Download

1 / 80
830 likes | 1.1k Views
Classification with Decision Trees and Rules. Evgueni Smirnov. Overview. Classification Problem Decision Trees for Classification Decision Rules for Classification. Classification Task. Given:

E N D
Classification with Decision Trees and Rules Evgueni Smirnov
Overview • Classification Problem • Decision Trees for Classification • Decision Rules for Classification
Classification Task Given: • X is an instance space defined as {Xi}i ∈1..N where Xi is a discrete/continuous variable. • Y is a finite class set. • Training data D⊆X x Y. Find: • Class y∈ Y of an instance x ∈X.
Instances, Classes, Instance Spaces A class is a set of objects in a world that are unified by a reason. A reason may be a similar appearance, structure or function. friendly robots Example. The set: {children, photos, cat, diplomas} can be viewed as a class “Most important things to take out of your apartment when it catches fire”.
X Instances, Classes, Instance Spaces head = square body = round smiling = yes holding = flag color = yellow friendly robots
H M X Instances, Classes, Instance Spaces smiling = yes friendly robots head = square body = round smiling = yes holding = flag color = yellow friendly robots
H M X Classification problem
Decision Trees for Classification • Classification Problem • Definition of Decision Trees • Variable Selection: Impurity Reduction, Entropy, and Information Gain • Learning Decision Trees • Overfitting and Pruning • Handling Variables with Many Values • Handling Missing Values • Handling Large Data: Windowing
Decision Trees for Classification • A decision tree is a tree where: • Each interior node tests a variable • Each branch corresponds to a variable value • Each leaf node is labelled with a class (class node) A1 a13 a11 a12 A3 A2 c1 a32 a31 a21 a22 c1 c2 c2 c1
Decision Tree For Playing Tennis Outlook sunny overcast rainy Humidity yes Windy high normal false true no yes yes no
Classification with Decision Trees Classify(x: instance, node: variable containing a node of DT) • ifnode is a classification node then • return the class of node; • else • determine the child of node that match x. • return Classify(x, child). A1 a13 a11 a12 A3 A2 c1 a32 a31 a21 a22 c1 c2 c2 c1
Decision Tree Learning Basic Algorithm: 1. Xi the “best" decision variable for a node N. 2. Assign Xi as decision variable for the node N. 3. For each value of Xi, create new descendant of N. 4. Sort training examples to leaf nodes. 5. IF training examples perfectly classified, THEN Stop. ELSE Iterate over new leaf nodes.
Variable Quality Measures Outlook Sunny Rain Overcast ____________________________________ Outlook Temp Hum Wind Play ------------------------------------------------------- Sunny Hot High Weak No Sunny Hot High Strong No Sunny Mild High Weak No Sunny Cool Normal Weak Yes Sunny Mild Normal Strong Yes _____________________________________ Outlook Temp Hum Wind Play --------------------------------------------------------- Overcast Hot High Weak Yes Overcast Cool Normal Strong Yes _____________________________________ Outlook Temp Hum Wind Play --------------------------------------------------------- Rain Mild High Weak Yes Rain Cool Normal Weak Yes Rain Cool Normal Strong No Rain Mild Normal Weak Yes Rain Mild High Strong No
Variable Quality Measures • Let S be a sample of training instances and pj be the proportions of instances of class j (j=1,…,J) in S. • Define an impurity measure I(S) that satisfies: • I(S) is minimum only when pi=1 and pj=0 for ji (all objects are of the same class); • I(S) is maximum only when pj =1/J (there is exactly the same number of objects of all classes); • I(S) is symmetric with respect to p1,…,pJ;
| S | å = - ) xij I ( S , Xi ) I ( S ) I ( Sxij D | S | j Reduction of Impurity: Discrete Variables • The “best” variable is the variable Xi that determines a split maximizing the expected reduction of impurity: where Sxij is the subset of instances from S s.t. Xi=xij. Xi ……. Sxij Sxi2 Sxi1
Information Gain: Entropy Let S be a sample of training examples, and p+ is the proportion of positive examples in S and p- is the proportion of negative examples in S. Then: entropy measures the impurity of S: E( S) = - p+ log2 p+ – p- log2p-
Entropy Example In the Play Tennis dataset we had two target classes: yes and no Out of 14 instances, 9 classified yes, rest no
Information Gain Information Gain is the expected reduction in entropy caused by partitioning the instances from S according to a given discrete variable. Gain(S, Xi) = E(S) - where Sxij is the subset of instances from S s.t. Xi=xij. Xi ……. Sxij Sxi2 Sxi1
Example Outlook Sunny Rain Overcast ____________________________________ Outlook Temp Hum Wind Play ------------------------------------------------------- Sunny Hot High Weak No Sunny Hot High Strong No Sunny Mild High Weak No Sunny Cool Normal Weak Yes Sunny Mild Normal Strong Yes _____________________________________ Outlook Temp Hum Wind Play --------------------------------------------------------- Overcast Hot High Weak Yes Overcast Cool Normal Strong Yes _____________________________________ Outlook Temp Hum Wind Play --------------------------------------------------------- Rain Mild High Weak Yes Rain Cool Normal Weak Yes Rain Cool Normal Strong No Rain Mild Normal Weak Yes Rain Mild High Strong No Which attribute should be tested here? Gain (Ssunny , Humidity) = = .970 - (3/5) 0.0 - (2/5) 0.0 = .970 Gain (Ssunny , Temperature) = .970 - (2/5) 0.0 - (2/5) 1.0 - (1/5) 0.0 = .570 Gain (Ssunny , Wind) = .970 - (2/5) 1.0 - (3/5) .918 = .019
Temp. Play 64 Yes Temp.< 64.5 I=0.048 Temp.< 84 I=0.113 Temp.< 70.5 I=0.045 Temp.< 77.5 I=0.025 Temp.< 73.5 I=0.001 Temp.< 80.5 I=0.000 65 No Temp.< 66.5 I=0.010 68 Yes 69 Yes 70 Yes 71 No Sort 72 No 72 Yes 75 Yes 75 Yes 80 No 81 Yes 83 Yes 85 No Continuous Variables
ID3 Algorithm Informally: • Determine the variable with the highest information gain on the training set. • Use this variable as the root, create a branch for each of the values the attribute can have. • For each branch, repeat the process with subset of the training set that is classified by that branch.
