Download

1 / 29
360 likes | 687 Views
Estimating Demand Chapter 4. A chief uncertainty for managers is the future. Managers fear what will happen to their product. Managers use forecasting, prediction & estimation to reduce their uncertainty.

E N D
Estimating Demand Chapter 4 • A chief uncertainty for managers is the future. Managers fear what will happen to their product. • Managers use forecasting, prediction & estimation to reduce their uncertainty. • The methods that they use vary from consumer surveys or experiments at test stores to statistical procedures on past data such as regression analysis. • Objective of the Chapter: Learn how to interpret the results of regression analysis based on demand data.
Demand Estimation Using Marketing Research Techniques • Consumer Surveys • ask a sample of consumers their attitudes • Consumer Focus Groups • experimental groups try to emulate a market (but beware of the Hawthorne effect = people often behave differently in when being observed) • Market Experiments in Test Stores • get demand information by trying different prices • Historical Data- what happened in the past is guide to the future using statistics is an alternative
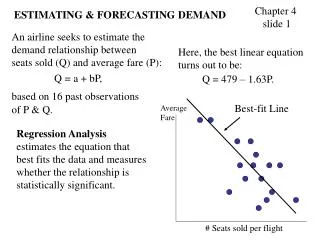
Statistical Estimation of Demand Functions:Plot Historical Data Price • Look at the relationship of price and quantity over time • Plot it • Is it a demand curve or a supply curve? • The problem is this does not hold other things equal or constant. Is this curve demand or supply? 2004 2007 2010 2009 2006 2005 2008 quantity
Statistical Estimation of Demand Functions • Steps to take: • Specification of the model-- formulate the demand model, select a Functional Form • linear Q = a + b•P + c•Y • double log log Q = a + b•log P + c•log Y • quadratic Q = a + b•P + c•Y+ d•P2 • Estimate the parameters-- • determine which are statistically significant • try other variables & other functional forms • Develop forecastsfrom the model
Specifying the Variables • Dependent Variable-- quantity in units, quantity in dollar value (as in sales revenues) • Independent Variables-- variables thought to influence the quantity demanded • Instrumental Variables -- proxy variables for the item wanted which tends to have a relatively high correlation with the desired variable: e.g., TastesTime Trend
Functional Forms: Linear • Linear ModelQ = a + b•P + c•Y • The effect of each variable is constant, as in Q/P = b and Q/Y = c, where P is price and Y is income. • The effect of each variable is independent of other variables • Price elasticity is: ED = (Q/P)(P/Q) =b•P/Q • Income elasticity is: EY = (Q/Y)(Y/Q)=c•Y/Q • The linear form is often a good approximation of the relationship in empirical work.
Functional Forms: Multiplicative or Double Log • Multiplicative Exponential ModelQ = A • Pb • Yc • The effect of each variable depends on all the other variables and is not constant, as in Q/P = bAPb-1Yc and Q/Y = cAPbYc-1 • It is double log (log is the natural log, also written as ln) Log Q = a + b•Log P + c•Log Y • the price elasticity, ED = b • the income elasticity, EY = c • This property of constant elasticity makes this approach easy to use and popular among economists.
A Simple Linear Regression Model Y • Yt = a + b Xt + t • time subscripts & error term • Find “best fitting” line t = Yt - a - b Xt t2 = [Yt - a - b Xt] 2 . • mint 2= [Yt - a - b Xt] 2 . Solution: slope b = Cov(Y,X)/Var(X)and intercept a = mean(Y) - b•mean(X) a _ Y DY DX _ X
Simple Linear Regression:Assumptions & Solution Methods • The dependent variable is random. • A straight line relationship exists. • The error term has a mean of zero and a finite variance: the independent variables are indeed independent. • Spreadsheets - such as • Excel, Lotus 1-2-3, Quatro Pro, or Joe Spreadsheet • Statistical calculators • Statistical programs such as • Minitab • SAS • SPSS • For-Profit • Mystat
Assumption 3: Error Term Has A Mean Of Zero And A Finite Variance
Assumption 3: Error Term Has A Mean Of Zero And A Finite Variance
FIGURE 4.4 Deviation of the Observations about the Sample Regression Line
Sherwin-Williams Case • Ten regions with data on promotional expenditures (X) and sales (Y), selling price (P), and disposable income (M) • If look only at Y and X: Result: Y = 120.755 + .434 X One use of a regression is to make predictions. • If a region had promotional expenditures of 185, the prediction is Y = 201.045, by substituting 185 for X • The regression output will tell us also the standard error of the estimate, se . In this case, se = 22.799 • Approximately 95% prediction interval is Y ± 2 se. • Hence, the predicted range is anywhere from 155.447 to 246.643.
