Download
1 / 55
550 likes | 562 Views
Learn about the process of data normalization and its advantages in terms of storage space, efficiency, and data integrity. Discover the steps to ensure accurate data and how to overcome the disadvantages of normalization.

E N D
Normalization Normalization is process of removing all redundancy form database. It is the application of a set of simple rules called first, second & third normal form. When database design is fully normalized ,there is no repletion of data across tables The advantages of data normalization can be very large in terms of storage space as well as increased efficiency with which data can be updated & maintained.
The rules of normalization or normal forms define exactly what kind of information can be placed in each table & and how this information relates to the fields. When considering normalization some user related consideration include: What data should be stored in database? How will the user access the database? What privileges does the user require? How should data be grouped in database? What data most commonly accessed? How is all data related in database? What steps should be taken to ensure accurate data?
ADVANTAGES OF NORMLIZATION Greater overall database organization will be gained. The amount of unnecessary redundant data reduced. Data integrity is easily maintained within the database. The database & application design processes are much for flexible. Security is easier to maintain or manage.
DISADVANTAGES OF NORMLIZATION The disadvantage of normalization is that it produces a lot of tables with a relatively small number of columns. These column then have to be joined using their primary/foreign key relation ships This has two disadvantages. Performance: all the joins required to merge data slow processing & place additional stress on your hardware. Complex queries: developers have to code complex queries in order to merge data from different tables.
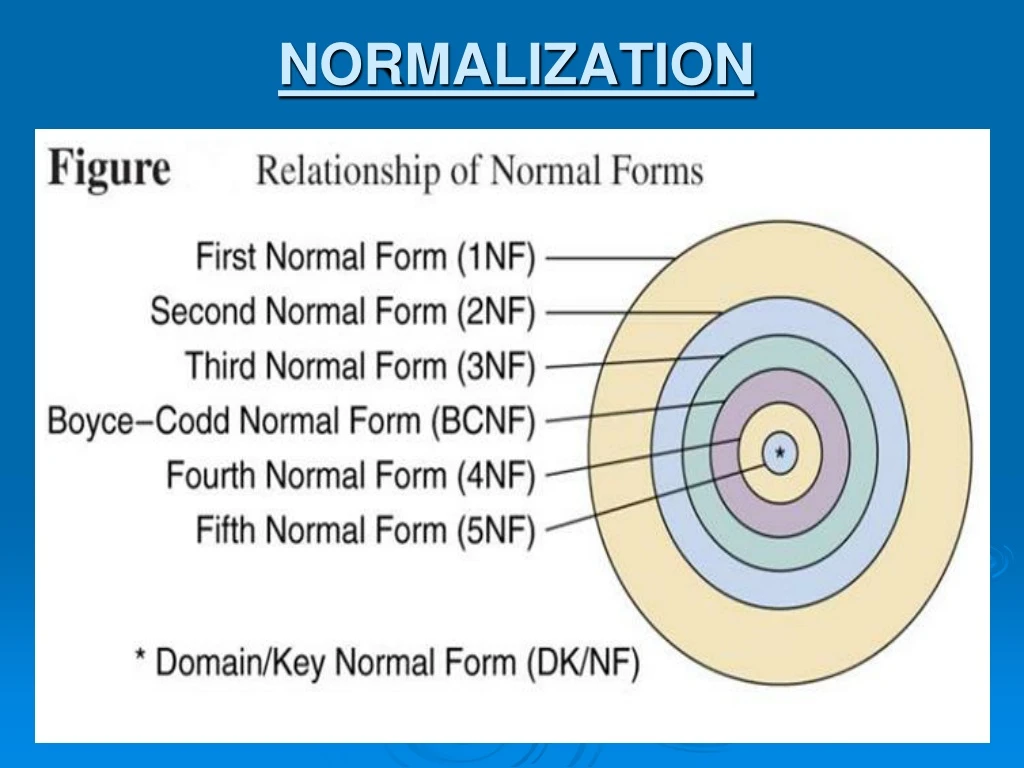
FIRST NORMAL FORM The objective of first normal form is that the table should contain no repeating groups of data. Data is divided into logical units called entities or tables Note: when each entity has been designed, a primary key is assigned to it. All attributes (column) in the entity (table) must be single valued. Repeating or multi valued attributes are moved into a separate entity (table) & a relationship is established between the two tables or entities.
