Download

1 / 70
710 likes | 935 Views
Scalable Parallel Architectures and their Software. Introduction. Overview of RISC CPUs, Memory Hierarchy Parallel Systems - General Hardware Layout (SMP, Distributed, Hybrid) Communications Networks for Parallel Systems Parallel I/O Operating Systems Concepts

E N D
Scalable Parallel Architectures and their Software
Introduction • Overview of RISC CPUs, Memory Hierarchy • Parallel Systems - General Hardware Layout (SMP, Distributed, Hybrid) • Communications Networks for Parallel Systems • Parallel I/O • Operating Systems Concepts • Overview of Parallel Programming Methodologies • Distributed Memory • Shared-Memory • Hardware Specifics of NPACI Parallel Machines • IBM SP Blue Horizon • New CPU Architectures • IBM Power 4 • Intel IA-64
What is Parallel Computing? • Parallel computing: the use of multiple computers or processors or processes working together on a common task. • Each processor works on its section of the problem • Processors are allowed to exchange information (data in local memory) with other processors Grid of Problem to be solved CPU #1 works on this area of the problem CPU #2 works on this area of the problem exchange y CPU #3 works on this area of the problem CPU #4 works on this area of the problem exchange x
Why Parallel Computing? • Limits of single-CPU computing • Available memory • Performance - usually “time to solution” • Limits of Vector Computers – main HPC alternative • System cost, including maintenance • Cost/MFlop • Parallel computing allows: • Solving problems that don’t fit on a single CPU • Solving problems that can’t be solved in a reasonable time on one CPU • We can run… • Larger problems • Finer resolution • Faster • More cases
Scalable Parallel Computer Systems (Scalable) [ ( CPUs) + (Memory) + (I/O) + (Interconnect) + (OS) ] = Scalable Parallel Computer System
Scalable Parallel Computer Systems Scalablity: A parallel system is scalable if it is capable of providing enhanced resources to accommodate increasing performance and/or functionality • Resource scalability: scalability achieved by increasing machine size ( # CPUs, memory, I/O, network, etc.) • Application scalability • machine size • problem size
CPU CPU CPU CPU M M M M NETWORK CPU CPU CPU CPU BUS/CROSSBAR MEMORY Shared and Distributed Memory Systems • Multicomputer (Distributed memory) • Each processor has it’s own local • memory. • Examples: CRAY T3E, IBM SP2, • PC Cluster • Multiprocessor (Shared memory) • Single address space. All processors • have access to a pool of shared memory. • Examples: SUN HPC, CRAY T90, NEC SX-6 • Methods of memory access : • - Bus • - Crossbar
CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU Interconnect Interconnect Interconnect Network MEMORY MEMORY MEMORY Hybrid (SMP Clusters) Systems Hybrid Architecture – Processes share memory on-node, may/must use message-passing off-node, may share off-node memory Example: IBM SP Blue Horizon, SGI Origin, Compaq Alphaserver
RISC-Based Computer Hardware Concepts RISC CPUs most common CPUs in HPC – many design concepts transferred from vector CPUs to RISC to CISC • Multiple Functional Units • Pipelined Instructions • Memory Hierarchy • Instructions typically take 1-several CPU clock cycles • Clock cycles provide time scale for measurement • Data transfers – memory-to-CPU, network, I/O, etc.
