Download
1 / 11
110 likes | 186 Views
Data Input-Output Representation. 4.2. Input. Output. Raw Data. Final Output. Transf. NN. Transf. Background ( Ref: Handbook of Neural Computation )

E N D
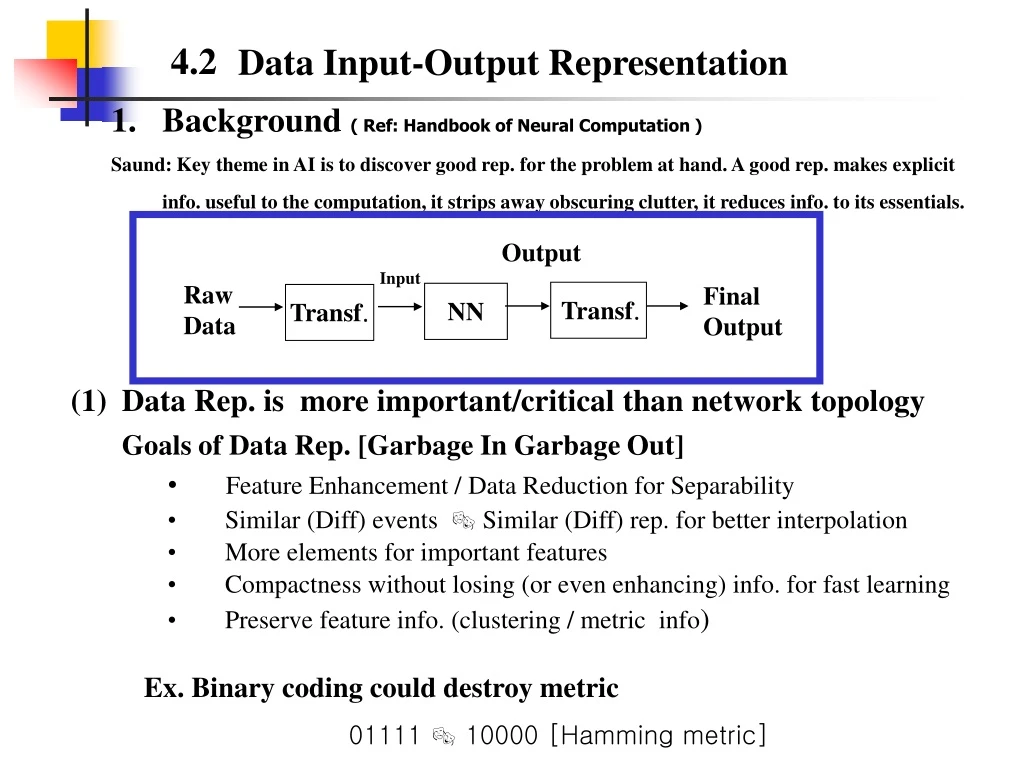
Data Input-Output Representation 4.2 Input Output Raw Data Final Output Transf. NN Transf. • Background ( Ref: Handbook of Neural Computation ) • Saund: Key theme in AI is to discover good rep. for the problem at hand. A good rep. makes explicit info. useful to the computation, it strips away obscuring clutter, it reduces info. to its essentials. • DataRep. is more important/critical than network topology • Goals of Data Rep. [Garbage In Garbage Out] • Feature Enhancement / Data Reduction for Separability • Similar (Diff) events Similar (Diff) rep. for better interpolation • More elements for important features • Compactness without losing (or even enhancing) info. for fast learning • Preserve feature info. (clustering / metric info) Ex. Binary coding could destroy metric 01111 10000 [Hamming metric]
Ex. Character Recognition Raw data = 5 64bit binary vectors. Representation ① raw data ② any code for five characters ③ shape features : horizontal and vertical spars, their ratio, relative positions of the spars Other extreme: Wasserman : raw data may be more useful in cases where essential features are unknown. NN can discover features in hidden neurons.
2. Data Preprocessing techniques Data sets are plagued by Noise, Bias, Large variations in dynamic range . . . (1) Normalize Remove large dynamic variances over one or more dimensions in data Ex. ① Normalize gray scale image invariant to light condition ② Normalize speech signal invariant to absolute volume level ③ Normalize with respect to position and size - Character recognition
① • One Way to embed magnitude ( l ) info. : • Normalize • ② Row Norm. (2-D) : for each row, divide by the mean value • ③ Column Norm. (2-D) (2) Nomalization Algorithms : (3) Principal Component Analysis – Dim. Reduction
3. Case Study : Face Recognition (profile) • Data Reduction • 416 x 320 16x2 23 (Discard High freq. components) • (= 133,120 pixels) ① Efficient tech. to extract high interest features. ② Method for data reduction with minimal info. loss ③ DCT applied to reduced vector descriptions enhances info. content, provides invariance to small change and increased separability.
4. Actual Coding Schemes (1) (2) Local R O Y G B I V Distributed C2 C1 C0 1 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 1 In Local representation, each node may be [0 1] [-1 1] or even continuous when more than one node can be active to indicate presence of two or more features. (3) Coarse Distributed Wider overlapping receptive fields 36 nodes 27 nodes
Students’ Questions from 2005: While DCT in facial image processing helps data reduction, does it also help face recognition ? Since Human faces are all alike, its Fourier transform will also be similar. Spatial features will be more relevant to recognition. Normalization or Coding will reduce data or help classification. But, isn’t the process going to delay the overall learning time ? Coarse distributed coding will reduce the total number of nodes. However, when a single node is represented in overlapped fashion, isn’t the additional info. needed such as the overlap position, etc. ?
When an NN technique is used for character or speech recognition, how does its performance compare with non-NN approaches ? NN can be applied to many problems. Any application where NN is hard to apply to ? Is there any general measure to tell the importance of information in feature extraction ? If line search is used to find an optimal learning rate, the number of steps may decrease but I am afraid the overall processing time may increase. Can better separation for classification result via data representation ? Can the information content increase via a good data rep. ?
x >0 x>3 x>6 x>9 x>12 2 = x >0 x>3 x>6 x>9 x>12 10 = 1-3 4-6 7-9 10-12 13-15 1-3 4-6 7-9 10-12 13-15 2 = 10 = 5. Discrete Coding (1) Simple Sum (fault tolerance, but requires many nodes for large numbers) 5 = 000011111 = 110000111 = (2) Value Unit Encoding (3) Discrete Thermometer
6. Continuous Coding (1) Simple Analog • For an activation ai range of [0,1] or [-1,1], value in range [u, v] = (v - u) ai+ u • Logarithmic scale for data set with large dynamic range (2) Continuous Thermometer
(3) Proportional Coarse Coding • Pomerleau used a Gaussian Smearing function to represent steering directions in an Autonomous Land Vehicle In a Neural Network (ALVINN) • Ref. “Neural Network Perception For Mobile Robot Guidance,” • D. Pomerleau, Kluwer, 93. Slight Right Turn




