Example of the first normal form Consider the instruction_schedule table with the following attributes (columns) instruction_schedule #instructor_id Fname mid name lname year semester
department1 course1 section_id1 department2 course2 section_id2 department3 course3 section_id3
Because the instructor teaches multiple classes each semester, the class attributes and its corresponding department and section attributes can take more than one value or in other words, there are multi valued attributes. The class attributes can take values class1, class2, class3 & so on. This is a violation of first normal form To bring the instructor_schedule table in first normal form the department, course & section attributes are placed in a separate entity called courses_taught.
SECOND NORMAL FORM The objective of second normal form is that every field in a table should relate to the primary key field in its entity. It means that data that is only partly dependent on the primary key is stored into another table To bring table into a second normal form, it should be first in first normal form.
Now if add department _address to the course_taught table, it would be dependent only on the department attribute not on the whole composite primary key. This is a violation in second normal form. To get the table courses_taught in second normal form, the attributes are moved into another table department
THIRD NORMAL FORM The objective of third normal form is to remove field /data in a table that is not dependent on the primary key It means that, any non-key field in a table must relate to the primary key of the table& not to any other field. The entity is in second normal form and non-key attributes cannot depend on another non-key attributes
The primary key in this case may be either composite or single. All non-key attributes should depend directly on the whole primary key and not on each other. Example consider the employee entity/table: employee #emp_id last_name first_name mid_name category
In above table employee entity has an attributes called category Category has initially values technical, management, administration, proffessional. Let’s, we add an attribute called category_level. Which have following values: for beginner for middle level for an expert
So our entity becomes Employee #emp_id last_name first_name mid_name category category_level
But here, category _level is only dependent on category. And category is dependent on emp_id attributes (primary_key). It is means that, the attributes category_level is dependent on the primary key emp_id through the category attributes but not directly. An attribute dependency on primary key which is not directly but only passes through another attributes that is dependent on primary key is called transitive dependency. This is a violation of third normal form
To solve this violation, category & category_level from employee entity are moved to another entity. So, we have
Boyce-Codd Normal Form (BCNF) To eliminate the problems and redundancy of 3NF, R.F Boyce proposed a normal form known as Boyce-Codd normal form (BCNF). Relation R is said to be in BCNF if for every nontrivial FD: X Y between attributes X and Y holds in R. That means: X is super key of R, X Y is a trivial FD, that is, YX
A relation is in BCNF, if and only if, every determinant is a candidate key. The difference between 3NF and BCNF is that for a functional dependency A B, 3NF allows this dependency in a relation if B is a primary-key attribute and A is not a candidate key, whereas BCNF insists that for this dependency to remain in a relation, A must be a candidate key.
FD1 clientNo, interviewDate interviewTime, staffNo, roomNo (Primary Key) FD2 staffNo, interviewDate, interviewTimeclientNo (Candidate key) FD3 roomNo, interviewDate, interviewTime clientNo, staffNo (Candidate key) FD4 staffNo, interviewDate roomNo (not a candidate key)
As a consequece the ClientInterview relation may suffer from update anmalies. For example, two tuples have to be updated if the roomNo need be changed for staffNo SG5 on the 13-May-02.
MULTI-VALUED DEPENDENCIES (MVD) AND FOURTH NORMAL FORM (4NF) A multi-valued dependency (MVD) is a functional dependency where the dependency may be to a set and not just a single value. It is defined as X Y in relation R (X, Y, Z), if each X value is associated with a set of Y values in a way that does not depend on the Z values. Here X and Y are both subsets of R.
The notation X Y is used to indicate that a set of attributes of Y shows a multi-valued dependency (MVD) on a set of attributes of X Example of a database of teaching courses, the books recommended for the course, and the lecturers who will be teaching the course:
Because the lecturers attached to the course and the books attached to the course are independent of each other, this database design has a multivalued dependency; if we were to add a new book to the DBMS course, we would have to add one record for each of the lecturers on that course, and vice versa. Put formally, there are two multivalued dependencies in this relation: {course} {book} and equivalently {course}{lecturer}.
Databases with multivalued dependencies thus exhibit redundancy. In database normalization, fourth normal form requires that for every nontrivial multivalued dependency X Y, X is a superkey.
