Download
1 / 71
770 likes | 1.13k Views
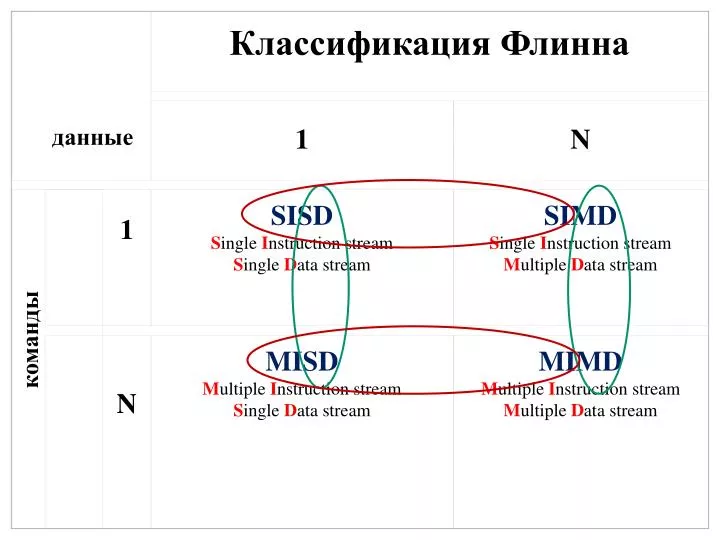
Классификация Флинна. 1. N. 1. SISD S ingle I nstruction stream S ingle D ata stream. SIMD S ingle I nstruction stream M ultiple D ata stream. N. MISD M ultiple I nstruction stream S ingle D ata stream. MIMD M ultiple I nstruction stream M ultiple D ata stream. данные. команды.

E N D
Классификация Флинна 1 N 1 SISDSingle Instruction streamSingle Data stream SIMDSingle Instruction streamMultiple Data stream N MISDMultiple Instruction streamSingle Data stream MIMDMultiple Instruction streamMultiple Data stream данные команды
Классификация Флинна SISD
Дополнения Ванга и Бриггса к классификации Флинна • Класс SISD разбивается на два подкласса: • архитектуры с единственным функциональным устройством, например, PDP-11; • архитектуры, имеющие в своем составе несколько функциональных устройств - CDC 6600, CRAY-1, FPS AP-120B, CDC Cyber 205, FACOM VP-200.
Дополнения Ванга и Бриггса к классификации Флинна • В класс SIMD также вводится два подкласса: • архитектуры с пословно-последовательной обработкой информации - ILLIAC IV, PEPE, BSP; • архитектуры с разрядно-последовательной обработкой - STARAN, ICL DAP.
Дополнения Ванга и Бриггса к классификации Флинна • В классе MIMD авторы различают • вычислительные системы со слабой связью между процессорами, к которым они относят все системы с распределенной памятью, например, Cosmic Cube, • и вычислительные системы с сильной связью (системы с общей памятью), куда попадают такие компьютеры, как C.mmp, BBN Butterfly, CRAY Y-MP, Denelcor HEP.
Классификация Хокни • Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые автор называет конвейерными (например, процессорные модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою очередь опять делятся на два класса: • MIMD компьютеры, в которых возможна прямая связь каждого процессора с каждым, реализуемая с помощью переключателя; • MIMD компьютеры, в которых прямая связь каждого процессора возможна только с ближайшими соседями по сети, а взаимодействие удаленных процессоров поддерживается специальной системой маршрутизации через процессоры-посредники.
Классификация Хокни Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых вся память распределена среди процессоров как их локальная память (например, PASM, PRINGLE). В этом случае общение самих процессоров реализуется с помощью очень сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD машин с распределенной памятью. Если память это разделяемый ресурс, доступный всем процессорам через переключатель, то такие MIMD являются системами с общей памятью (CRAY X-MP, BBN Butterfly). В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина. Многие современные вычислительные системы имеют как общую разделяемую память, так и распределенную локальную. Такие системы автор рассматривает как гибридные MIMD c переключателем.
Классификация Хокни При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память, а дальнейшая классификация проводится в соответствии с топологией сети: звездообразная сеть (lCAP), регулярные решетки разной размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm* , CEDAR) и, наконец, сети, изменяющие свою конфигурацию. Заметим, что если архитектура компьютера спроектирована с использованием нескольких сетей с различной топологией, то, по всей видимости, по аналогии с гибридными MIMD с переключателями, их стоит назвать гибридными сетевыми MIMD, а использующие идеи разных классов - просто гибридными MIMD. Типичным представителем последней группы, в частности, является компьютер Connection Machine 2, имеющим на внешнем уровне топологию гиперкуба, каждый узел которого является кластером процессоров с полной связью.