Hypothesis Space Search in ID3 • The hypothesis space is the set of all decision trees defined over the given set of variables. • ID3’s hypothesis space is a compete space; i.e., the target tree is there! • ID3 performs a simple-to-complex, hill climbing search through this space.
Hypothesis Space Search in ID3 • The evaluation function is the information gain. • ID3 maintains only a single current decision tree. • ID3 performs no backtracking in its search. • ID3 uses all training instances at each step of the search.
A2<0.33 ? yes no good A1<0.91 ? A2<0.91 ? A1<0.23 ? 1 good bad A2<0.75 ? A2<0.49 ? A2 good bad bad A2<0.65 ? 0 0 1 A1 bad good Decision Trees are Non-linear Classifiers
Posterior Class Probabilities Outlook Sunny Overcast Rainy no: 2 pos and 3 neg Ppos = 0.4, Pneg = 0.6 no: 2 pos and 0 neg Ppos = 1.0, Pneg = 0.0 Windy False True no: 0 pos and 2 neg Ppos = 0.0, Pneg = 1.0 no: 3 pos and 0 neg Ppos = 1.0, Pneg = 0.0
Overfitting Definition: Given a hypothesis space H, a hypothesis h H is said to overfit the training data if there exists some hypothesis h’ H, such that h has smaller error that h’ over the training instances, but h’ has a smaller error that h over the entire distribution of instances.
Reasons for Overfitting Outlook sunny overcast rainy Humidity yes Windy high normal false true no yes yes no • Noisy training instances. Consider an noisy training example: • Outlook = Sunny; Temp = Hot; Humidity = Normal; Wind = True; PlayTennis= No • This instance affects the training instances: • Outlook = Sunny; Temp = Cool; Humidity = Normal; Wind = False; PlayTennis= Yes • Outlook = Sunny; Temp = Mild; Humidity = Normal; Wind = True; PlayTennis= Yes
Reasons for Overfitting Outlook sunny overcast rainy Humidity yes Windy high normal false true Windy no yes no false true Outlook = Sunny; Temp = Hot; Humidity = Normal; Wind = True; PlayTennis= No Outlook = Sunny; Temp = Cool; Humidity = Normal; Wind = False; PlayTennis= Yes Outlook = Sunny; Temp = Mild; Humidity = Normal; Wind = True; PlayTennis= Yes yes Temp mild high cool yes no ?
area with probably wrong predictions Reasons for Overfitting • Small number of instances are associated with leaf nodes. In this case it is possible that for coincidental regularities to occur that are unrelated to the actual borders. - + + + - + - + - + - + - - + - - - - - - - - - - - -
Approaches to Avoiding Overfitting • Pre-pruning: stop growing the tree earlier, before it reaches the point where it perfectly classifies the training data • Post-pruning: Allow the tree to overfit the data, and then post-prune the tree.
Outlook Outlook Overcast Sunny Overcast Rainy no ? yes Humidity yes Windy High Normal False True no yes yes no Pre-pruning • It is difficult to decide when to stop growing the tree. • A possible scenario is to stop when the leaf nodes get less than m training instances. Here is an example for m = 5. Rainy Sunny 2 3 2 3 2
Validation Set • Validation set is a set of instances used to evaluate the utility of nodes in decision trees. The validation set has to be chosen so that it is unlikely to suffer from same errors or fluctuations as the set used for decision-tree training. • Usually before pruning the training data is split randomly into a growing set and a validation set.
Reduced-ErrorPruning (Sub-tree replacement) Split data into growing and validation sets. Pruning a decision node d consists of: • removing the subtree rooted at d. • making d a leaf node. • assigning d the most common classification of the training instances associated with d. Outlook sunny overcast rainy Humidity yes Windy high normal false true no yes yes no 3 instances 2 instances Accuracy of the tree on the validation set is 90%.