These four axioms can be used to derive the closure of a set D+, of D of multi-valued dependencies. It can be noticed that there are similarities between the Armstrong's axioms for FDs and Berri's axioms for MVDs. Both have reflexivity, augmentation, and transitivity rules. But, the MVD set also has a complementation rule.
Fourth Normal Form (4NF) A relation R is said to be in fourth normal form (4NF) if it is in BCNF and for every non-trivial MVD(X Y) in F+, X is a super key for R. The fourth normal form (4NF) is concerned with dependencies between the elements of compound keys composed of three or more attributes. The 4NF eliminates the problems of 3NF. 4NF is violated when a relation has undesirable MVDs and hence can be used to identify and decompose such relations
Relation EMPLOYEE, as shown in Fig. A tuple in this relation represents the fact that an employee (EMP-NAME) works on the project (PROJ-NAME) and has a dependent (DEPENDENT-NAME). This relation is not in 4NF because in the non-trivial MVDs EMP-NAME PROJ-NAME And EMP-NAMEDEPENDENT-NAME, EMP-NAME is not a super key of EMPLOYEE.
Now the relation EMPLOYEE is decomposed into EMP_PROJ and EMP_DEPENDENTS. Thus, both EMP_PROJ and EMP_DEPENDENT are in 4NF, because the MVDs EMP-NAME PROJ-NAME in EMP_PROJ
And EMP-NAME DEPENDENT-NAME in EMP_DEPENDENTS are trivial MVDs. No other non-trivial MVDs hold in either EMP_PROJ or EMP_DEPENDENTS. No FDs hold in these relation schemas either.
Problems with MVDs and 4NF FDs, MVDs and 4NF are not sufficient to identify all data redundancies. Let us consider a relation PERSONS_ON_JOB_SKILLS, as shown in Table. This relation stores information about people applying all their skills to the jobs to which they are assigned. But, they use particular or all skills only when the job needs that skill
The relation PERSONS_ON_JOB_SKILLS of Table is in BCNF and 4NF. For example, person "Thomas" who possesses skills "Analyst" and "DBA" applies them to job J-2, as J-2 needs both these skills.
The same person "Thomas" applies skill "Analyst" only to job J-1, as job J-1 needs only skill "Analyst" and not skill "DBA". Thus, if we delete <Thomas, DBA, J-2>, we must also delete <Thomas, Analyst, J-2>, because persons must apply all their skills to a job if that requires those skills.
JOIN DEPENDENCIES AND FIFTH NORMAL FORM (5NF) The anomalies of MVDs and are eliminated by join dependency (JD) and 5NF.
Join Dependencies (JD) A join dependency (JD) can be said to exist if the join of R1 and R2 over C is equal to relation R. Where, R1 and R2 are the decompositions R1(A, B, c), and R2 (C,D) of a given relations R (A, B, C, D). R1 and R2 is a lossless decomposition of R.
In other words, *(A, B, C, D), (C, D) will be a join dependency of R if the join of the join's attributes is equal to relation R. *( R1, R2, R3 ....) indicates that relations R1, R2, R3 and soon are a join dependency (JD) of R. Relation R to satisfy a JD *( R1, R2,….,Rn) is that R = R1 U R2 U …..U Rn.
relation PERSONS_ON_JOB_SKILLS, as shown in above fig . This relation can be decomposed into three relations namely, HAS_SKILL, NEEDS_SKILL cind ASSIGNED_TO_JOBS. Fig. the join dependencies of decomposed relations. if we join decomposed relations HAS_SKILL and NEEDS_SKILL, a relation CAN_USE_JOB_SKILL is obtained, as shown in above Fig.
This relation stores the data about persons who have skills applicable to a particular job. But, each person who has a skill required for a particular job need not be assigned to that job. Thus, redundant tuples (rows) that show unnecessary SKILL-TYPE and JOB combinations are removed by joining with relation NEEDS_SKILL.
Fifth Normal Form (5NF) A relation is said to be in fifth normal form (5NF) if every join dependency is a consequence of its relation (candidate) keys. For every non-trivial join dependency *(R1 R2 R3) each decomposed relation Riis a super key of the main relation R. 5NF is also called project-join normal form (PJNM).