Классификация Базу Конвейерные компьютеры, такие, как IBM 360/91, Amdahl 470/6 и многие современные RISC процессоры, разбивающие исполнение всех инструкций на несколько этапов, в данной классификации имеют обозначение OPPiS. Более естественное применение конвейеризации происходит в векторных машинах, в которых одна команда применяется к вектору независимых данных, и за счет непрерывного использования арифметического конвейера достигается значительное ускорение. К таким компьютерам подходит обозначение DPPiS. Матричные процессоры, в которых целое множество арифметических устройств работает одновременно в строго синхронном режиме, принадлежат к группе DPPaS. Если вычислительная система подобно CDC 6600 имеет процессор с отдельными функциональными устройствами, управляемыми централизованно, то ее описание выглядит так: OPPaS. Data-flow компьютеры, в зависимости от особенностей реализации, могут быть описаны либо как OPPiA, либо OPPaA.
Классификация Базу Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда можно корректно описать в рамках предложенного формализма. Если процессоры дополнительно не используют параллелизм на уровне операций или данных, то для описания можно использовать лишь букву T. В противном случае, Базу предлагает использовать знак '*' между символами, обозначающими уровни параллелизма, одновременно присутствующие в системе. Например, комбинация T*D означает, что некоторая система может одновременно исполнять несколько задач, причем каждая из них может использовать векторные команды.
Классификация Базу Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из разных групп данной классификации. В этом случае для корректного описания автор использует знак '+'. Например, практически все векторные компьютеры имеют скалярную и векторную части, что можно описать как OPPiS+DPPiS (пример - это TI ASC и CDC STAR-100). Если в системе есть возможность одновременного выполнения более одной векторной команды (как в CRAY-1) то для описания векторной части можно использовать запись O*DPPiS, а полное описание данного компьютера выглядит так: O*DPPiS+OPPiS. Действуя по такому же принципу, можно найти описание и для систем CRAY X-MP и CRAY Y-MP. В самом деле, данные системы объединяют несколько процессоров, имеющих схожую с CRAY-1 структуру, и потому их описание имеет вид: T*(O*DPPiS+OPPiS).
Классификация Хендлера t= (k×k',d×d',w×w') • k - число процессоров (каждый со своим УУ), работающих параллельно • k' - глубина макроконвейера из отдельных процессоров • d - число АЛУ в каждом процессоре, работающих параллельно • d' - число функциональных устройств АЛУ в цепочке • w - число разрядов в слове, обрабатываемых в АЛУ параллельно • w' - число ступеней в конвейере функциональных устройств АЛУ t( TI ASC ) = (1,4,64×8) t( PEPE ) = (1×3,288,32)
Классификация Шора Машина I - это вычислительная система, которая содержит устройство управления, арифметико-логическое устройство, память команд и память данных с пословной выборкой. Считывание данных осуществляется выборкой всех разрядов некоторого слова для их параллельной обработки в арифметико-логическом устройстве. Состав АЛУ специально не оговаривается, что допускает наличие нескольких функциональных устройств, быть может конвейерного типа. По этим соображениям в данный класс попадают как классические последовательные машины (IBM 701, PDP-11, VAX 11/780), так и конвейерные скалярные (CDC 7600) и векторно-конвейерные (CRAY-1).
Классификация Шора Если в машине I осуществлять выборку не по словам, а выборкой содержимого одного разряда из всех слов, то получим машину II. Слова в памяти данных по прежнему располагаются горизонтально, но доступ к ним осуществляется иначе. Если в машине I происходит последовательная обработка слов при параллельной обработке разрядов, то в машине II - последовательная обработка битовых слоев при параллельной обработке множества слов. Другим примером служит матричная система ICL DAP, которая может одновременно обрабатывать по одному разряду из 4096 слов.
Классификация Шора Если объединить принципы построения машин I и II, то получим машину III. Эта машина имеет два арифметико-логических устройства - горизонтальное и вертикальное, и модифицированную память данных, которая обеспечивает доступ как к словам, так и к битовым слоям. Впервые идею построения таких систем в 1960 году выдвинул У.Шуман, называвший их ортогональными (если память представлять как матрицу слов, то доступ к данным осуществляется в направлении, "ортогональном" традиционному - не по словам (строкам), а по битовым слоям (столбцам)).