Laura C. Nett: Instruction set is just how each operation is processed x=y+1 load y and a add y and a put in x Processor Related Terms • RISC : Reduced Instruction Set Computers • PIPELINE : Technique where multiple instructions are overlapped in execution • SUPERSCALAR : Computer designfeature -multiple instructions can be executed per clock period
Loads & Stores r0 r1 r2 . . . . r32 ‘Typical’ RISC CPU CPU Chip Functional Units registers FP Add FP Multiply Memory/Cache FP Multiply & Add FP Divide
Chair Building Function Unit Carpenter 1 Carpenter 2 Carpenter 3 Carpenter 4 Carpenter 5 • Fully Segmented - A(I)=C(I)*D(I) C(I) A(I) D(I) Multiply pipeline length Functional Unit
Dual Hardware Pipes A(I) = C(I)*D(I) odd C(I) odd C(I) A(I) & A(I+1) even C(I+1) even D(I+1)
RISC Memory/Cache Related Terms • ICACHE : Instruction cache • DCACHE (Level 1) : Data cache closest to registers • SCACHE (Level 2) : Secondary data cache • Data from SCACHE has to go through DCACHE to registers • SCACHE is larger than DCACHE • All processors do not have SCACHE • CACHE LINE: Minimum transfer unit (usually in bytes) for moving data between different levels of memory hierarchy • TLB : Translation-look-aside buffer keeps addresses of pages ( block of memory) in main memory that have been recently accessed • MEMORY BANDWIDTH: Transfer rate (in MBytes/sec) between different levels of memory • MEMORY ACCESS TIME: Time required (often measured in clock cycles) to bring data items from one level in memory to another • CACHE COHERENCY: Mechanism for ensuring data consistency of shared variables across memory hierarchy
RISC CPU, CACHE, and MEMORY Basic Layout CPU Registers Level 1 Cache Level 2 Cache MAIN MEMORY
RISC Memory/Cache Related Terms • ICACHE : Instruction cache • DCACHE (Level 1) : Data cache closest to registers • SCACHE (Level 2) : Secondary data cache • Data from SCACHE has to go through DCACHE to registers • SCACHE is larger than DCACHE • All processors do not have SCACHE • CACHE LINE: Minimum transfer unit (usually in bytes) for moving data between different levels of memory hierarchy • TLB : Translation-look-aside buffer keeps addresses of pages ( block of memory) in main memory that have been recently accessed • MEMORY BANDWIDTH: Transfer rate (in MBytes/sec) between different levels of memory • MEMORY ACCESS TIME: Time required (often measured in clock cycles) to bring data items from one level in memory to another • CACHE COHERENCY: Mechanism for ensuring data consistency of shared variables across memory hierarchy
Direct mapped cache: A block from main memory can go in exactly one place in the cache. This is called direct mapped because there is direct mapping from any block address in memory to a single location in the cache. RISC Memory/Cache Related Terms (cont.) cache Main memory
RISC Memory/Cache Related Terms (cont.) Fully associative cache : A block from main memory can be placed in any location in the cache. This is called fully associative because a block in main memory may be associated with any entry in the cache. cache Main memory
RISC Memory/Cache Related Terms (cont.) Set associative cache : The middle range of designs between direct mapped cache and fully associative cache is called set-associative cache. In a n-way set-associative cache a block from main memory can go into n (n at least 2) locations in the cache. 2-way set-associative cache Main memory
RISC Memory/Cache Related Terms • The data cache was designed to allow programmers to take advantage of common data access patterns : • Spatial Locality • When an array element is referenced, its neighbors are likely to be referenced • Cache lines are fetched together • Work on consecutive data elements in the same cache line • Temporal Locality • When an array element is referenced, it is likely to be referenced again soon • Arrange code so that data in cache is reused as often as possible
Typical RISC Floating-Point Operation Times IBM POWER3 II • CPU Clock Speed – 375 MHz ( ~ 3 ns)
Typical RISC Memory Access Times IBM POWER3 II
Single CPU Optimization Optimization of serial (single CPU) version is very important • Want to parallelize best serial version – where appropriate
New CPUs in HPC New CPU designs with new features • IBM POWER 4 • U Texas Regatta nodes – covered on Wednesday • Intel IA-64 • SDSC DTF TeraGrid PC Linux Cluster
Parallel Networks Network function is to transfer data from source to destination in support of network transactions used to realize supported programming model(s). Data transfer can be for message-passing and/or shared-memory operations. • Network Terminology • Common Parallel Networks
System Interconnect Topologies Send Information among CPUs through a Network - Best choice would be a fully connected network in which each processor has a direct link to every other processor – Fully Connected Network. This type of network would be very expensive and difficult to scale ~N*N. Instead, processors are arranged in some variation of a mesh, torus, hypercube, etc. 2-D Mesh 2-D Torus 3-D Hypercube
