Download
1 / 11
120 likes | 163 Views
Learn about server clusters, types of clustering techniques, and benefits of shared-everything, mirrored servers, and shared-nothing models in maximizing performance and availability.

E N D
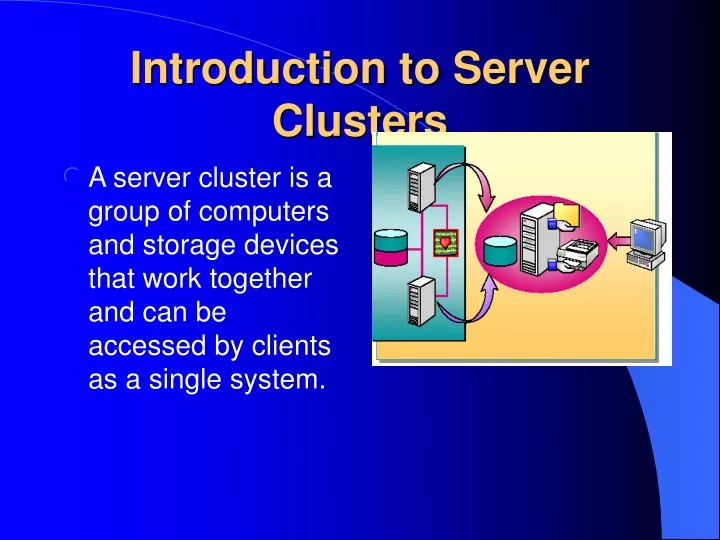
Introduction to Server Clusters • A server cluster is a group of computers and storage devices that work together and can be accessed by clients as a single system.
Server Clusters • There are two types of network communications in a server cluster. The nodes communicate with each other over a high performance, reliable network, and share one or more common storage devices. Clients communicate to logical servers, referred to as virtual servers, to gain access to grouped resources, such as file or print shares, services such as Windows Internet Name Service (WINS), and applications like Microsoft Exchange Server.
Server Clusters • There are three types of clustering techniques commonly used: shared everything, mirrored servers, and shared nothing. Microsoft Cluster Service uses the shared nothing model.
Clustering Techniques:Shared Everything Model • In the shared everything, or shared device model, software running on any computer in the cluster can gain access to any hardware resource connected to any computer in the cluster (for example, a hard drive, random access memory (RAM), and CPU). • The shared everything server clusters permit every server to access every disk. Allowing access to all of the disks originally required expensive cabling and switches, plus specialized software and applications. If two applications require access to the same data, much like a symmetric multiprocessor (SMP) computer, the cluster must synchronize access to the data. In most shared device cluster implementations, a component called a Distributed Lock Manager (DLM) is used to handle this synchronization.
Clustering Techniques:Shared Everything Model • The Distributed Lock Manager (DLM) The Distributed Lock Manager (DLM) is a service running on the cluster that keeps track resources within the cluster. If multiple systems or applications attempt to reference a single resource, the DLM recognizes and resolves the conflict. However, using a DLM introduces a certain amount of overhead into the system in the form of additional message traffic between nodes of the cluster in addition to the performance loss due to serialized access to hardware resources. Shared everything clustering also has inherent limits on scalability, because DLM contention grows geometrically as you add servers to the cluster.
Clustering Techniques:Mirrored Servers • An alternative to the shared everything and shared nothing models is to run software that copies the operating system and the data to a backup server. This technique mirrors every change from one server to a copy of the data on at least one other server. This technique is commonly used when the locations of the servers are too far apart for the other cluster solutions. The data is kept on a backup server at a disaster recovery site and is synchronized with a primary server. However, a mirrored server solution cannot deliver the scalability benefits of clusters. Mirrored servers may never deliver as high a level of availability and manageability as shared-disk clustering, because there is always a finite amount of time during the mirroring operation in which the data at both servers is not identical.
Clustering Techniques:Shared Nothing Model • The shared nothing model, also known as the partitioned data model, is designed to avoid the overhead of the DLM in the shared everything model. In this model, each node of the cluster owns a subset of the hardware resources that make up the cluster. As a result, only one node can own and access a hardware resource at a time. A shared-nothing cluster has software that can transfer ownership to another node in the event of a failure. The other node takes ownership of the hardware resource so that the cluster can still access it. • The shared nothing model is asymmetric. The cluster workload is broken down into functionally separate units of work that different systems performed in an independent manner. For example, Microsoft SQL Server™ may run on one node at the same time as Exchange is running on the other.
Clustering Techniques:Shared Nothing Model • A shared nothing cluster provides the same high level of availability as a shared everything cluster and potentially higher scalability, because it does not have the inherent bottleneck of a DLM. An added advantage is that it works with standard applications because there are no special disk access requirements. Examples of shared nothing clustering solutions include Tandem NonStop, Informix Online/XPS, and Microsoft Windows 2000 Cluster service. • Note:Cluster service uses the shared nothing model. By default, Cluster service does not allow simultaneous access from both nodes to the shared disks or any resource. Cluster service can support the shared device model as long as the application supplies a DLM.
Availability and Scalability • Microsoft Cluster service makes resources, such as services and applications, more available by providing for restart and failover of the resource. Another benefit of Cluster service is that it provides greater scalability of the resource because you can separate applications and services to run on different servers.
Availability • When a system or component in the cluster fails, the cluster software responds by dispersing the work from the failed system to the remaining systems in the cluster. • Cluster service improves the availability of client/server applications by increasing the availability of server resources. Using Cluster service, you can set up applications on multiple nodes in a cluster. If one node fails, the applications on the failed node are available on the other node. Throughout this process, client communications with applications usually continue with little or no interruption. In most cases, the interruption in service is detected in seconds, and services can be available again in less than a minute (depending on how long it takes to restart the application). • Clustering provides high availability with static load balancing, but it is not a fault tolerant solution. Fault tolerant solutions offer error-free, nonstop availability, usually by keeping a backup of the primary system. This backup system remains idle and unused until a failure occurs, which makes this an expensive solution.
Scalability • When the overall load exceeds the capabilities of the systems in the cluster, instead of replacing an existing computer with a new one with greater capacity, you can add additional hardware components to increase the node’s performance, while maintaining availability of applications that are running on the cluster. Using Microsoft clustering technology, it is possible to incrementally add smaller, standard systems to the cluster as needed to meet overall processing power requirements. • Clusters are highly scalable; you can add CPU, input/output (I/O), storage, and application resources incrementally to efficiently expand capacity. A highly scalable solution creates reliable access to system resources and data, and protects your investment in both hardware and software resources. Server clusters are affordable because they can be built with commodity hardware (high-volume components that are relatively inexpensive).






















