Download
1 / 31
310 likes | 371 Views
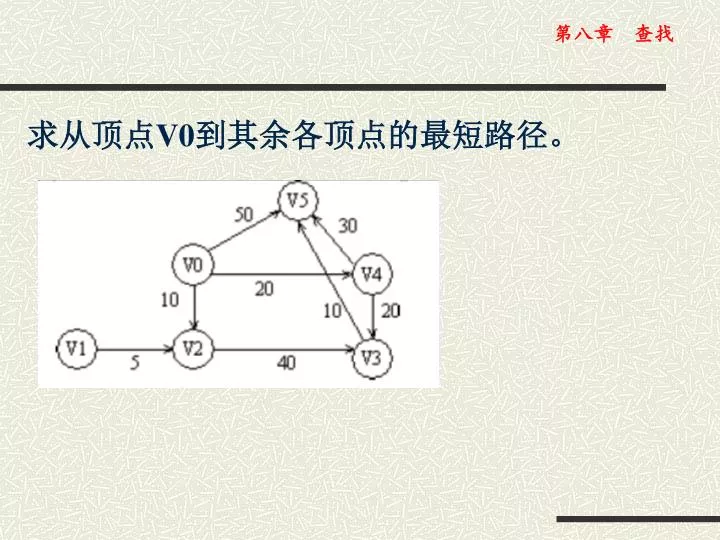
求从顶点 V0 到其余各顶点的最短路径。. 写出图 G 的所有拓扑有序序列。. DATA STRUCTURE. 第 8 章 查找. 引言. 查找是为了得到某个信息而常常进行的工作。 例如: 在英汉字典中查找某个英文单词的中文解释; 在新华字典中查找某个汉字的读音、含义; 在对数表、平方根表中查找某个数的对数、平方根; 邮递员送信件要按收件人的地址确定位置等等。 计算机和网络使信息查询更快捷、方便、准确。 要从计算机或网络中查找特定的信息,必须先在计算机中存储包含该特定信息的表。

E N D
DATA STRUCTURE 第8章 查找
引言 • 查找是为了得到某个信息而常常进行的工作。例如: • 在英汉字典中查找某个英文单词的中文解释; • 在新华字典中查找某个汉字的读音、含义; • 在对数表、平方根表中查找某个数的对数、平方根; • 邮递员送信件要按收件人的地址确定位置等等。 • 计算机和网络使信息查询更快捷、方便、准确。 • 要从计算机或网络中查找特定的信息,必须先在计算机中存储包含该特定信息的表。 • 如要从计算机中查找英文单词的中文解释,就需要存储类似英汉字典这样的信息表,以及对该表进行的查找操作。但由于计算机的特性,象对数、平方根等是通过函数求解,无需存储相应的信息表。 • 查找是许多程序中最消耗时间的一部分。 • 因而,一个好的查找方法会大大提高运行速度。 • 本章讨论“信息的存储和查找”。
Searching • 查找:根据给定的值,在某查找表中找出关键字等于给定值的记录或数据元素。 • 静态 • 查找表: • 动态 • 成功:给出找到的记录的有关信息或位置 • 查找结果 • 失败: 给出空记录或空指针 • 由同一类型的数据元素构成的集合
§1 静态查找表 • 一 、顺序表的查找 • 以顺序表或线性链表表示静态查找表。 • 查找方法:顺序查找(Sequential search)---最简单的查找方法 • 查找过程:从表的一端开始,逐个地将记录关键字值与给定值 K比较, 直到查找成功或到表的另一端。 • 顺序存储结构: • #define MAX ...... • typeded struct • { keytype key; /*关键字域,以int为例*/ • … otheritem /*记录的其他域*/ • } rectype; 0 1 2 3 4 5 6 7 8 9 10
顺序查找算法 • int seq_search(rectype R[], n,keytype k) • /*在顺序表R[1..n]中顺序查找键值为k( k为给定值)的记录*/ • /*查找成功,返回该记录在表R中的序号;查找不成功,返回0*/ • { int i; • R[0].key=k; /*设置监视哨或称岗哨*/ • i=n; /* n为r中的记录个数*/ • while( R[i].key!=k) i-- ; • return(i); • } • 0 1 2 3 4 5 6 7 8 9 10
查找性能分析 平均查找长度: 为确定记录在查找表中的位置,需和给定值进行比较的关键字个数的期望值称为查找算法在查找成功时的平均查找长度(Average Search Length,简称ASL) 其中:n为表中记录数; pi为表中第i个记录的查找概率,且 ; ci为找到表中第i个记录时和给定值进行比较的关键字个数,ci 随查找过程不同而不同。 查找不成功时的比较次数为:n+1 • 等概率
优点:简单,适应面广,对表的结构无要求; 缺点:ASL大,n大时效率低。 思考题:线性表用链式结构存储,过程如何?
