Download

1 / 27
280 likes | 778 Views
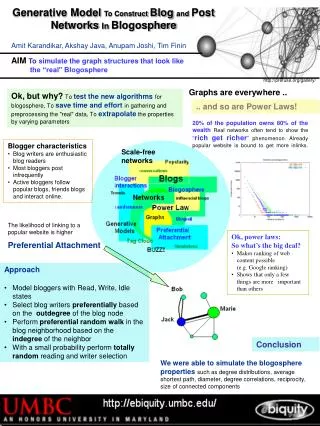
Generative Model To Construct Blog and Post Networks In Blogosphere Masters Thesis Defense Amit Karandikar Advisor: Dr. Anupam Joshi Committee: Dr. Finin, Dr. Yesha, Dr. Oates Date: 1 st May 2007 Time: 9:30 am Place: ITE 325B http://prefuse.org/gallery/ Outline Introduction Motivation

E N D
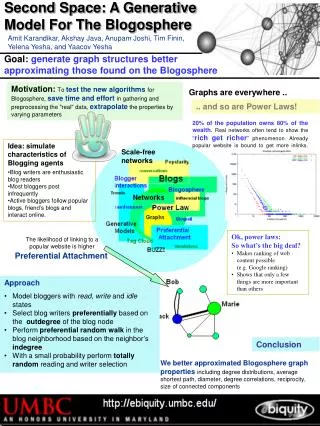
Generative Model To Construct Blog and Post Networks In Blogosphere Masters Thesis Defense Amit Karandikar Advisor: Dr. Anupam Joshi Committee: Dr. Finin, Dr. Yesha, Dr. Oates Date: 1st May 2007 Time: 9:30 am Place: ITE 325B http://prefuse.org/gallery/
Outline • Introduction • Motivation • Thesis Contribution • Interactions in Blogosphere • Proposed Model • Experiments and Results • Conclusion
Introduction Generative Model To Construct Blog and PostNetworks In Blogosphere Generative model: A generative model is a model for randomly / systematically generating the observed data using some input parameters. Parameters could be latent or input to the model. Blogosphere: Blogosphere is the collective term encompassing all blogs linked together forming as a community or social network. yesha.blogspot.com oates.myspace.com Blog network: Network formed by considering each blog single node. Post Network:Network formed considering post as a node; ignoring its parent blog. joshi.blogspot.com finin.livejournal.com
Basics .. Graphs are everywhere .. and so are Power laws!! In simple words, power law can be explained by “rich get richer phenomenon” OR “20% of the population holds 80% of the wealth” Considering web as a graph: Internet Mapping Project [lumeta.com] Friendship Network [Moody ‘01] Scale-free network: Structure and properties independent of network size Few high connectivity node (hubs) http://www.prefuse.org/gallery/ Properties of interest (graph theory) Average degree of node, degree distribution, degree correlation, distribution of strongly/weakly connected components, clustering coefficient and reciprocity
MotivationWhy simulate blog graphs? • Reduce time to generate data - crawling the blogosphere over a few weeks - sampling the right blogs to get a representative sample • Reduce time in preprocessing and data cleaning - removing links pointing outside the dataset, outside the time frame - splog removal [1] • Generate graphs of different properties\sizes - average degree of node, degree distributions • Testing of new algorithms for blog graphs - e.g. spread of influence in blogosphere [2], community detection [3] • Extrapolation - how will fast growth affect the blogosphere properties? - how does this affect the connected components? [1] Kolari et al “Svms for the blogosphere: Blog identification and splog detection,” in AAAI Spring Symposium on Computational Approaches to Analyzing Weblogs, 2006. [2] Java et al “Modeling the spread of influence on the blogosphere,” tech. rep., University of Maryland, Baltimore County, March 2006. [3] Lin et al “Discovery of Blog Communities based on Mutual Awareness
Thesis Contribution • To propose a generative model for a blog-blog network using preferential attachment and uniform random attachment by modeling the interactions among bloggers • To generate post-post network as part of the generative model for blog graphs. • Compare the properties of the simulated blog and post networks with the properties observed in the available real blog datasets. Datasets Workshop on the Weblogging Ecosystem (WWE 2006) http://weblogging2006.blogspot.com/ International Conference on Weblogs and Social Media (ICWSM 2007) http://ebiquity.umbc.edu/blogger/icwsm-2007-blogs-dataset/
Why existing models are not enough? Erdos-Renyi random model Barabasi Albert preferential attachment web model Preferential Attachment: The likelihood of linking to a popular website is higher • Two level network: blog and post level • Inlinks and outlinks to and from posts • NEED to model blogger interactions [1] M. Newman, “The structure and function of complex networks,” 2003 [3] R. Albert, Statistical mechanics of complex networks. PhD thesis, 2001. [7] J. Leskovec, M. McGlohon, C. Faloutsos, N. Glance, and M. Hurst, “Cascading behavior in large blog graphs”, ICWSM, 2007 [32] X. Shi, B. Tseng, and L. Adamic, “Looking at the blogosphere topology through different lenses” ICWSM, 2007
Interactions in blogosphere • Interesting findings from PEW Internet survey [1] - Blog writers are enthusiastic blog readers - Most bloggers post infrequently - Linking in the neighborhood: preferential or random? (friends blog, blogroll) • Blogger tend to link to some (how many?) of the posts that they read recently (often preferentially, sometimes random) • Is popularity (inlinks) proportional to blogger activity (outlinks)? [NO] [2] [1] A. Lenhart and S. Fox, “Bloggers: A portrait of the internet’s new storytellers.” [2] J. Leskovec, M. McGlohon, C. Faloutsos, N. Glance, and M. Hurst, “Cascading behavior in large blog graphs”, ICWSM 2007 Model parameters
Model Parameters • Probability of random reads (rR) • Probability of randomly selecting writer (rW) • Probability that new node does not link to the existing network (pD) • Growth exponent (g) – how many links should be added every step?
