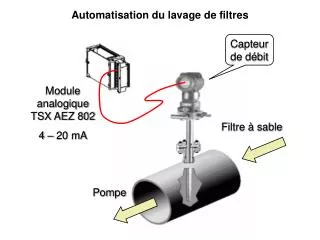
Download
1 / 29
300 likes | 520 Views
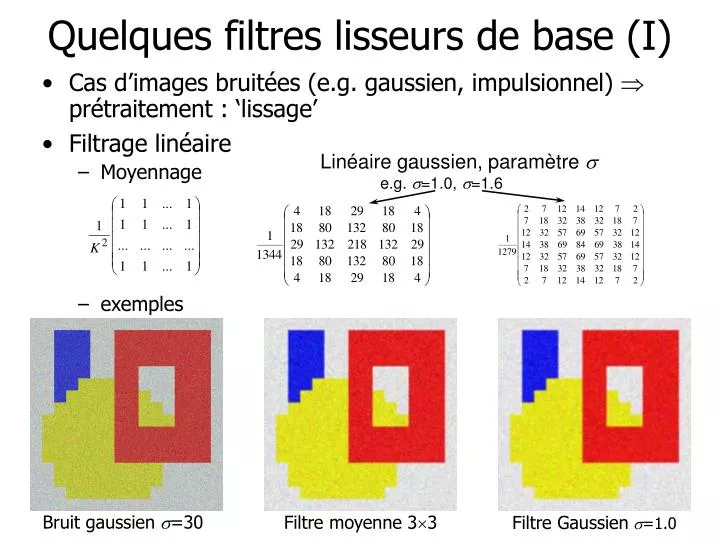
Linéaire gaussien, paramètre s e.g. s =1.0, s =1.6. Bruit gaussien s =30. Filtre moyenne 3 3. Filtre Gaussien s =1.0. Quelques filtres lisseurs de base (I). Cas d’images bruitées (e.g. gaussien, impulsionnel) prétraitement : ‘lissage’ Filtrage linéaire Moyennage exemples.

E N D
Linéaire gaussien, paramètre se.g. s=1.0, s=1.6 Bruit gaussiens=30 Filtre moyenne 33 Filtre Gaussiens=1.0 Quelques filtres lisseurs de base (I) • Cas d’images bruitées (e.g. gaussien, impulsionnel) prétraitement : ‘lissage’ • Filtrage linéaire • Moyennage • exemples
Bruit gaussiens=30 Filtre de Nagao Filtre médian 33 Quelques filtres lisseurs de base (II) • Filtrage non linéaire • De Nagao • SNN (Symetric Nearest Neighbor) • Filtrage d’ordre • Médian (p pixels, p≤|Vs|) Algorithme : 1) Calcul de l’histogramme sur le voisinage Vs 2) Tri des valeurs du voisinage 3) Sélection E le plus compact |E|=p 4) Sélection de la valeur de E à l’ordre considéré
Image non bruitée Gaus. s=20 filtre gaus. s=2.5 s=20 + ‘S&P’ 10% filtre Nagao ‘S&P’ 10% filtre médian 7x7 Bruit gaussien s=20
Filtrage : exercices • Que font les filtres à noyau de convolution suivants (prenez un exemple numérique si nécessaire) • Quelle est la condition sur les coefficients pour que le filtrage soit passe-bas • Décomposer le filtre 2D de noyau sous forme du produit de convolution de 2 filtres 1D • En déduire un moyen efficace, en nombre d’opérations par pixel, d’implémenter les filtres précédents
Détection de contours :approche générale • Objectif • Méthodes dérivatives Utilisation du gradient Calcul de l’image du gradient Calcul de l’image de la norme du gradient Calcul de l’image de la direction du gradient Seuillage (avec hystérésis) de l’image de la norme du gradient Elimination des non maxima locaux dans la direction du gradient Fermeture des contours Utilisation du laplacien Calcul de l’image du laplacien Calcul de l’image de la norme du gradient Calcul de l’image binaire Iz des passages par zéro du laplacien Application du masque binaire Iz à l’image de la norme du gradient Seuillage (avec hystérésis) de l’image de la norme du gradient |Iz Elimination des non maxima locaux dans la direction du gradient Fermeture des contours
, par filtrage linéaire passe-haut • Gradient Sobel c=2 Prewitt c=1 Opérateur MDIF • Laplacien 4-connexité 8-connexité
et morphologiques • Dilatation / érosion de fonctions • Cas particulier g(x)=0 xRnD • Propriétés Croissance par rapport à f, Extensivité / anti-extensivité (si origine incluse dans support de g), Croissance / décroissance par rapport à g, Commutations. • Opérateurs ‘différence d’opérateurs’ • Gradient intérieur, grad. extérieur • Gradient morphologique • Laplacien morphologique • Convergence vers gradient et laplacien euclidiens si élément structurant = boule eucl. centrée et rayon 0
Filtre de lissage puis application d’un opérateur différentiel par filtrage optimal (I) • Critères de Canny (i) Bonne détection, (ii) bonne localisation, (iii) faible multiplicité des maxima dus au bruit Filtre impulsionnel à réponse finie (RIF) • Filtre de Deriche : RII Dérivée directionnelle en x = Image*h(x)*f(y) Dérivée directionnelle en y = Image*h(y)*f(x) • Filtre de Shen - Castan
par filtrage optimal (II) • Implantation du filtre de dérivation de Deriche Décomposition entre 1 partie causale et 1 anti-causale • R1[i]=c.e-a.I[i-1]+2.e-a.R[i-1]-e-2a.R[i-2] R2[i]=-c.e-a.I[i+1]+2.e-a.R[i+1]-e-2a.R[i+2] R[i]=R1[i]+ R2[i] • Implantation du filtre de lissage de Deriche Décomposition entre 1 partie causale et 1 anti-causale • R1[i]= b.I[i]+ b.e-a.(a-1).I[i-1]+2.e-a.R[i-1]-e-2a.R[i-2] R2[i]= b.e-a.(a+1).I[i+1]-b.e-2a.I[i+2]+2.e-a.R[i+1]-e-2a.R[i+2] R[i]=R1[i]+ R2[i]
B1 B2 || MM (B2) || MM (B1) || Prewitt || MDIF || Sobel DMM (B1) D MM (B2) Dmasque Deriche a=1 Deriche a=2 Deriche a=3 Shen b=0.5 Shen b=1 Exemples de et .
