPU • NVIDIA GTX 560 with 2GB DDR5 • Benchmark • Loops with pointers • FDTD, Siedel, Jacobi2d, GEMM, TMV • Indirect/Non-Linear access • Saxpy, House, Ipvec, Ger, Gemver, SOR, FWD
Conclusion • Paragon improves performance • More GPU Utilization • Speculatively run possibly-parallel loops on GPU • No performance penalty on mis-speculation • Letting CPU run sequentially at the same time • Conflict checking is done in GPU