Proposed Model: Blog view 1. Add new blog node 2. Select writer 3. Writers read blog posts, write posts Step=1 I will not link to anyone! Reciprocal links Strongly connected componentsSubset of nodes having directed path from every node to every other node Weakly connected components Information flow Step=2 dailykos Should I read - randomly? - preferentially? michellemalkin Should I link to someone? If yes who? >> Preferentially based on indegree of node Writer selection: randomly? OR >> Preferentially based on outdegree? Random destination Random writer
Proposed Model: Post view Blogger A Blogger B Post 3 Post 2 Post 2 Post 1 Post 1 Number of links?
Growth of blog graphs: Densification Densification [1] has been observed in various real networks including blogosphere Number of edges grows faster than number of nodes: super linear growth function Reciprocity and clustering coefficient increase with growth exponent Average degree increases with growth (evolution time) [1] ] J. Leskovec, M. McGlohon, C. Faloutsos, N. Glance, and M. Hurst, “Cascading behavior in large blog graphs”, ICWSM 2007
Blogosphere: Blog Inlinks distribution Blogosphere follows power law distribution for blog inlinks and outlinks, post inlinks and post outlinks, component sizes, posts per blog, size of cascades … Large number of blog nodes have very few inlinks Power law distribution Slope = -2.07 Very few blog nodes have very high inlinks
Simulation: Blog Inlinks distribution Power law distribution Slope = -1.72 Similar curves are observed for properties of simulated blog and posts networks
Power law distributions for various network sizes Similar shape of curves for degree distributions as observed by Shi et al [1] in the “real” blogosphere. [1] X. Shi, B. Tseng, and L. Adamic, “Looking at the blogosphere topology through different lenses,” in ICWSM, 2007
Hop plotAverage neighborhood size Vs. Hop count Hop plot shows the reachability of nodes in the network After N hops, hop plot becomes constant Reachability? Comparison of hop plots for ICWSM, WWE and Blogosphere (650K blog nodes, 1.4 million links) pD = probability that new node remains disconnected
Simulation: Scatter plot and degree correlations Correlation Coefficients ICWSM: 0.056 WWE: 0.02 Simulation: 0.1 Popular blogs (high inlinks) Popular avid writers (high inlinks and outlinks) Avid writers (high outlinks) BA model correlation coefficient = 1 Random writers (rW) helps to model low correlation coefficient Correlation coefficient close to zero means there is NO definite relation between indegree and outdegree of blog nodes
Distribution of SCC in blog and post network (WWE and Simulation) Community detection, modeling influence uses connected components
Distribution of WCC in post network(WWE and Simulation) Power law distribution in WCC for post network
Simulation: Posts per blog distribution Posts per blog also follows a power law distribution [1] Power law distribution Slope = -1.71 [1] ] J. Leskovec, M. McGlohon, C. Faloutsos, N. Glance, and M. Hurst, “Cascading behavior in large blog graphs”, ICWSM 2007
Effect of increase in blogs Degree distributions almost the same Reciprocity increases Average degree increases Clustering coefficient and reciprocity of the post network is much less compared to the blog network
Effect of parametersRandom reads (rR), random writers (rW), disconnected nodes (pD) Increasing rR (random reads), decreases reciprocity because it reduces the likelihood of getting reverse link Empirically rW = 0.35 (random writers) gives low degree correlation and similar values for other parameters as the blogosphere Increasing pD reduces the size of largest WCC
Conclusion • Simulation resemblesblogosphere in degree distributions, degree correlations, reciprocity, average degree, clustering coefficient, component distribution for blog and post networks. • Simulated post network is sparse compared to blog network and posts per blogs follows a power law distribution as observed in blogosphere. • Useful tool for analysis of blogosphere, testing new algorithms and extrapolation (how will increase in X affect some Y?)
Future work • Can we model buzz and popularity in the post network? • What is the effect of buzz on the properties of the network? • In-depth temporal analysis of evolving blog graphs • Can we enrich the model with topical information? • How can we model the blogroll?
Questions? Thank you! Acknowledgements Advisor, committee members, coauthors, friends at UMBC Data BlogPulse, ICWSM, WWE