Download

1 / 28
280 likes | 446 Views
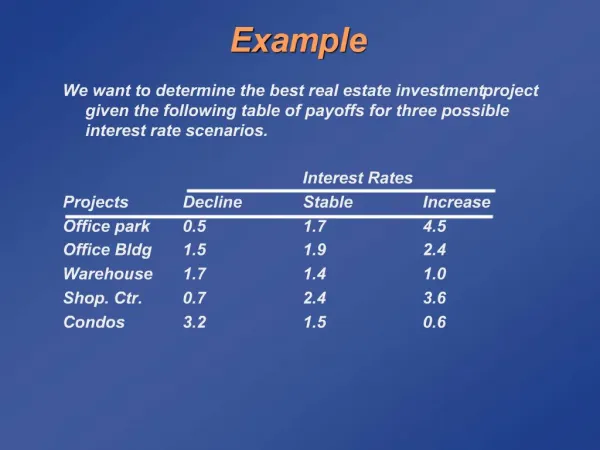
Example. 16,000 documents 100 topic Picked those with large p(w|z). New document?. Given a new document, compute and words allocated to each topic approximates p ( z n | w ) See cases where these values are relatively large 4 topics found. Unseen document (contd.).

E N D
Example • 16,000 documents • 100 topic • Picked those with large p(w|z)
New document? • Given a new document, compute and • words allocated to each topic • approximates p(zn|w) • See cases where these values are relatively large • 4 topics found
Unseen document (contd.) • Bag of words - William Randolph Hearst Foundation assigned to different topics
Applications and empirical results • Document modeling • Document classification • Collaborative filtering
Document modeling • Task: density estimation, high likelihood to unseen document • Measure of goodness: perplexity • Monotonically decreases in the likelihood
The experiment (contd.) • Preprocessed • stop words • appearing once • 10% held for training • Trained with the same stopping criteria
Overfitting in Mixture of unigrams • Peaked posterior in the training set • Unseen document with unseen word • Word will have very small probability • Remedy: smoothing
Overfitting in pLSI • Mixture of topics allowed • Marginalize over d to find p(w) • Restriction to having the same topic proportions as training documents • “Folding in” ignore p(z|d) parameters and refit p(z|dnew)
LDA • Documents can have different proportions of topics • No heuristics
Document classification • Generative or discriminative • Choice of features in document classification • LDA as dimensionality reduction technique • as LDA features
The experiment • Binary classification • 8000 documents, 15,818 words • True label not known • 50 topic • Trained SVM on the LDA features • Compared with SVM on all word features • LDA reduced feature space by 99.6%
LDA in document classification • Feature space reduced, performance improved • Results need further investigation • Use for feature selection
Collaborative filtering • Collection of users and movies they prefer • Trained on observed users • Task: given unobserved user and all movies preferred but one, predict the held out movie • Only users who positively rated 100 movies • Trained on 89% of data
Some quantities required… • Probability of held out movie p(w|wobs) • For mixture of unigrams and pLSI sum out topic variable • For LDA sum out topic and Dirichlet variables (quantity efficient to compute)
Further work • Other approaches for inference and parameter estimation • Embedded in another model • Other types of data • Partial exchangeability
Example – Visual words • Document = image • Words = image features: bars, circles • Topics = face, airplane • Bag of words = no spatial relationship between objects
Conclusion • Exchangeability, De Finetti Theorem • Dirichlet distribution • Generative • Bag of words • Independence assumption in Dirichlet distribution - correlated topics
Implementations • In C (by one of the authors) • http://www.cs.princeton.edu/~blei/lda-c/ • In C and Matlab • http://chasen.org/~daiti-m/dist/lda/
References • Latent Dirichlet allocation, D. Blei, A. Ng, and M. Jordan. In Journal of Machine Learning Research, 3:993-1022, 2003 • Discovering object categories in image collections. J. Sivic, B. C. Russell, A. A. Efros, A. Zisserman, W. T. Freeman. MIT AI Lab Memo AIM-2005-005, February, 2005 • Correlated topic models, David Blei and John Lafferty, Advances in Neural Information Processing Systems 18, 2005.