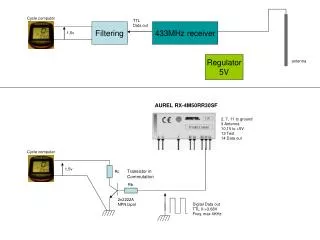
Download

1 / 9
90 likes | 194 Views
Filtering noisy continuous labeled examples. IBERAMIA 2002. José Ramón Quevedo María Dolores García Elena Montañés. A rtificial I ntelligence C entre Oviedo University (Spain). Index. 1. Introduction 2. The Principle 3. The Algorithm 4. Divide and Conquer 5. Experimentation

E N D
Filtering noisy continuous labeled examples IBERAMIA 2002 José Ramón Quevedo María Dolores García Elena Montañés Artificial Intelligence Centre Oviedo University (Spain)
Index 1. Introduction 2. The Principle 3. The Algorithm 4. Divide and Conquer 5. Experimentation 6. Conclusions
f(x) Good examples Noisy examples Machine Learning System x f(x) Noisy Continuous Labeled Examples Filter x Introduction INDEX INDEX 1.Introduction
Example: Step Function If removing a example gets an improvement in the k-cnn errors of the rest of examples in the data set, that example is, probably, a noisy one. With out e3 2-cnn error 1 1 1 e3 e6 0 With out e6 0 0 The Principle INDEX 1.Introduction INDEX 1.Introduction 2.The Principle If removing a example gets an improvement in the k-cnn errors of the rest of examples in the data set, that example is, probably, a noisy one. The examples whose neighbour is a noisy one would improve their k-cnn errors if the noisy example was removed.
for each example e sorted by more k-cnnError { if(k-cnnError(e)<=MinError) break; if(prudentNoisy(DS-{e}) DS=DS-{e} else break; } return DS; The Algorithm INDEX 1.Introduction 2.The Principle 3.The Algorithm INDEX 1.Introduction 2.The Principle Noisy Continuous Labeled Examples Filter Original Data Set Filtered Data Set
Filtered Data Set Original Data Set NCLEFDC Data SubSet Filtered SubSet NCLEF D&C Data SubSet Filtered SubSet NCLEF Divide and Conquer INDEX 1.Introduction 2.The Principle 3.The Algorithm 4.Divide & Conquer INDEX 1.Introduction 2.The Principle 3.The Algorithm Problem : High Computational Cost O(NCLEF)=N·O(LOO(A-cnn))=O(A2N3) • Solution : Use Divide & Conquer over the data set: • Split : choose a example with || ||1 that splits the • data set in two with similar number of examples • Stop : constant threshold: M, max. number of examples Result : O(NCLEFDC)=O(N·log(N)+NA2)
Experimental Results INDEX 1.Introduction 2.The Principle 3.The Algorithm 4.Divide & Conquer 5.Experimentation INDEX 1.Introduction 2.The Principle 3.The Algorithm 4.Divide & Conquer • Experimentation data Sets: Torgo’s Repository • 29 Continuous Data Sets • High Diversity : Examples and Attributes • Experiment : Cross Validation with 10 folders
Conclusions INDEX 1.Introduction 2.The Principle 3.The Algorithm 4.Divide & Conquer 5.Experimentation INDEX 1.Introduction 2.The Principle 3.The Algorithm 4.Divide & Conquer 5.Experimentation 6.Conclusions • NCLEFDC: • Filter Noisy Continuous Examples • O(NCLEFDC)=O(Nlog2(N)+NA2) • Use of NCLEFDC: • Without noisy examples: similar error • With noise : significant improvement • Future work: • Filter Noisy Discrete Examples • Filter at same time noisy examples and noisy attributes
Filtering noisy continuous labeled examples IBERAMIA 2002 José Ramón Quevedo María Dolores García Elena Montañés Artificial Intelligence Centre Oviedo University (Spain)