Download

1 / 25
340 likes | 756 Views
Watermarking Relational Databases. Rakesh Agrawal and Jerry Kiernan. Why Watermark Databases. Watermark -- Intentionally introduced pattern in the data hard to occur by chance hard to find => hard to destroy (robust against malicious attack)

E N D
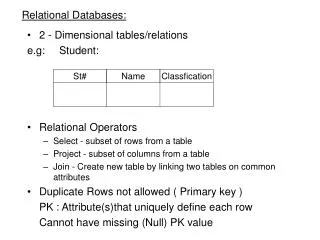
Watermarking Relational Databases Rakesh Agrawal and Jerry Kiernan
Why Watermark Databases • Watermark -- Intentionally introduced pattern in the data • hard to occur by chance • hard to find => hard to destroy (robust against malicious attack) • Increasing use of databases in applications beyond "behind-the-firewall data processing" involving data publication • Data providers require technical solutions to deter data theft and assert ownership of pirated copies
Assumption • Value of the database is significantly reduced if all of k least significant bits of an attribute are dropped or perturbed, but it is acceptable to perturb a small number of attribute values • Datasets from many data publishers satisfy the above assumption (Acceptable to tradeoff a small decrease in quality to assert ownership) • Tables of parametric specifications (mechanical, electrical, electronic, chemical, etc.), surveys (geological, climatic, etc.), life sciences (e.g. gene expressions) • Historical precedence: Logarithm tables, Astronomical Ephemerides, H.P. • Inappropriate dataset: Online bank balances
Desiderata • Detectability • Using a subset of the tuples and attributes • Robustness • Updates and malicious attacks • Incremental Updatability • On tuple insert/update/delete • Imperceptibility • Hard to infer the presence of a watermark • Blind System • Detection requires neither the original data nor the watermark • Key-Based System • Algorithm is public • Security resides in the choice of secret key
Related Work • Images [BGM95,HG98,M98,DR00] • Audio [BTH96] • Text [M94] • Software [CT00]
Relational data is different from multimedia data Multimedia Object Database Relation • Consists of a large number of bits, with considerable redundancy => Watermark has a large cover to hide in. • Consists of tuples, each of which represents a separate object => Watermark needs to be spread over these separate objects. • Relative spatial/temporal positioning of various pieces of an object does not change. • Tuples of a relation constitute a set and there is no implied ordering between them • Portions of an object cannot be dropped or replaced arbitrarily without causing perceptual changes in the object. • Pirate can easily drop some tuples/attributes or substitute them with tuples/attributes from other relations Need watermarking techniques designed to take into account special characteristics of relational data
Techniques • Introduce watermarks across a fraction of the tuples in a database relation • Detect the watermark by retrieving a subset of the tuples • Use statistical hypothesis testing to locate the watermark even in the presence of updates to the data
Message Authentication Code • h = H(M), where H is a hash function and M is a message • Given M, easy to compute h • Given h, hard to compute M • Given M, hard to find M' such that H(M) = H(M') • MD5 and SHA are good choices for H • MAC is a one-way hash function which depends on a key K • We use: F(r.P) = H(K o H(K o r.P)), where r.P is the primary key of relation r, and o is concatenation
Watermarking Algorithm • Determine the attributes(s) to be watermarked, the Gap, and the LSBs • For each tuple r, compute MAC: • Establish if r doesn't fall into a gap • Select attribute to be marked • Determine bit position to contain the mark • Compute the mark's value • Update the attribute's value to reflect the watermark, if necessary
Technique Before Watermarking B2 of A1 selected for PK1 A1 A2 A3 A4 Mark = 1 PK1 011001100 110000100 100011100 110000101 PK2 101000111 010101111 111010110 100110011 PK5 Not selected because in gap PK3 110001110 100010101 000010101 101010000 PK4 111000010 010001010 010000010 111110010 PK5 110011001 010000111 100011001 110000110 After Watermarking Value not changed because Mark = 1 A1 A2 A3 A4 Value changed PK1 011001100 110000100 100011100 110000101 PK2 101000111 010101111 111010110 100110011 PK3 110001110 100010101 000010101 101010010 PK4 111000010 010000010 010000010 111110010 PK5 110011001 010000011 100011001 110000110
Without the Private Key, the Watermark is Hard to Destroy • Which tuple contains a mark • Which attribute got marked • Which bit position got marked • The expected value of a mark
Detection Algorithm • Locate suspicious data and extract sample which might contain watermark • For each tuple r, compute MAC: • If r doesn't fall into a gap, extract the mark bit value • Count the number of success and Bernoulli trials • Apply statistical analysis to establish presence of the watermark
Extensions to the Algorithm • Relations with no primary keys • Null values
Evaluation • Analysis • Experiments • Forest Cover Type dataset from UCI repository
Attacks • Bit attacks • Randomize, zero-out, bit flipping, rounding, translation • Subset attack • Select subset of tuples and attributes • Mix-and-match attack • Combine data from multiple sources • Additive attack • Insert new watermark over existing watermark • Invertibility attack • Counterfeit watermark • Benign updates
Cumulative Binomial Probability Distribution ( ) n k n-k b(k;n,p) = p (1-p) k n S b(i;n,p) B(k;n,p) = i=k
Parameters and Defaults • Number of tuples: 1 million • Number of marked attributes: 1 • Number of least significant bits: 1 • Fraction of tuples marked: 1/1000 • Significance level for hypothesis test: 0.01
Proportion of correctly marked tuples required for detectability • The proportion of correctly marked tuples needed for detectability decreases as the number of marks increases • For 1M tuples and 10% of tuples marked, that proportion < 51% • Illustrates the tolerance of the watermark to updates
Proportion of correctly marked tuples needed for decreasing alpha • The data can tolerate a large number of updates while maintaining detectability with high confidence
Excess Error in an Attack • Attacker can be forced to make orders of magnitude more errors than the owner,making his data economically much less attractive compared to that of the owner
Samples in Which the Watermark Could be Detected When the Attacker has Dropped Tuples • Watermark detected in a subset of the tuples of a watermarked relation • Selectivity gives the sample size • Each experiment repeated 100 times • Results show the percentage of trials in which the watermark could be detected
Samples in Which Watermark was Detected When the Attacker has Dropped some Attributes • Watermark detected in a subset of the attributes and tuples of a watermarked relation • Watermark spread across 10 attributes • Selectivity gives the sample size • Each experiment repeated 100 times • Results show the percentage of trials in which the watermark could be detected
Mix-and-Match Attack • Minimum fraction of tuples from the watermarked relation needed for detectability • N is the relation size • N x f = tuples from marked relation • N x (1 - f) = tuples from other relations
Summary • Provided desiderata for a system for watermarking database relations • First watermarking algorithm for database relations • No dependence on tuple ordering • Robust against attacks • Watermark can be incrementally updated • Requires neither the original relation nor the watermark for detection
Future Work • Watermarking extensions to handle non-numeric attributes • New algorithms for fingerprinting to track multiple sources of piracy