Network Terminology • Network Latency : Time taken to begin sending a message. Unit is microsecond, millisecond etc. Smaller is better. • Network Bandwidth : Rate at which data is transferred from one point to another. Unit is bytes/sec, Mbytes/sec etc. Larger is better. • May vary with data size For IBM Blue Horizon:
Network Terminology Bus • Shared data path • Data requests require exclusive access • Complexity ~ O(N) • Not scalable – Bandwidth ~ O(1) Crossbar Switch • Non-blocking switching grid among network elements • Bandwidth ~ O(N) • Complexity ~ O(N*N) Multistage Interconnection Network (MIN) • Hierarchy of switching networks – e.g., Omega network for N CPUs, N memory banks: complexity ~ O(ln(N))
Network Terminology (Continued) • Diameter – maximum distance (in nodes) between any two processors • Connectivity – number of distinct paths between any two processors • Channel width – maximum number of bits that can be simultaneously sent over link connecting two processors = number of physical wires in each link • Channel rate – peak rate at which data can be sent over single physical wire • Channel bandwidth – peak rate at which data can be sent over link = (channel rate) * (channel width) • Bisection width – minimum number of links that have to be removed to partition network into two equal halves • Bisection bandwidth – maximum amount of data between any two halves of network connecting equal numbers of CPUs = (bisection width) * (channel bandwidth)
Communication Overhead Time to send a message of M bytes – simple form: Tcomm = TL + M*Td + TContention TL = Message Latency T = 1byte/bandwidth Tcontention – Takes into account other network traffic
Communication Overhead Time to send a message of M bytes – simple form: Tcomm = TL + M*Td + TContention TL = Message Latency T = 1byte/bandwidth Tcontention – Takes into account other network traffic
Parallel I/O I/O can be limiting factor in parallel application • I/O system properties – capacity, bandwidth, access time • Need support for Parallel I/O in programming system • Need underlying HW and system support for parallel I/O • IBM GPFS – low-level API for developing high-level parallel I/O functionality – MPI I/O, HDF 5, etc.
Unix OS Concepts for Parallel Programming Most Operating Systems used by Parallel Computers are Unix-based • Unix Process (task) • Executable code • Instruction pointer • Stack • Logical registers • Heap • Private address space • Task forking to create dependent processes – thousands of clock cycles • Thread – “lightweight process” • Logical registers • Stack • Shared address space • Hundreds of clock cycles to create/destroy/synchronize threads
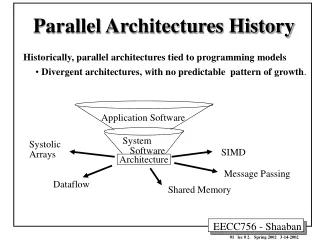
Parallel Computer Architectures (Flynn Taxonomy) Control Mechanism SIMD MIMD Hybrid (SMP cluster) distributed-memory Memory Model shared-memory
Hardware Architecture Models for Design of Parallel Programs Sequential computers - von Neumann model (RAM) is universal computational model Parallel computers - no one model exists • Model must be sufficiently general to encapsulate hardware features of parallel systems • Programs designed from model must execute efficiently on real parallel systems
Designing and Building Parallel Applications Donald Frederick frederik@sdsc.edu San Diego Supercomputing Center
What is Parallel Computing? • Parallel computing: the use of multiple computers or processors or processes concurrently working together on a common task. • Each processor/process works on its section of the problem • Processors/process are allowed to exchange information (data in local memory) with other processors/processes Grid of Problem to be solved CPU #1 works on this area of the problem CPU #2 works on this area of the problem exchange y CPU #3 works on this area of the problem CPU #4 works on this area of the problem exchange x
CPU CPU CPU CPU M M M M NETWORK CPU CPU CPU CPU Interconnect MEMORY Shared and Distributed Memory Systems Mulitprocessor Shared memory - Single address space. Processes have access to a pool of shared memory. Single OS. Multicomputer Distributed memory - Each processor has it’s own local memory. Processes usually do message passing to exchange data among processors. Usually multiple Copies of OS
CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU Interconnect Interconnect Interconnect Network MEMORY MEMORY MEMORY Hybrid (SMP Clusters) System • Must/may use message-passing. • Single or multiple OS copies • Node-Local operations less costly • than off-node
Unix OS Concepts for Parallel Programming Most Operating Systems used are Unix-based • Unix Process (task) • Executable code • Instruction pointer • Stack • Logical registers • Heap • Private address space • Task forking to create dependent processes – thousands of clock cycles • Thread – “lightweight process” • Logical registers • Stack • Shared address space • Hundreds of clock cycles to create/destroy/synchronize threads