Классификация Шора Если в машине I увеличить число пар арифметико-логическое устройство <==> память данных (иногда эту пару называют процессорным элементом) то получим машину IV. Единственное устройство управления выдает команду за командой сразу всем процессорным элементам. С одной стороны, отсутствие соединений между процессорными элементами делает дальнейшее наращивание их числа относительно простым, но с другой, сильно ограничивает применимость машин этого класса. Такую структуру имеет вычислительная система PEPE, объединяющая 288 процессорных элементов.
Классификация Шора Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV, например в виде матричной конфигурации, то получим схему машины V. Любой процессорный элемент теперь может обращаться к данным как в своей памяти, так и в памяти непосредственных соседей. Подобная структура характерна, например, для классического матричного компьютера ILLIAC IV.
Классификация Шора Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения памяти данных и арифметико-логических устройств, предполагая наличие шины данных или какого-либо коммутирующего элемента между ними. Машина VI, названная матрицей с функциональной памятью (или памятью с встроенной логикой), представляет собой другой подход, предусматривающий распределение логики процессора по всему запоминающему устройству. Примерами могут служить как простые ассоциативные запоминающие устройства, так и сложные ассоциативные процессоры.
Hewlett-Packard V2600 EDSAC, 1949 , Кембридж Производительность вычислительных систем 2×10-6 1.8×10-9 время такта 2 микросекунды время такта 1.8 наносекунды можно было выполнить 2*n операций за 18*n миллисекунд пиковая производительность около 77 миллиардов операций в секунду рост производительности 100 операций в секунду семьсот миллионов раз
MIPS отношение количества команд в программе к времени ее выполнения Проблемы: MIPS зависит от набора команд процессора, что затрудняет сравнение по MIPS компьютеров, имеющих разные системы команд MIPS даже на одном и том же компьютере меняется от программы к программе MIPS может меняться по отношению к производительности в противоположенную сторону.
Классическим примером для последнего случая является рейтинг MIPS для машины, в состав которой входит сопроцессор плавающей точки. Команда с плавающей точкой ― много тактов синхронизации Программы →сопроцессор→выполняются быстрее меньше подпрограмм → меньше рейтинг MIPS Оптимизирующие компиляторы → сокращается количество команд увеличивается производительность рейтинг MIPS уменьшается
несколько модулей, имитирующих программную нагрузку в наиболее типичных режимах исполнения вычислительных задач. Каждый модуль выполняется многократно, в соответствии с исходной статистикой Whetstone-инструкций IBM RS 6000 MIPS H. J. Curnow и B. A. Wichmann, (NationalPhysicalLaboratory) составлен из синтетических тестов, разработанных с использованием статистики распределения инструкций промежуточного уровня компилятораWhetstoneAlgol, собранной на основе большого количества вычислительных задач. Whetstone 1976 г 1 RS/6000 MIPS 1,6 VAX 11/780 MIPS Различия в Whetstone-характеристиках редакций 1976 и 1988 г. могут достигать 20%.
Комплект тестовWhetstoneсостоит из нескольких модулей, имитирующих программную нагрузку в наиболее типичных режимах исполнения вычислительных задач (целочисленная арифметика, арифметика с плавающей точкой, операторы типа IF, вызовы функций и т.д.). Каждый модуль выполняется многократно, в соответствии с исходной статистикой Whetstone-инструкций (практически это реализуется с помощью заключения модулей в циклические конструкции с разным числом "оборотов" цикла - от 12 до 899), а производительность рассчитывается как отношение числа Whetstone-инстpукций к суммарному времени выполнения всех модулей пакета. Этот результат представляется в KWIPS (KiloWhetstoneInstructionsPerSecond) или в MWIPS (MegaWhetstoneInstructionsPerSecond). В известном смысле указанные единицы аналогичны MIPS, но с одной существенной оговоркой: Whetstone-инструкции не привязаны к системе команд какого-либо компьютера, т. е. оценка производительности в MWIPS является моделенезависимой. • Пакет Whetstone ориентирован на оценку производительности обработки чисел с плавающей точкой: почти 70% времени выполнения Fortran-версии теста на компьютере VAX 11/785 (компилятор BSD 4.3 Fortran) приходится на "плавающую" арифметику Различия в Whetstone-характеристиках редакций 1976 и 1988 г. могут достигать 20%.