二、折半查找(binary search) • 又称二分查找 • 对象:顺序有序表 • 过程:1、先确定待查记录所在的范围,t:指向表中最小关键字值的结点,h:指向表中最大关键字值的结点, • 2、m = 指示中间位置; • 3、k与R[m].key相比较,k=R[m].key,查找成功; • k<R[m].key, h=m-1,查找范围缩小一半,在表的前半部分,重复2、3,至查找成功或h<t查找失败; • k>R[m].key,t=m+1, 查找范围缩小一半,在表的后半部分,重复2、3,至查找成功或h<t查找失败。
折半查找算法: int bin_search (rectype R[], keytype k) /*设R递增有序*/ {int low,high,mid,found; low=0;high=n-1; /*置区间初值*/ found=FALSE; while((low<=high)&&(!found)) { mid=(low+high)/2; if (k<R[mid].key) high=mid-1; else if(k>R[mid].key) low=mid+1; else found=TRUE; } if(found) return mid; else return 0; }
三、分块查找 • 又称索引顺序查找 • 特点:(1)把表中记录分成n块,并建立有序索引表; • (2)索引表中每个元素对应一个块,记录块内最大 key值和块首地址; • (3) 块内记录无序,块间记录按key有序。 • 存储结构: • (1)将长度为n的表均匀地分成b块, • 每块含s个记录 b= • (2) 每块建立一个索引项,包括: • 10 关键字项(其值为块内最大key值) • 20项指针(指示块中首记录在表中的位置) • 索引表keyword 有序,表示块有序。
算法分析: • 确定块号:顺序查找或折半查找 • 块内查找:顺序查找
§2 树表查找 • 一、二叉查找树 • 若将查找表按二叉排序树的结构来组织,就构成一棵二叉查找树。(即在二叉排序树中进行的查找) • 过程:若要查找关键字等于k的记录 • k与根结点比较,相等,找到,查找成功; • k值小于根结点,查找左子树,否则,查找右子树。
查找算法: • typedef struct node • {keytype key; • struct node *lchild, *rchild; • }bstnode; • bstnode *bstsearch(bstnode *t , keytype k) • {if(t==NULL)||(t->key==k) return t; • else if(t->key>k) return(bstsearch(t->lchild,k)); • else return(bstsearch(t->rchild,k)); • }
例: • 平均查找长度:
二叉排序树不唯一(在构造二叉排序树的过程中不断地作平衡处理,称为平衡二叉树)二叉排序树不唯一(在构造二叉排序树的过程中不断地作平衡处理,称为平衡二叉树) • 折半查找的判定树唯一。
§3 哈希表及其查找 • 一、什么是哈希表 • (一、)问题的提出 • (1)前面讨论的线性表的查找,都是建立在“比较”的基础上: • 顺序查找时,比较结果为“=”或“≠”; • 折半查找、二叉排序树查找时,比较结果为:“<”、“=”或“>”,查找效率依赖于查找过程所进行的比较次数。 • (2)希望不经过任何比较,直接得到所查记录。 • 关键字K对 应 存储位置f(k) • 称对应关系f为Hash函数,按这个思想建立的表为Hash表。