Generic Parallel Programming Models Single Program Multiple Data Stream (SPMD) • Each CPU accesses same object code • Same application run on different data • Data exchange may be handled explicitly/implicitly • “Natural” model for SIMD machines • Most commonly used generic parallel programming model • Message-passing • Shared-memory • Usually uses process/task ID to differentiate • Focus of remainder of this section Multiple Program Multiple Data Stream (MPMD) • Each CPU accesses different object code • Each CPU has only data/instructions needed • “Natural” model for MIMD machines
Parallel “Architectures” – Mapping Hardware Models to Programming Models Control Mechanism SIMD MIMD Hybrid (SMP cluster) distributed-memory Memory Model shared-memory Programming Model SPMD MPMD
Methods of Problem Decomposition for Parallel Programming Want to map (Problem + Algorithms + Data)Architecture Conceptualize mapping via e.g., pseudocode Realize mapping via programming language • Data Decomposition - data parallel program • Each processor performs the same task on different data • Example - grid problems • Task (Functional ) Decomposition - task parallel program • Each processor performs a different task • Example - signal processing – adding/subtracting frequencies from spectrum • Other Decomposition methods
Designing and Building Parallel Applications • Generic Problem Architectures • Design and Construction Principles • Incorporate Computer Science Algorithms • Use Parallel Numerical Libraries Where Possible
Designing and Building Parallel Applications • Know when (not) to parallelize is very important • Cherri Pancake’s “Rules” summarized: • Frequency of Use • Execution Time • Resolution Needs • Problem Size
Categories of Parallel Problems Generic Parallel Problem “Architectures” ( after G Fox) • Ideally Parallel (Embarrassingly Parallel, “Job-Level Parallel”) • Same application run on different data • Could be run on separate machines • Example: Parameter Studies • Almost Ideally Parallel • Similar to Ideal case, but with “minimum” coordination required • Example: Linear Monte Carlo calculations, integrals • Pipeline Parallelism • Problem divided into tasks that have to be completed sequentially • Can be transformed into partially sequential tasks • Example: DSP filtering • Synchronous Parallelism • Each operation performed on all/most of data • Operations depend on results of prior operations • All processes must be synchronized at regular points • Example: Modeling Atmospheric Dynamics • Loosely Synchronous Parallelism • similar to Synchronous case, but with “minimum” intermittent data sharing • Example: Modeling Diffusion of contaminants through groundwater
Designing and Building Parallel Applications Attributes of Parallel Algorithms • Concurrency - Many actions performed “simultaneously” • Modularity - Decomposition of complex entities into simpler components • Locality - Want high ratio of of local memory access to remote memory access • Usually want to minimize communication/computation ratio • Performance • Measures of algorithmic “efficiency” • Execution time • Complexity usually ~ Execution Time • Scalability
Designing and Building Parallel Applications Partitioning - Break down main task into smaller ones – either identical or “disjoint”. Communication phase - Determine communication patterns for task coordination, communication algorithms. Agglomeration - Evaluate task and/or communication structures wrt performance and implementation costs. Tasks may be combined to improve performance or reduce communication costs. Mapping - Tasks assigned to processors; maximize processor utilization, minimize communication costs. Mapping may be either static or dynamic. May have to iterate whole process until satisfied with expected performance • Consider writing application in parallel, using either SPMD message-passing or shared-memory • Implementation (software & hardware) may require revisit, additional refinement or re-design
Designing and Building Parallel Applications Partitioning • Geometric or Physical decomposition (Domain Decomposition) - partition data associated with problem • Functional (task) decomposition – partition into disjoint tasks associated with problem • Divide and Conquer – partition problem into two simpler problems of approximately equivalent “size” – iterate to produce set of indivisible sub-problems
Generic Parallel Programming Software Systems Message-Passing • Local tasks, each encapsulating local data • Explicit data exchange • Supports both SPMD and MPMD • Supports both task and data decomposition • Most commonly used • Process-based, but for performance, processes should be running on separate CPUs • Example API: MPI, PVM Message-Passing libraries • MP systems, in particular, MPI, will be focus of remainder of workshop Data Parallel • Usually SPMD • Supports data decomposition • Data mapping to cpus may be either implicit/explicit • Example: HPF compiler Shared-Memory • Tasks share common address space • No explicit transfer of data - supports both task and data decomposition • Can be SPMD, MPMD • Thread-based, but for performance, threads should be running on separate CPUs • Example API : OpenMP, Pthreads Hybrid - Combination of Message-Passing and Shared-Memory - supports both task and data decomposition • Example: OpenMP + MPI