Download
1 / 33
330 likes | 346 Views
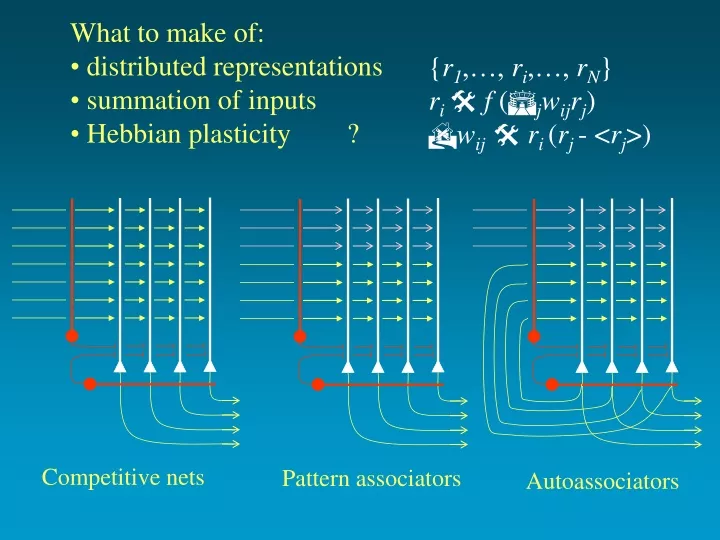
Competitive nets. Pattern associators. Autoassociators. What to make of: distributed representations summation of inputs Hebbian plasticity ?. { r 1 ,…, r i ,…, r N } r i f ( j w ij r j ) w ij r i ( r j - < r j >). Competitive Networks

E N D
Competitive nets Pattern associators Autoassociators • What to make of: • distributed representations • summation of inputs • Hebbian plasticity ? {r1,…, ri,…, rN} ri f (jwijrj) wij ri (rj - <rj>)
Competitive Networks • “discover” structures in input • space • may remove redundancy • may orthogonalize • may categorize • may sparsify representations • can separate out even linear • combinations • can easily be generalized to self- • organizing topographic maps
H(S) s’(r) Estimating mutual information after decoding: H(R) H(S) s r I(S,R) if R is multidimensional, difficult to estimate Decoded Information, easier to measure but somewhat arbitrary I(S,S’) I(R,S’) (see Bialek et al, 1991)
A simple 1D example: • localization on a ring, with short range excitation • (simple model of recurrent effects in orientation • selective responses, or in coding head direction) • Decoding via: • Peak activity • Cosine fitting • Template (storage and) matching via • dot product • Pearson correlation • Bayesian or quasi-Bayesian match of full prob. distr.
Pattern associators • generalize to nearby input • vectors • gracefully degrade/fault tolerant • may extract prototypes • may reduce fluctuations • are fast (feed forward) • p (the # of associations) is • proportional to C (# inputs/unit) • and also grows with decreasing • a (sparser patterns) Y X r (X) = r (Y) after learning
Associative retrieval: The inhibitory interneuron divides down the excitation in proportion to the total input to the net, so that only the most strongly excited cells reach threshold (i.e., integer division). 3 3 2 2 3 3 2 3 1 0 0 1 1 0
3 3 2 2 3 3 2 3 1 0 0 1 1 0
Pattern completion: The inhibitory interneuron divides down the excitation in proportion to the total input to the net, so that only the most strongly excited cells reach threshold (i.e., integer division). 2 1 1 2 1 2 2 2 0 0 1 0 1 1
Pattern associators • generalize to nearby input • vectors • gracefully degrade/fault tolerant • may extract prototypes • may reduce fluctuations • are fast (feed forward) • p (the # of associations) is • proportional to C (# inputs/unit) • and also grows with decreasing • a (sparser patterns) Y X r (X) = r (Y) after learning
The signal-to-noise analysis For pattern associators, see ET Rolls & AT, Network 1:407 (1990)
Storage is formally equivalent to forming the so-called outer product of two binary vectors. Multiple memories are stored by combining outer product matrices using the logical OR operation. Retrieval is formally equivalent to taking the inner (or dot) product of the input vector and the storage matrix (i.e., multiply through the rows and sum the columns) and subjecting it to a non-linear normalization (i.e., integer division).
Autoassociation in a recurrent net The input pattern is kept on for 2 time steps so that the output at time t-1 is associated with the input at time t
Error correction (pattern completion)
"Reverberation": persistence of pattern after removal of input Persistence requires synaptic weights to be symmetrical: Wij = Wji , although for large nets symmetry does not have to be perfect.
Sequence Learning in Recurrent Nets If inputs change each cycle, the output at time t-1 is associated with the input at time t.
Presentation of any vector in the sequence leads to sequence completion if and only if all elements of the sequence are unique.
Autoassociators • complete a partial cue • can continue a sequence • generalize • gracefully degrade/fault tolerant • extract prot. / reduce fluct. • are also fast, but their feedback • may sustain short term memory • pc is again proportional to C • and grows with decreasing a • pc = k C / [a log (1/a)] Y r (Y’) = r (Y) after learning
The signal-to-noise analysis (for pattern associators, see ET Rolls & AT, Network 1:407 (1990) or Appendix 3 in our book)
But: recurrent nets self consistent statistics! • insert δ-functions • exponentiate them, with additional integrals • estimate them at the saddle-point (for order parameters) But: quenched parameters assume self-averaging average the logarithms with the replica trick (see this discussion in Appendix 4 of our book)
Constraints on Storage Capacity 1) Connectivity. In real networks connectivity is much less than all-to-all. Capacity is proportional to the number of synapses/unit, C. 2) Sparsity of coding, a. Sparsity roughly speaking refers to the fraction of the units active at any one time. The continuum ranges from extremely sparse (a=1/N) to fully distributed (a=1). Sparse activity allows more patterns, but not more information. 3) "Orthogonality" of coding. By definition, orthogonal vectors have an overlap of zero. In practice, the maximum number of stored patterns is achieved when the patterns are uncorrelated, not mutually orthogonal. Correlated patterns cause local saturation.
Sparser inputs to the associative memory system can be generated by more efficient coding of the input (redundancy reduction). Much of the processing of visual and other sensory information in 'primary' and 'secondary' sensory cortex is devoted to this process of "feature extraction", with various simple feature detectors developmentally programmed. Association cortex learns to develop high order feature detectors based on past experience.