(i-1,j+1) (i,j) (i,j+1) (i,j-1) (i+1,j-1) Détection de contours • Seuillage avec hystérésis • Détection des pixels de valeur ≥ sh • Ajout des pixels de valeur ≥ sbet qui 1 composante connexe ayant au moins 1 pixel de valeur ≥ sh (utilisat° d’1 pile pour créer les composantes connexes) • Détection des maxima locaux de la norme du gradient dans la direction du gradient q Autres cas :
3 2 1 3 2 1 4 0 4 0 5 6 7 5 6 7 3 2 1 4 0 5 6 7 Fermeture de contours • Construction d’1 « look-up table » permettant d’indexer les pixels candidats à la fermeture pour chaque configuration. Codage configuration : où xi=1 si contour, 0 sinon Ex. T[16]=1 ; T[136]=1 ; T[8]=1 • Algorithme de fermeture : • Pour chaque extrémité trouvée lors du balayage de l’image : • Construction du sous-arbre de tous les chemins possibles de longueur p et du coût associé à chaque nœud : somme des normes des gradients en chaque point du chemin • Sélection du nœud de coût maximum • Prolongation du contour
Après fermeture de contours Prewitt MDIF Sobel Dmasque Deriche a=1 Deriche a=2 Deriche a=3 Shen b=0.5 Shen b=1 Exemple
Contours : exercices (I) • Pour la norme du gradient, on utilise l’une des trois normes suivantes : Comparer les valeurs obtenues par N1, N2 et N3 si l’on calcule le gradient discret avec D2x=[-1 0 1] et D2y=t[-1 0 1] Même question si le gradient discret est obtenu l’application du filtre de Sobel En déduire que N3 est la norme la mieux adaptée dans le premier cas, et N1 ou N2 dans le deuxième cas. • Ecrire les équations aux différences pour les 3 masques utilisés pour estimer le laplacien discret :
Contours : exercices (II) • Calculer le gradient et le laplacien morphologique dans les cas d’images suivants : Interpréter et commenter • Effectuer un seuillage avec hystérésis sur : • Donner les formules d’interpolation des gradients en M1 et M2 pour la détection des maxima locaux de la norme du gradient dans la direction du gradient q, pour les différents cas deq
Classification : objectifs • Mettre en évidence les similarités/ dissimilarités entre les ‘objets’ (e.g. pixels) • Obtenir une représentation simplifiée (mais pertinente) des données originales Définitions préalables • Espace des caractéristiquesd (sS, ysd) • Espace de décision = ensemble des classesW (sS, xsW), W = {wi, i[1,c] } • Règle de décision ( =d(ys) ) • Critère de performance
1-ppv 3-ppv 5-ppv k-ppv (/24) Ex. de classification non paramétrique • Classification k-ppv (plus proches voisins) On dispose d’un ensemble (de ‘référence’) d’objets déjà labelisés Pour chaque objet y à classifier, on estime ses k ppv selon la métrique de l’espace des caractéristiques, et on lui affecte le label majoritaire parmi ses k ppv Possibilité d’introduire un rejet (soit en distance, soit en ambiguïté) Très sensible à l’ensemble de référence • Exemples :
Connaissance des caractéristiques des classes • Cas supervisé • Connaissance a priori des caractéristiques des classes • Apprentissage à partir d’objets déjà étiquetés (cas de données ‘complètes’) • Cas non supervisé • Définition d’un critère, ex. : - minimisation de la probabilité d’erreur - minimisation de l’inertie intra-classe maximisation de l’inertie inter-classes • Définition d’un algorithme d’optimisation
Estimation de seuils (cas supervisé) • Image = ensemble d’échantillons suivant une loi de distribution de paramètres déterminés par la classe ex. : distribution gaussienne • Cas 1D (monocanal), si seuil de séparation des classes wi et wi+1, probabilité d’erreur associée : • Maximum de vraisemblance • Maximum A Posteriori
s=30 s=60 c=2 c=3 c=4 c=5 Algorithme des c-moyennes (cas non sup.) • Initialisation (itération t=0) : choix des centres initiaux (e.g. aléatoirement, répartis, échantillonnés) • Répéter jusqu’à vérification du critère d’arrêt : • t++ • Labelisation des objets par la plus proche classe • Mise à jour des centres par minimisation de l’erreur quadratique : • Estimation du critère d’arrêt (e.g. test sur #ch(t) ) Remarques : • # de classes a priori • Dépendance à l’initialisation