Большое число обращений к библиотеке математических функций, заложенное в тесты Whetstone, требует особой осторожности при сравнении результатов, полученных для разных компьютеров: фирмы-изготовители имеют возможность оптимизировать оценку Whetstone, внося изменения в библиотеку. Во всяком случае, нужно помнить, что тесты Whetstone дают надежные ориентиры только в отношении задач с большой интенсивностью использования стандартных математических функций. • Поскольку тестовые модули Whetstone представлены очень компактным исполнительным кодом (весь пакет Whetstone в C-версии занимает около 2 Кбайт кода), для современных процессоров они не позволяют оценить эффективность механизма динамической подкачки команд в кэш инструкций: любой модуль Whetstone целиком размещается в кэш-памяти даже самой малой емкости. • Особенностью описываемых тестов является почти полное отсутствие локальных переменных. Поэтому оценки Whetstone в значительной степени зависят от эффективности функционирования ресурсов компьютера, обеспечивающих доступ к оперативной памяти и буфеpизацию данных в пpоцессоpе (включая количество регистров, емкость кэш-памяти данных и механизм ее замещения), а также от качества реализованных в компиляторе оптимизирующих алгоритмов размещения глобальных переменных в регистрах. Однако это же обстоятельство делает тесты Whetstone практически нечувствительными к средствам повышения эффективности работы с локальными переменными (например, динамическое переключение регистровых окон MORS в процессорах SPARC почти не сказывается на величине Whetstone-оценки). • Единственная "официальная" версия тестов Whetstone - это Pascal-версия (Pascal Evaluation Suite), зарегистрированная Британским обществом стандартов (British Standards Institution - Quality Assurance, BSI-QAS). Остальные варианты (в частности, на языке Fortran) существуют лишь де-факто. Кроме того, в 1988 г. в обращение была введена модернизированная Pascal-версия Whetstone, которая отличается от первоначальной редакции меньшим содержанием вспомогательных действий типа распечатки результатов, не имеющих отношения к измеряемой производительности, а также некоторым изменением веса тестовых модулей в результирующей оценке.
WhetStone(от 97 г): Athlon 1333, FSB266, L1 cache 128Kb ,L2 cache 256Kb Loop content Result MFLOPS MOPS Seconds N1 floating point -1.12475025653839110 252.511 0.543 N2 floating point -1.12274754047393800 220.889 4.344 N3 if then else 1.00000000000000000 246.024 3.004 N4 fixed point 12.00000000000000000 427.670 5.259 N5 sin,cos etc. 0.49904659390449524 24.459 24.287 N6 floating point 0.99999988079071045 108.557 35.477 N7 assignments 3.00000000000000000 99.233 13.297 N8 exp,sqrt etc. 0.75110864639282227 10.080 26.350 MWIPS 634.322 112.561 Зависимость от языка, на котором реализован тест: AM386/40 Pentium PentiumPentProPentPro VAX MIPS VAX MIPS /386 VAX MIPS /386 Qbasic 0.133 0.87 6.5 1.03 7.7 Visual Basic 3 0.490 3.09 6.3 7.05 14.5 Visual Basic 4 0.704 4.94 7.0 9.54 13.6 C++ no opt 4.200 36.60 8.7 129 30.7 C++ in-line 7.400 95.80 12.9 315 42.6
ReinholdWeicker 1984 VAX 11/780 компании DEC 12 модулей, представляющих различные типовые режимы обработки. В тестах Dhrystoneотсутствует обработка чисел с плавающей точкой, зато преобладают операции над другими типами данных (символы, строки, логические переменные, указатели и т. п.). 1 MIPS Dhrystone синтетические → для оценки производительности системного и прикладного ПО 101 оператор в Pascal-версии или 103 оператора в C-версии 100 команд 53% ― операторы присваивания, 32% ― операторы управления, 15% ― вызовы функций. 1MIPS = 1757 Dhrystone
Тест Dhrystone из SiSoftware Sandra основан на арифметических вычислениях и манипуляциях со строками. Общий объем программы маленький, сравнимый с кэшем процессора. Тест может использоваться в двух направлениях, таких как, измерение скорости процессора и возможность оптимизации компилятора. Полученное число - количество измерений в секунду.
Business Winstone 2001 v.1.0.2 использует такие офисные приложения, как Norton Antivirus 2000, Winzip 7.0, Microsoft FrontPage 2000, Lotus Notes R5, Microsoft Access 2000, Microsoft Excel 2000, Microsoft PowerPoint 2000, Microsoft Project 98, Microsoft Word 2000, Netscape Communicator 4.73. Content Creation Winstone 2002 v.2.0 использует приложения: Adobe Photoshop 6.0.1, Adobe Premiere 6.0, Macromedia Director 8.5, Macromedia Dreamweaver UltraDev 4, Microsoft Windows Media Encoder 7.01.00.3055, Netscape Navigator 6/6.01 и Sonic Foundry Sound Forge 5.0c (build 184).
