Download
1 / 6
60 likes | 192 Views
Notes on Homework 1. 2x2 Matrix Multiply. C 00 += A 00 B 00 + A 01 B 10 C 10 += A 10 B 00 + A 11 B 10 C 01 += A 00 B 01 + A 01 B 11 C 11 += A 10 B 01 + A 11 B 11 Rewrite as SIMD algebra C00_C10 += A00_A10 * B00_B00 C01_C11 += A00_A10 * B01_B01 C00_C10 += A01_A11 * B10_B10

E N D
CS267 Lecture 7 2x2 Matrix Multiply • C00 += A00B00 + A01B10 • C10 += A10B00 + A11B10 • C01 += A00B01 + A01B11 • C11 += A10B01 + A11B11 • Rewrite as SIMD algebra • C00_C10 += A00_A10 * B00_B00 • C01_C11 += A00_A10 * B01_B01 • C00_C10 += A01_A11 * B10_B10 • C01_C11 += A01_A11 * B11_B11
Summary of SSE intrinsics • #include <emmintrin.h> • Vector data type: • __m128d Load and store operations: • _mm_load_pd • _mm_store_pd • _mm_loadu_pd • _mm_storeu_pd Load and broadcast across vector • _mm_load1_pd Arithmetic: • _mm_add_pd • _mm_mul_pd
Example: multiplying 2x2 matrices #include <emmintrin.h> c1 = _mm_loadu_pd( C+0*lda ); //load unaligned block in C c2 = _mm_loadu_pd( C+1*lda ); for( inti = 0; i < 2; i++ ) { a = _mm_load_pd( A+i*lda); //load alignedi-th column of A b1 = _mm_load1_pd( B+i+0*lda ); //load i-th row of B b2 = _mm_load1_pd( B+i+1*lda ); c1=_mm_add_pd( c1, _mm_mul_pd( a, b1 ) ); //rank-1 update c2=_mm_add_pd( c2, _mm_mul_pd( a, b2 ) ); } _mm_storeu_pd( C+0*lda, c1 ); //store unaligned block in C _mm_storeu_pd( C+1*lda, c2 );
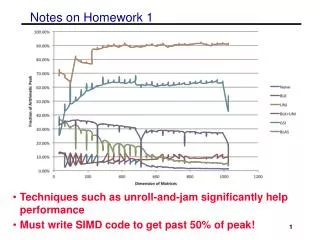
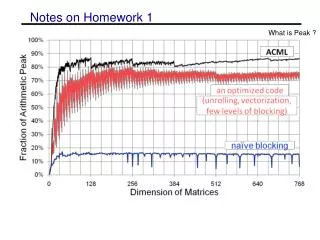
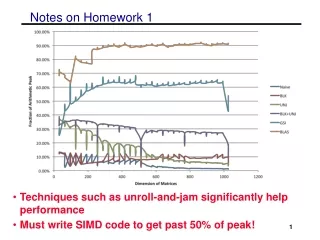
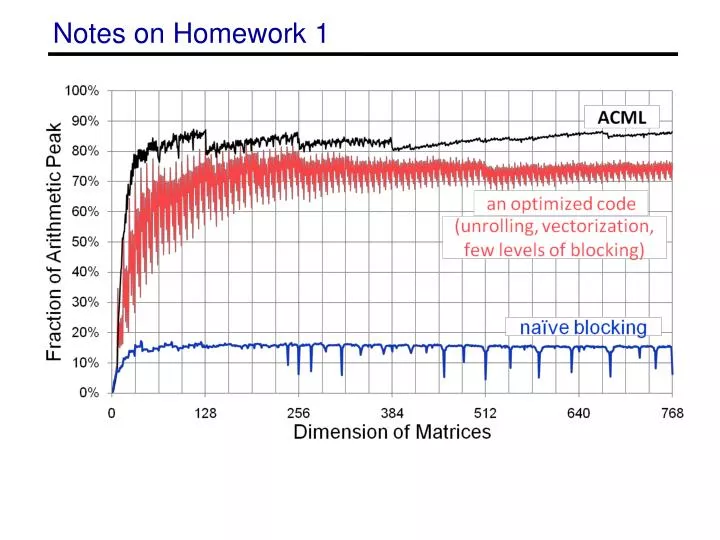
General suggestions for optimizations • Changing the order of the loops (i, j, k) • changes which matrix stays in memory and the type of product • Blocking for multiple levels (registers or SIMD, L1, L2) • L3 is not important as most matrices will fit and optimizations not likely to bring more benefits • Unrolling the loops • Copy optimizations • will be a large benefit if done for sub-matrix that is kept in memory • careful not to overdo (overhead is high for every level) • Aligning memory and padding • can help with SIMD performance • eliminating special cases and bad performance • Adding SIMD intrinsics • cannot get over 50% without explicit intrinsics or auto-vectorization • Tuning parameters • various block sizes, register sizes (perhaps automate)
Other issues • Checking compilers • options available PGI, PathScale, GNU, Cray • Cray compiler seems to have an issue with explicit intrinsics • Using compiler flags • remember not allowed to use MM specific flags (-matmul) • Checking assembly code for SSE instructions • use the –S flag to see assembly • should have mainly ADDPD & MULPD ops, ADDSD & MULSD are scalar computations • Remember the write-up • want to know what optimizations you tried and what worked and failed • try and have an incremental design and show the performance of multiple iterations • DUE DATE changed, now due Monday Feb 17th at 11:59pm