T-tests • Different samples would yield different coefficients • Test the hypothesis that coefficient equals zero • Ho: b = 0 • Ha: b 0 RULE: If absolute value of the estimated t>Critical-t, then REJECT Ho. • We say that it’s significant! • The estimated t = (b - 0) / b • The critical t is: • Large Samples, critical t2 • N > 30 • Small Samples, critical t is on Student’s t Distribution, page B-2 at end of book, usually column 0.05, & degrees of freedom. • D.F. = # observations,minusnumber of independent variables, minus one. • N < 30
Sherwin-Williams Case • The estimated t is: • t = (.434 – 0 )/.14763 = 2.939 • The critical t for a sample of 10, has only 8 degrees of freedom • D.F. = 10 – 1 independent variable – 1 for the constant. • Table B2 shows this to be 2.306 at the .05 significance level • Therefore, |2.939| > 2.306, so we reject the null hypothesis. • We informally say, that promotional expenses (X) is “significant.” • In the simple linear regression: Y = 120.755 + .434 X • The standard error of the slope coefficient is .14763. (This is usually available from any regression program used.) • Test the hypothesis that the slope is zero, b=0.
USING THE REGRESSION EQUATIONTO MAKE PREDICTIONS • A regression equation can be used to make predictions concerning the value of Y, given any particular value of X. • A measure of the accuracy of estimation with the regression equation can be obtained by calculating the standard deviation of the errors of prediction (also known as the standard error of the estimate).
Correlation Coefficient • We would expect more promotional expenditures to be associated with more sales at Sherwin-Williams. • A measure of that association is the correlation coefficient, r. • If r = 0, there is no correlation. If r = 1, the correlation is perfect and positive. The other extreme is r = -1, which is negative.
Analysis of Variance • R-squared is the percentage of the variation in dependent variable that is explained • As more variables are included, R-squared rises • Adjusted R-squared, however, can decline • Adj R2 = 1 – (1-R2)[(N-1)/(N-K)] • As K rises, Adj R2 may decline. Y ^ Yt ^ Yt predicted _ Y _ X X
Association and Causation • Regressions indicate association, but beware of jumping to the conclusion of causation • Suppose you collect data on the number of swimmers at a local beach and the temperature and find: • Temperature = 61 + .04 Swimmers, and R2 = .88. • Surely the temperature and the number of swimmers is positively related, but we do not believe that more swimmers CAUSED the temperature to rise. • Furthermore, there may be other factors that determine the relationship, for example the presence of rain or whether or not it is a weekend or weekday. • Education may lead to more income, and also more income may lead to more education. The direction of causation is often unclear. But the association is very strong.
Multiple Linear Regression • Most economic relationships involve several variables. We can include more independent variables into the regression. • To do this, we must have more observations (N) than the number of independent variables, and no exact linear relationships among the independent variables. • At Sherwin-Williams, besides promotional expenses (PromExp), different regions charge different selling prices (SellPrice) and have different levels of disposable income (DispInc) • The next slide gives the output of a multiple linear regression, multiple, because there are three independent variables
Figure 4.8Computer Output: Sherwin-Williams Company Dep var: Sales (Y) N=10 R-squared = .790 Adjusted R2 = .684 Standard Error of Estimate = 17.417 Variable Coefficient Std error T P(2 tail) Constant 310.245 95.075 3.263 .017 PromExp .008 0.204 0.038 .971 SellPrice -12.202 4.582 -2.663 .037 DispInc 2.677 3.160 0.847 .429 Analysis of Variance Source Sum of Squares DF Mean Squares F p Regression 6829.8 3 2276.6 7.5 .019 Residual 1820.1 6 303.4
Interpreting Multiple Regression Output • Write the result as an equation: Sales = 310.245 + .008 ProExp -12.202 SellPrice + 2.677 DispInc • Does the result make economic sense? • As promotion expense rises, so does sales. That makes sense. • As the selling price rises, so does sales. Yes, that’s reasonable. • As disposable income rises in a region, so does sales. Yup. That’s reasonable. • Is the coefficient on the selling price statistically significant? • The estimated t value is given in Figure 4.8 to be -2.663 on SellPrice. • The critical t value, with 6 ( which is 10 – 3 – 1) degrees of freedom in table B2 is 2.447 • Therefore |-2.663| > 2.447, so reject the null hypothesis, and assert that the selling price is significant!
Soft Drink Demand Estimation A Cross Section Of 48 States Linear estimation yields:
Find The Linear Elasticities Cans = 159.17-102.56 Price +1.00 Income + 3.94 Temp Linear Specification write as an equation: • The price elasticity in Alabama is = (DQ/DP)(P/Q) = -102.56(2.19/200)= -1.123 • The price elasticity in Nevada is = (DQ/DP)(P/Q) = -102.56(2.19/166) = -1.353 • The price elasticity in Wisconsin is = (DQ/DP)(P/Q) = -102.56(2.38/97)= -2.516 • The estimated elasticities are elastic for individual states. • We can estimate the elasticity from the whole samples as: • (Q/P) (Mean P/Mean Q) = 102.56 x ($2.22/160) = -1.423, which is also elastic.