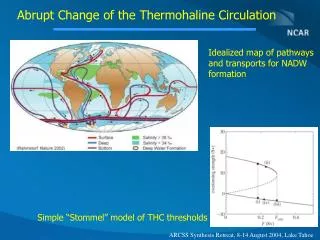
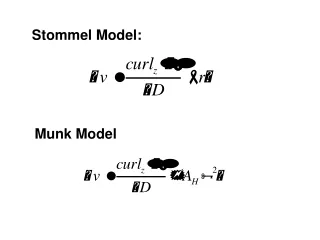
Download

1 / 10
100 likes | 263 Views
Stommel model with OpenMP. Stommel model with OpenMP. A good case for using loop level parallelism. Most calculation is done inside a loop No dependency between iterations A lot of work in each iteration Subroutine do_jacobi(psi,new_psi,diff,i1,i2,j1,j2) ... do j=j1,j2 do i=i1,i2

E N D
Stommel model with OpenMP A good case for using loop level parallelism. • Most calculation is done inside a loop • No dependency between iterations • A lot of work in each iteration Subroutine do_jacobi(psi,new_psi,diff,i1,i2,j1,j2) ... do j=j1,j2 do i=i1,i2 new_psi(i,j)=a1*psi(i+1,j) + a2*psi(i-1,j) + & a3*psi(i,j+1) + a4*psi(i,j-1) - a5*force(i,j) diff=diff+abs(new_psi(i,j)-psi(i,j)) enddo enddo psi(i1:i2,j1:j2)=new_psi(i1:i2,j1:j2)
Serial program IBM: compile with xlf90 –O3 stf_00.f –o stf_00 Using standard input: 200 200 2000000 2000000 1.0e-9 2.25e-11 3.0e-6 75000 Without write_grid routine, running time on Blue Horizon, 1 node, 1 CPU: 83.5 sec
OpenMP parallelization, version 1 • Put directive around outer loop • diff is a reduction variable • We want i to be private $OMP PARALLEL DO private(i) reduction(+:diff) do j=j1,j2 do i=i1,i2 new_psi(i,j)= a1*psi(i+1,j) + a2*psi(i-1,j) + & a3*psi(i,j+1) + a4*psi(i,j-1) - & a5*for(i,j) diff=diff+abs(new_psi(i,j)-psi(i,j)) enddo enddo
OpenMP parallelization, version 1, cont. Compile on IBM: xlf90_r –O3 –qsmp=noauto:omp stf_00.f Running time on 8 threads: setenv OMP_NUM_THREADS 8 poe a.out < st.in –nodes 1 –tasks_per_node 1 –rmpool 1 Runtime: 102.7 sec (compare with serial time of 83.4 sec) WHAT HAPPENED???
OpenMP parallelization, version 1, cont. Let’s look at the code again: $OMP PARALLEL DO private(i) reduction(+:diff) do j=j1,j2 do i=i1,i2 new_psi(i,j)= a1*psi(i+1,j) + a2*psi(i-1,j) + & a3*psi(i,j+1) + a4*psi(i,j-1) - & a5*for(i,j) diff=diff+abs(new_psi(i,j)-psi(i,j)) enddo enddo psi(i1:i2,j1:j2)=new_psi(i1:i2,j1:j2) The last line was not parallelized – array syntax is not yet recognized. Also, the program probably spent much time in synchronization after the do loops. SOLUTION: another directive.
OpenMP parallelization, version 2 New version: $OMP PARALLEL DO private(i) reduction(+:diff) do j=j1,j2 do i=i1,i2 psi(i,j) = new_psi(i,j) enddo enddo Runtime on 8 CPUs: 17.3 sec A much better result
Our final subroutine:header subroutine do_jacobi(psi,new_psi,diff,i1,i2,j1,j2) use numz use constants implicit none integer,intent(in) :: i1,i2,j1,j2 real(b8),dimension(i1-1:i2+1,j1-1:j2+1):: psi real(b8),dimension(i1-1:i2+1,j1-1:j2+1):: new_psi real(b8) diff integer i,j real(b8) y diff=0.0_b8
Important part !$OMP PARALLEL DO private(i) reduction(+:diff) do j=j1,j2 do i=i1,i2 new_psi(i,j)=a1*psi(i+1,j) + a2*psi(i-1,j) + & a3*psi(i,j+1) + a4*psi(i,j-1) - & a5*for(i,j) diff=diff+abs(new_psi(i,j)-psi(i,j)) enddo enddo !$OMP END PARALLEL DO ! psi(i1:i2,j1:j2)=new_psi(i1:i2,j1:j2) !$OMP PARALLEL DO private(i) do j=j1,j2 do i=i1,i2 psi(i,j)=new_psi(i,j) enddo enddo !$OMP END PARALLEL DO end subroutine do_jacobi
Summary • Using two OpenMP directives allowed to achieve reasonable scaling • Need to be careful with variable scopes • OpenMP compilers still rather immature