Classification : exercices (I) Soit l’image à deux canaux suivante : • Soit les pixels de référence suivants : label 1 : valeurs (1,03;2,19) (0,94;1,83) (0,59;2,04) label 2 : valeurs (2,08;0,89) (2,23;1,16) (1,96;1,14) Effectuer la classification au k-ppv. Commentez l’introduction d’un nouveau pixel de référence de label 1 et de valeurs (1,32;1,56)
Classification : exercices (II) Sur l’image à deux canaux précédente : • Déterminer les seuils de décision pour chacun des canaux si l’on suppose 2 classes gaussiennes de caractéristiques respectives : canal 1 : (m1,s1)=(2.0,0.38), (m2,s2)=(1.0,0.34) canal 2 : (m1,s1)=(1.0,0.36), (m2,s2)=(2.0,0.39) Effectuer la classification par seuillage. • Effectuer la classification c-means pour c=2 Comparer avec les résultats précédents Comparer avec la classification c-means pour c=3 • Que pensez-vous de rajouter un terme markovien ? Considérez le cas d’un seul canal, ou celui des deux canaux utilisés de façon conjointe.
Classification bayésienne d’images Formulation du problème • Les images observées correspondent à la réalisation y d’un champ aléatoire Y = {Ys, sS}, S ensemble des ‘sites’, |S| = pixels, Ys ; • un autre champ aléatoire X= {Xs, sS}, celui des ‘étiquettes’ ou ‘labels’ des classes, dont la réalisation x est cachée, XsW, |W| = labels ou classes ; • Le but de la classification est d’accéder à x connaissant y. • Avant les modèles markoviens • Calcul de la fonction de décision optimale pour estimer x sachant y irréalisable simplifications : • Pour tout sS, estimation de xs sachant ys classification aveugle, • Pour tout sS, estimation de xs sachant {ys, sVS} classifications contextuelles
Définition des interactions locales déf. d’un système de ‘voisinage’ : • Et du système de ‘cliques’ associé, i.e. soit singletons, soit ensembles de sites tous voisins les uns des autres 4-connexité : 8-connexité : Cliques d’ordre 2 Cliques d’ordre 3 Cliques d’ordre 4 Modèles markoviens Pb : estimer x connaissant y définir : (i) un modèle ‘d’attache aux données’, i.e. reliant X et Y, ET (ii) un modèle a priori pour X, i.e. favorisant certains types de solutions Modélisation des interactions (locales) entre les sites
Champs de Markov – champs de Gibbs • X est un champ de Markov où • X est un champ de Gibbs de potentiel associé au système de voisinage Vs, sS avec (C ens. cliques)
Exemple de distribution a posteriori • Y gaussien conditionnellement aux classes • Loi a priori = modèle de Potts b(i,j) = b P(X=x / Y=y) = P(Y=y / X=x).P(X=x)/P(Y=y)
Estimation du MAP (I) • Recuit simulé (Kirkpatrick, 1983) sur algorithme de Métropolis A partir de x0 la configuration initiale, et de T la température initiale, Répéter tant que le compteur est >t et T0 : xk étant la config. courante • Mettre le compteur à 0 • Pour tous les sites s S : • tirer ls selon la loi uniforme dans W, • poser xt = xtk, tS:ts, et xs = ls, • calculer DU= • si DU < 0 alors • sinon : • tirer z selon la loi uniforme dans [0,1] • si z < exp(- DU / T), alors • si xsk+1 xsk incrémenter le compteur de 1 • Poser T = a.T
Estimation du MAP (II) • Recuit simulé sur échantillonneur de Gibbs A partir de x0 la configuration initiale, et de T la température initiale, Répéter tant que le compteur est >t et T0 : xk étant la config. courante • Mettre le compteur à 0 • Pour tous les sites s S : • poser xt = xtk, et xtk+1 = xtktS:ts, • Pour chaque i de W, • poser xs = i, • calculer pi = • tirer z selon la loi uniforme dans [0,1], • Trouver j minimum tel que • Poser xsk+1 = j, • si xsk+1 xsk incrémenter le compteur de 1 • Poser T = a.T