Reduced-Error Pruning (Sub-tree replacement) Split data into growing and validation sets. Pruning a decision node d consists of: • removing the subtree rooted at d. • making d a leaf node. • assigning d the most common classification of the training instances associated with d. Outlook sunny overcast rainy no yes Windy false true yes no Accuracy of the tree on the validation set is 92.4%.
Reduced-Error Pruning (Sub-tree replacement) Split data into growing and validation sets. Pruning a decision node d consists of: • removing the subtree rooted at d. • making d a leaf node. • assigning d the most common classification of the training instances associated with d. Do until further pruning is harmful: • Evaluate impact on validation set of pruning each possible node (plus those below it). • Greedily remove the one that most improves validation set accuracy. Outlook sunny overcast rainy no yes Windy false true yes no Accuracy of the tree on the validation set is 92.4%.
Outlook Rain Sunny Overcast no yes yes Outlook Rain Sunny Overcast Wind Humidity yes Weak Strong High Normal Outlook Rain no yes no Temp. Sunny Overcast Cool,Hot Mild Wind Humidity yes no yes yes Weak Strong High Normal yes no yes no Outlook Rain Sunny Overcast Wind no yes Weak Strong yes no Reduced-Error Pruning (Sub-tree replacement) T1 T3 ErrorGS=13%, ErrorVS=15% ErrorGS=0%, ErrorVS=10% T4 T2 ErrorGS=27%, ErrorVS=25% T5 ErrorGS=6%, ErrorVS=8% ErrorGS=33%, ErrorVS=35%
Reduced-ErrorPruning (Sub-tree raising) Split data into growing and validation sets. Raising a sub-tree with root d consists of: • removing the sub-tree rooted at the parent of d. • place d at the place of its parent. • Sort the training instances associated with the parent of d usingthe sub-tree with rootd. Outlook sunny overcast rainy Humidity yes Windy high normal false true no yes yes no 3 instances 2 instances Accuracy of the tree on the validation set is 90%.
Reduced-ErrorPruning (Sub-tree raising) Split data into growing and validation sets. Raising a sub-tree with root d consists of: • removing the sub-tree rooted at the parent of d. • place d at the place of its parent. • Sort the training instances associated with the parent of d usingthe sub-tree with rootd. Outlook sunny overcast rainy Humidity yes Windy high normal false true no yes yes no 3 instances 2 instances Accuracy of the tree on the validation set is 90%.
Reduced-ErrorPruning (Sub-tree raising) Split data into growing and validation sets. Raising a sub-tree with root d consists of: • removing the sub-tree rooted at the parent of d. • place d at the place of its parent. • Sort the training instances associated with the parent of d usingthe sub-tree with rootd. Humidity high normal no yes Accuracy of the tree on the validation set is 73%. So, No!
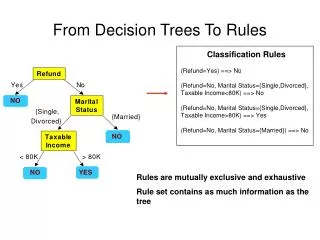
Rule Post-Pruning • Convert tree to equivalent set of rules. • Prune each rule independently of others. • Sort final rules by their estimated accuracy, and consider them in this sequence when classifying subsequent instances. Outlook IF (Outlook = Sunny) & (Humidity = High) THEN PlayTennis = No IF (Outlook = Sunny) & (Humidity = Normal) THEN PlayTennis = Yes ………. sunny overcast rainy Humidity yes Windy normal false true false no yes yes no
A2<0.33 ? yes no good A1<0.91 ? A2<0.91 ? A1<0.23 ? 1 good bad A2<0.75 ? A2<0.49 ? A2 good bad bad A2<0.65 ? 0 0 1 A1 bad good Decision Tree are non-linear. Can we make them linear?
x + y < 1 Class = + Class = Oblique Decision Trees • Test condition may involve multiple attributes • More expressive representation • Finding optimal test condition is computationally expensive!
Variables with Many Values Letter a y z • Problem: • Not good splits: they fragment the data too quickly, leaving insufficient data at the next level • The reduction of impurity of such test is often high (example: split on the object id). • Two solutions: • Change the splitting criterion to penalize variables with many values • Consider only binary splits c b …
Variables with Many Values • Example: outlook in the playtennis • InfoGain(outlook) = 0.246 • Splitinformation(outlook) = 1.577 • Gainratio(outlook) = 0.246/1.577=0.156 < 0.246 • Problem: the gain ratio favours unbalanced tests
| S | å = - ) xij I ( S , Xi ) I ( S ) I ( Sxij D | S | j Missing Values • If node n tests variable Xi, assign most common value of Xiamong other instances sorted to node n. • If node n tests variable Xi, assign a probability to each of possible values of Xi. These probabilities are estimated based on the observed frequencies of the values of Xi. These probabilities are used in the information gain measure (via info gain).
Windowing If the data don’t fit main memory use windowing: • Select randomly n instances from the training data D and put them in window set W. • Train a decision tree DT on W. • Determine a set M of instances from D misclassified by DT. 4. W = WUM. 5. IF Not(StopCondition) THEN GoTo 2;