FLOPS, 92 год FLOPS Тест синтетический, обращения к памяти минимизированы. Даетпиковую производительность. Как единица измерения, FLOPS, предназначена для оценки производительности только операций с плавающей точкой, и поэтому не применима вне этой ограниченной области. Например, программы компиляторов имеют рейтинг FLOPS близкий к нулю вне зависимости от того, насколько быстра машина, поскольку компиляторы редко используют арифметику с плавающей точкой. По мнению многих программистов, одна и та же программа, работающая на различных компьютерах, будет выполнять различное количество команд, но одно и то же количество операций с плавающей точкой. Именно поэтому рейтинг FLOPS предназначался для справедливого сравнения различных машин между собой.
Проблемы: Наборы операций с плавающей точкой не совместимы на различных компьютерах Например, в суперкомпьютерах фирмы Cray Research отсутствует командаделения. В то же время многие современные микропроцессоры имеют команды деления, вычисления квадратного корня, синуса и косинуса. Рейтинг MFLOPS меняется не только на смеси целочисленных операций и операций с плавающей точкой, но и на смеси быстрых и медленных операций с плавающей точкой. Например, программа со 100% операций сложения будет иметь более высокий рейтинг, чем программа со 100% операций деления. Решение обеих проблем заключается в том, чтобы взять "каноническое" или "нормализованное" число операций с плавающей точкой из исходного текста программы и затем поделить его на время выполнения.
Ливерморские циклы Ливерморские циклы - это набор фрагментов фортран-программ, каждый из которых взят из реальных программных систем, эксплуатируемых в Ливерморской национальной лаборатории им.Лоуренса (США). Обычно при проведении испытаний используется либо малый набор из 14 циклов, либо большой набор из 24 циклов. Выделяют количество нормализованных операций с плавающей точкой в соответствии с операциями, действительно находящимися в ее исходном тексте.
Процессоры персональных компьютеров • AMDAthlon 64 2,211 ГГц (2003) — 8Гфлопс[10] • AMDAthlon 64 X2 4200+ 2,2 ГГц (2006) — 13.2Гфлопс • AMDAMD ATHLON II X4 645 3.1 ГГц (2010) —38.44Гфлопс • IntelCore 2 Duo 2,4 ГГц (2006) — 19,2Гфлопс[11] • IntelCore 2 Quad Q8300 2,5 ГГц — 40Гфлопс[12] • IntelCore i7-975 XE 3,33 ГГц (2009) — 53.28Гфлопс[13] • CPU AMD Phenom II X6 1100T BlackEdition (HDE00ZF) 3.3 ГГц/ 3+6Мб/4000 МГцSocket AM3 — 60.0953Гфлопс[14]
LINPACK LINPACK - это пакет фортран-программ для решения систем линейных алгебраических уравнений. www.linpack.org В основе алгоритмов действующего варианта LINPACK лежит метод декомпозиции. Исходная матрица размером 100х100 элементов (в последнем варианте размером 1000х1000) сначала представляется в виде произведения двух матриц стандартной структуры, над которыми затем выполняется собственно алгоритм нахождения решения. Подпрограммы, входящие в LINPACK, структурированы. В стандартном варианте LINPACK выделен внутренний уровень базовых подпрограмм, каждая из которых выполняет элементарную операцию над векторами. www.blas.org Набор базовых подпрограмм называется BLAS (BasicLinearAlgebraSubprograms). Например, в BLAS входят две простые подпрограммы SAXPY (умножение вектора на скаляр и сложение векторов) и SDOT (скалярное произведение векторов). Все операции выполняются над числами с плавающей точкой, представленными с двойной точностью. Результат измеряется в MFLOPS. Использование результатов работы тестового пакета LINPACK с двойной точностью как основы для демонстрации рейтинга MFLOPS стало общепринятой практикой в компьютерной промышленности.
МГУ им. М.В.Ломоносова и Межведомственный Суперкомпьютерный Центр РАН объявили о выпуске 12-й редакцию списка Тор50 самых мощных компьютеров России и СНГ. Анонс состоялся на Международной научной конференции «Параллельные вычислительные технологии» (ПАВТ'2010). Пиковая 140,16 Тфлопс, реальная – 107,4 Тфлопс.
