Download

1 / 27
290 likes | 675 Views
YEDITEPE UNIVERSITY. SAMPLE SIZE AND POWER CALCULATION. Assist . Prof. E. Çiğdem Kaspar , Ph .D . Yeditepe University, Faculty of Medicine , Department of Biostatistics Turkey. Power and Sample S ize.

E N D
YEDITEPE UNIVERSITY SAMPLE SIZE AND POWER CALCULATION Assist. Prof. E. Çiğdem Kaspar,Ph.D. Yeditepe University, Faculty of Medicine, Department of Biostatistics Turkey
Power and Sample Size • Statistical studies (surveys, experiments, observational studies, etc.) are always better when they are carefullyplanned. • Good planning has many aspects. • The problem should be carefully defined and operationalized. • Experimental or observational units must be selected from the appropriate population. • The study mustbe randomized correctly. • The procedures must be followed carefully. • Reliable instruments should be used to obtain measurements. • Finally, the study must be of adequate size, relative to the goals of the study.
Power and Sample Size • Statisticalsignificanceandbiologicalsignificanceare not the same thing. • For example, given a largeenough sample size, any statistical hypothesis testis likely to be statistically significant, almostregardless of the biological importance of theresults. • Conversely, when the sample size is small,biologically interesting phenomena may be missedbecause statistical tests are unlikely to yield statisticallysignificant results.
Power and Sample Size • It is important not to use too many experimental unitsin an experiment because it costs money, time and effort, and it is unethical. • Conversely, if too few experimentalunitare used the experiment may be unable to detect a clinically or scientifically important response to the treatment. This also wastes resources and could have serious consequences, particularly in safety assessment. • We need to avoid making either of these mistakes
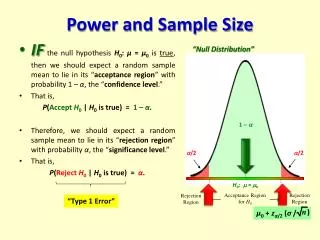
Minimising statistical errors The null hypothesis • In a controlled experiment the aim is usually to compare two or more means (or sometimes medians or proportions). • We normally set up a “null hypothesis” that there is no difference between the means, and the aim of our experiment is to disprove that null hypothesis.
Minimising statistical errors • However, as a result of inter-individual variability we may make a mistake. If we fail to find a true difference, then we have a false negative result, also known as a type II or b error. Conversely, if we think that there is a difference when in fact it is just due to chance, then we have a false positive, Type I, or a error. These are shown in the table below
Power analysis and the control of statistical errors • We can control type I errors because we can estimate the probability that the means could differ to a given degree knowing the sample sizes and the degree of variability (and making some assumptions about the distribution of the data). • If it is highly unlikely that they came from the same population, we reject the null hypothesis and assume that the treatment has had an effect. • The probability of a type I error is usually we set it at 0.05, or 5%. For every 100 experiments we would expect, on average five type I errors to be made. • We don’t usually set it much lower than this because that will increase the probability of a type II error.
Power analysis and the control of statistical errors • Type II errors are more difficult to control. False negative results occur when there is excessive variation (“noise”) or there is only a small response to the treatment (a low “signal”). • We can specify the probability of a type II error or the statistical power (one minus the type II error) if we use a power analysis.
Power Analysis • Statistical power is defined as the probability of rejecting the null hypothesis while the alternative hypothesis is true. Power = 1-β = P( reject H0 | H1 true ) • Power analysis can be used to determinewhether the experiment had a good chanceof producing a statistically significant result ifa biologically significant difference existed inthepopulation. • In research, statistical power is generally calculated for two purposes. • It can be calculated before data collection based on information from previous research to decide the sample size needed for the study. • It can also be calculated after data analysis. It usually happens when the result turns out to be non-significant. In this case, statistical power is calculated to verify whether the non-significant result is due to really no relation in the sample or due to a lack of statistical power.
Variables involved in a power analysis • The effect size of scientific interest (the signal)This is the magnitude of response to the treatment likely to be of scientific or clinical importance. It has to be specified by the investigator. Alternatively, if the experiment has already been done it is the actual response (difference between treated and control means) • The variability among experimental units (the noise)This is the standard deviation of the character of interest. It has to come from a previous study or the literature as the experiment has not yet been done • The power of the proposed experimentThis is 1-b where b is the probability of a type II error. This also has to be specified by the investigator. It is often set at 0.8 to 0.9 (80 or 90%) • The alternative hypothesisThe null hypothesis is that the means of the two groups do not differ. The alternative hypothesis may be that they do differ (two sided), or that they differ in a particular direction (one sided) • The significance levelAs previously explained, this is usually set at 0.05 • The sample sizeThis is the number in each group. It is usually what we want to estimate. However, we sometimes have only a fixed number of subjects in which case the power analysis can be used to estimate power or effect size.
Power Analysis • For most common statistical tests, power is easilycalculatedfromtables, or using statistical computer software. • Powerformula depends on study design it is not hard, but can be very algebra intensive • Researcher may want to use a computer program or statistician • As an example of handcalculation; • Given that a researcher has the null hypothesis that μ=μ0 and alternative hypothesis that μ=μ1≠ μ0, and that the population variance is known as σ2. Also, he knows that he wants to reject the null hypothesis at a significance level of α which gives a corresponding Z score, called it Zα/2. • Therefore, the power function will be, P{Z> Zα/2 or Z< -Zα/2|μ1}=1-Φ[Zα/2-(μ1-μ0)/(σ/n)]+Φ[-Zα/2-(μ1-μ0)/(σ/n)].
