Download

1 / 24
250 likes | 379 Views
CSE403 Software Engineering Autumn 2001 Finding the Bugs. Gary Kimura Lecture #12 October 26, 2001. Today. ABET Two quick questions Was Wednesday’s group meeting time helpful? Was Thursday’s discussion helpful? Group design reviews next week What is a bug?

E N D
CSE403 Software EngineeringAutumn 2001Finding the Bugs Gary Kimura Lecture #12 October 26, 2001
Today • ABET • Two quick questions • Was Wednesday’s group meeting time helpful? • Was Thursday’s discussion helpful? • Group design reviews next week • What is a bug? • How do we discover if a bugs exists? • How do we classify bugs? • How do we find the code that causes the bug? • I’m going to talk beyond most of the simple debugger supplied techniques for finding bugs.
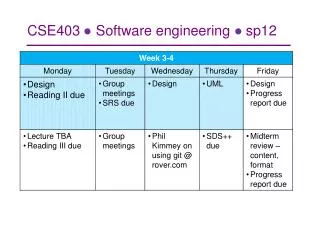
Group Design Reviews • Plan for 40 minutes of presentation be ready to go on Thursday • Plan as if this is a presentation to your company President and that your three levels removed from her • Recap your requirements (include a list of deliverables) • Layout the overall design • Tunnel down in the design as necessary to explain concepts that may not be evident • Go over the testing and documentation plan • Give a schedule
What is a bug? • A bug can be anything from odd or unexpected behavior to system crashes or wrong answers. • Not everything is a bug and people often disagree about particular bugs. • Not only do they disagree if a particular behavior is a bug they fervently disagree about where and how the problems should be fixed. • All large system projects ship with bugs. • It cannot be avoided. • After a product ships it seems that all the bugs become features!
How do we discover bugs? • To paraphrase Dave Cutler, “if you don’t put them in then you don’t have to take them out.” • I believe that what he’s saying is that the more care that is taken when designing and writing code the fewer bugs there will be • But there will always be bugs, so how do we discover them • normal usage, • regression testing, • stress testing, and • guerilla testing. • We need to find and remove bugs early otherwise other code can become depend on the bugs’ behavior • malloc of zero bytes
After we ship • By the time the product gets into the hands of the customer it is often too late to fix problems. • But still you should expect customers to find help find bugs, that’s one reason why there are beta programs • If a product ships with a bug and users start depending on the “buggy” behavior then fixing the bug in later release becomes problematic
Prioritize bugs • It is important to know the relative priority of bugs, based on various criteria • The severity of the bug • The likelihood that the customer will encounter the bug • The risk involved with doing the fix versus the risk involved without fixing the bug • Risk to the schedule including redesign and testing • End user education and product support costs • Sometimes we let the engineer privately test the fix but still not take the fix into the product • Is it too close to shipping • Leave it for the next version (i.e., if it doesn’t become a feature)
Finding bugs • Some bugs are easy to find while a lot of bugs are hard to find • We demonstrate the existence of a particular bug through • System crashes which usually highlight a bug someplace • Application or APIs that return the wrong or unexpected answer • Normal usage (“dogfood”) can illustrate bugs • Code reviews can uncover bugs
Various test scenarios can expose bugs • Usage tests • Stress test • Validation tests • Regression tests • Black box and white box testing • Fault injection (for example, I/O errors, allocation errors) • This latter case is often overlooked as a good way to stress test code
How do we catch or find the bugs • Reproducible behavior • Trying to get the problem to reproduce is sometimes the hardest part. • How to reproduce the bug? • If it only reproduces within a huge stress scenario where do I go then? • There are a lot of jokes about software engineers always wanting to see if the problem reproduces. • The main problem with finding bugs is that it is not always obvious from the crash or incorrect behavior where the bug is located • Narrowing down on the problem is often very hard. • There are often times when a private build is all that is needed to find the problem, but • Other times we need to subject special catcher code to the public build.