例如: • 要将关键字值序列{3,15,22,24},存储到编号为0到4的表长为5的哈希表中的算法。计算存储地址的哈希函数可取余数算法,hash(key)=key MOD 5,则哈希表如下图:
(二)概念 • 哈希函数是一个映象,设定灵活,只要函数值在表长允许范围内即可。 • 冲突(collision):k1≠k2,而f(k1)=f(k2)的现象。 • 同义词(synonym):冲突中k1、k2称为同义词。 • 均匀的哈希函数:关键字集合中任一关键字经Hash函数映象到地址集合中任一地址的集合概率相等。 • 哈希表:根据设定的Hash函数和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上;并以关键字在地址集中的“象”作为记录在表中的存储位置。 • 哈希造表(散列):从key 到address的映象过程。 • 哈希地址(散列地址):哈希表中的位置。
二、Hash函数的构造方法 • 直接地址法 • 采用直接取关键字值或关键字的某个线性函数值作为哈希地址 • 数字分析法 • 当关键字值的位数大于存储地址码位数时,舍去数字分布不均匀的位,取分布均匀的位作为地址。 • 除留余数法(取模法) • 将关键字值除以一个整数m后把所得余数作为哈希函数的值。 • M叫做模。
Hash函数的构造方法 • 平方取中法 • 先计算出关键字值的平方,然后取它的中间几位作为哈希地址的编码。 • 折叠法 • 将关键字分成位数相同的几部分,然后取这几部分叠加和作为哈希地址。 • 随机法 • 选择一个随机函数,取关键字的随机函数值为它的哈希地址。
三、处理冲突的方法 • 开放地址法 • 当发生冲突时,形成一个地址序列,沿着这个序列逐个探测,直到找出一个空的开放地址,将发生冲突关键字值存放到该地址中去。 • 线性探测法 • 二次方探测法 • 伪随机探测法 • 链地址法 • 把所有关键字为同义词的记录存储在一个线性链表中,用数组s存放各个链表的头指针。第i个哈希地址中存在同义词时,则将其插入以s[i]为头指针的链表中去。 • 再哈希法 • 在同义词产生冲突现象时,计算另一个哈希函数,从而得到另一个哈希地址,直到冲突不再发生。
例:关键字集合为:{52,27,58,36,22,42,80,78,72,24},在0~10地址空间内,按哈希函数H(key)=key MOD 11和线性探测再散列冲突处理法构造Hash表。 H(52):8 H(27): 5 H(58):3 H(36):3 H(22): 0 H(42): 9 H(80): 3 H(78): 1 H(72): 6 H(24): 2 • 22 • 78 • 24 • 36 • 80 • 72 • 42
哈希表的查找和分析 • 查找过程和哈希造表过程基本一致。 • 过程:给定k值,根据造表时设定的哈希函数求得哈希地址,若此地址上没有记录,则查找不成功;否则比较关键字,若相等,则查找成功;若不等,则根据造表时设置的处理冲突的方法找下一地址,直至某个位置上为空或关键字比较相等为止。 上例中,查找80需比较几次?
哈希表的查找效率主要取决于哈希造表时处理冲突的方法。发生冲突的次数是和哈希表的装填程度有关。哈希表的装填因子α定义为哈希表的查找效率主要取决于哈希造表时处理冲突的方法。发生冲突的次数是和哈希表的装填程度有关。哈希表的装填因子α定义为 • α是哈希表的装填程度的标志,α越大,即表越满,发生冲突的可能性越大,查找时所用的比较次数也就越多。通常取为小于1而大于1/2之间的适当小数。
哈希表查找成功的平均查找长度Sn和α有关 • 线性探测再散列时 • 在伪随机探测再散列,二次探测再散列及重散列时 • 在链地址法中