Power is Effected by • Statistical power is positively correlated with the sample size, which means that given the level of the other factors, a larger sample size gives greater power. More subjects higher power • Variation in the outcome (σ2) ↓ σ2→ power ↑ • Significance level (α) ↑ α→ power ↑ • Difference (effect) to be detected (δ) ↑δ→ power ↑ • One-tailed vs. two-tailed tests Power is greater in one-tailed tests than comparable two-tailed tests
Power Analysis • After plugging in the required information, a researcher can get a function that describes the relationship between statistical power and sample size and the researcher can decide which power level they prefer with the associated sample size. The choice of sample size may also be constrained by factors such as the financial budget the researcher is faced with. But generally consultants would like to recommend that the minimum power level is set to be 0.80. • The researchers must have some information before they can do the power and sample size calculation. The information includes previous knowledge about the parameters (their means and variances) and what confidence or significance level is needed in the study.
Application-1 • The following results are from a pilot study done on 29women, all 35–39 years old • Of is particularinterest is whether Oral Contraceptiveuse is associatedwithhigherbloodpressure. Simulated Sample Data
Application-1 • Thesamplemeandifference in bloodpressure is 132.8-127.4=5.4 • Thiscould be consideredscientificallysignificant, however, theresult is not significant at α=0,05 level • This OC/Blood pressure study has power 0,106 to detect the a difference in blood pressure of 5.4 or more, if this difference truly exists in the population of women 35-39 years old. • Whenpower is toolow, it is diffuculttodeterminewhetherthere is no statisticaldifference in populationmeansorwejustcould not detect it.
Application-1 • Power Changes • n = 29, 2 sample test, 11% power, δ=5,4, σ = 17,49, α = 0.05, 2-sided test • Variance/Standard deviation • σ: 17,49→4,5 Power: 11% →80% • σ: 17,49→20 Power: 11% →9% • Significance level (α) • α : 0.05 → 0.01 Power: 11% →3% • α : 0.05 → 0.10 Power: 11% →18%
Application-1 • Power Changes • n = 29, 2 sample test, 11% power, δ=5,4, σ = 17,49, α = 0.05, 2-sided test • Difference to be detected (δ) • δ : 5,4→3 Power: 11% →7% • δ : 5,4→7 Power: 11% →15% • Sample size (n) • n: 29→58 Power: 11% →17% • n: 29→ 25 Power: 11% →10%
Sample Size • In a researchstudy, a statistical test is applied to determinewhether or not there is a significant difference between the means or proportions observedin the comparison groups. • Before undertaking a study, the investigator should firstdetermine the minimum number of subjects (i.e., samplesize estimation) that must be enrolled in each group inorder that the null hypothesis can be rejected if it is false.
Sample Size • Sample size estimations are warranted in all clinicalstudies for both ethical and scientific reasons. • The ethical, reasons pertain to the risks of enrolling either aninadequate number of subjects or more subject's than theminimum necessary to reject the null hypothesis. In bothinstances, the risks include randomizing the care of subjectsand/or exposing them to unnecessary risk/harm. • Thescientificreasons pertain to the enrollment of more subjectsthan necessary because it extends the duration ofand increases the costs of clinical research studies.
Sample Size • Study design depends on; • Variables of interest type of data e.g. continuous, categorical • Desired power • Desired significance level • Effect/difference of clinical importance • Standard deviations of continuous outcome variables • One or two-sided tests
Tools to Calculate Sample Size • Formula • General formula: these can be complex • Quick formula: for particular power and significance levels and specified tests • Special Tables for different tests • Altman’s Nomogram • Computer Software
Application-2 • Study effect of new sleep aid • 1 sample test • Baseline to sleep time after taking the medication for one week • Two-sided test, α = 0.05, power = 90% • Difference = 1 (4 hours of sleep to 5) • Standard deviation = 2 hr • Sample size can be calculated as follow:
Application-2 • Change Effect or Difference • Change difference of interest from 1hr to 2 hr • n goes from 43 to 11 • Change Power • Change power from 90% to 80% • n goes from 11 to 8
Application-2 • Change Standard Deviation • Change the standard deviation from 2 to 3 • n goes from 8 to 18
Application-2 • Changes in the detectable difference have HUGE impacts on sample size • 20 point difference → 25 patients/group • 10 point difference → 100 patients/group • 5 point difference → 400 patients/group • Changes in α, β, σ, number of samples, if it is a 1- or 2-sided test can all have a large impact on your sample
Conclusion • Sample-size planning is often important, and almost always difficult. It requires care in eliciting scientificobjectives and in obtaining suitable quantitative information prior to the study. Successful resolution of thesample-size problem requires the close and honest collaboration of statisticians and subject-matter experts. • Power and sample size analysis based on pilot data give valuable information on the performanceof the experiment and can thereby guide further decisions on experimental design.
Conclusion • Researchers can use these calculations as a tool to increase the strength of their inferences, and editors and reviewers to demand that statistical power be reported in all cases where a non-significant result is obtained.