Catching bugs • Once we have an idea of a bug’s existence we have various ways to find or catch it • Sometimes it’s obvious what the problem is and sometimes it is not. • Some techniques used to catch bugs are • Watch points and break points • Check builds • Procedure call tracing and PC tracing • Memory consistency checks • And many more • Unfortunately some bugs seem to know when they are being chased and go into hiding
Watch points and break points • Watch points and break points are probably one of the most common debugging tools beyond simply adding prints to your program or stepping through the program within a debugger • The downside with prints and debuggers is • They alter the behavior of the program • They can take a long time to run • Watch points and break points • Catch read and/or write to certain memory locations • Stop a program when it reaches a certain instruction • But they can still alter program behavior • Great debugging aids when available. Sometimes they are not available.
Check builds • Checked builds with extra sanity checking such as asserts. • The good thing about doing this is that when you originally write the program you can add consistency checks. The bad part of doing this is that you wind up with two system, almost the same but not really • Different size and timing • Different side affects
Procedure call tracing and PC tracing • Procedure call tracing following all the function calls used when the program executes • PC tracing takes Procedure call tracing to the machine instruction level • Can be used to see where programs are spending their time and subsequently help in understanding the behavior of the program • For example, “Gee how did my program get into this infinite loop?”
Memory Consistency checks • Filling freed and uninitialized memory with a known bit pattern • Can help identify code that touches memory after it is freed or using uninitialized memory. Patterns such as deadbeef and baadf00d are usable
Timing bugs • Timing problems are very hard to find, especially on an MP machine. Here are some examples I’ve seen • Software cache and MM problems to resolve and page-in files has a lot of timing issues • Memory leaks in a single threaded application are hard enough to locate, but add a multi-threaded MP application and it becomes even harder. One technique is to keep tracing information for each allocated and freed item • Probing problems are doubly harder to tackle when you can have an application that remap memory used by another thread
One particularly nasty timing related bug • In NT RtlZeroMemory and RtlCopyMemory on a MIPS architecture used the floating point registers to speed them up. However, • The floating point registers were not being saved on an interrupt and so • If either operation was called in an interrupt handler problems can and did occur. • We stumbled upon this case when RtlZeroMemory was being interrupted and the interrupt handler also called RtlCopyMemory. • This was not an MP problem but really an interrupt problem.
Deadlocks • Static deadlocks are usually easy to identify (fixing is another matter) but • Dynamic deadlocks and priority inversion are a lot harder to identify. Which is really another topic of “Is the system hung or just slow?”
More ways to catch bugs • Pointer bias on RISC machines can catch code going through pointers they shouldn’t be using • Keeping page zero invalid also makes referencing through NULL essentially a runtime error, but not always because of large offsets. • On problems that are not easily reproducible we sometimes need to add code in the dog food system that runs on everyone’s machine
More bug catchers • Here are some of the things I’ve done or seen done to find the bug • Keep a history of every allocation and freeing of memory • Keep a history of every file operation • Add special case code to see if a particular file name is ever used. In one particular MP cache problem we had to add code to check the contents of the buffer we are writing out • Every time an internal data structure is used or altered we do pre and post examinations of the structures • Once had the debugger dump all of physical memory, searching for a pattern
Bugs outside of our control • Sometimes it’s a compiler bug. Ugh! • Sometimes it’s an operator or hardware error • Unplugging the SCSI disk in the middle of an operation is typically pretty bad • I’ve seen improperly terminated buses cause unreported I/O errors • Non-parity memory does go bad without warning • One MIPS hardware error had to do with branch instructions are the end of a page
Summary • Finding bugs is an inexact science • Requires a sixth sense and a good nose • Tenacity is key • There are techniques that help locate bugs, but sometime the catchers move or perturb the bug. • Bugs sometimes mask other bugs • For example, if one particular bugs crashes the system in 20 minutes. Then the 49 other bugs haven’t had a chance yet to be discovered
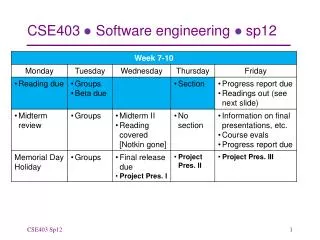
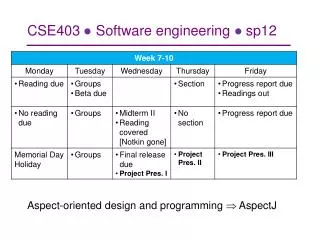
Next time • Fixing bugs • More than just fixing the code is at stake here