Download

1 / 10
100 likes | 258 Views
Piranha: A Scalable Architecture Based on Single-Chip Multiprocessing. Barroso, Gharachorloo, McNamara, et. Al Proceedings of the 27 th Annual ISCA, June 2000. Presented by Garver Moore ECE259 Spring 2006 Professor Daniel Sorin. Motivation. Economic: High demand for OLTP machines

E N D
Piranha: A Scalable Architecture Based on Single-Chip Multiprocessing Barroso, Gharachorloo, McNamara, et. Al Proceedings of the 27th Annual ISCA, June 2000 Presented by Garver Moore ECE259 Spring 2006 Professor Daniel Sorin
Motivation • Economic: High demand for OLTP machines • Disconnect between ILP-focus and this demand • OLTP -- High memory latency -- Little ILP (Get, process, store) -- Large TLP • OLTP unserved by aggressive ILP machines • Use “old” cores, ASIC design methodology for “glueless,” scalable OLTP machines and low development costs and time to market • Amdahl’s Law
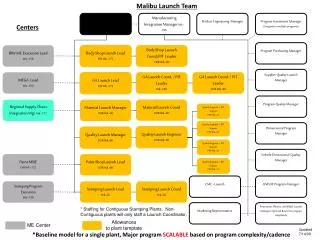
The Piranha Processing Node* CPU: Alpha ECE152 work Single in-order 8-stage pipeline 180 nm process (2000) Almost entirely ASIC design 50% clock speed, 200% area versus full-custom methodology Separate I/D L1 for each CPU Logically shared interleaved L2 cache. Eight memory controllers interface to a bank of up to 32 Rambus DRAM chips. Aggregate max bandwidth of 12.8 GB/sec. *Directly from Barroso et. al
Communication Assist + Home Engine and Remote Engine support shared memory across multiple nodes + System Control tackles system miscellany: interrupts, exceptions, init, monitoring, etc. + OQ, Router, IQ, Switch standard +Total inter-node I/O Bandwidth : 32 GB/sec + Each link and block here corresponds to actual wiring and module. + This allows for rapid parallel development and an semi-custom design methodology + Also facilitates multiple clock domains THERE IS NO INHERENT I/O CAPABILITY.
I/O Organization + Smaller than processing node + Router 2 links, alleviates need for routing table + Memory is globally visible and part of coherency scheme + CPU optimized placement for drivers, translations etc. with low-latency access needs to I/O. + Re-used dL1 design provides interface to PCI/X interface + Supports arbitrary I/O:P ratio, network topology + Glueless scaling up to 1024 nodes of any type supports application specific customization
Coherence: Local + L2 bank and associated controller contains directory data for intra-chip requests – Centralized directory + Chip ICS responsible for all on-chip communication + L2 is “non-inclusive”. + “Large victim buffer” for L1s. Keeps tags and state copies of L1 data + The L2 controller can determine whether data is cached remotely, and if exclusively. Majority of L1 requests then require no CA assist. + L2 on request can service directly, forward to owner L1, forward to protocol engine, or get from memory. +L2 on forwards blocks conflicting requests
Coherence: Global • Trades ECC granularity for “free” directory data storage (4x granularity leaves 44 bits per 64 bit line) • Invalidation-based distributed directory protocol • Some optimizations • No NACKing: Deadlock avoidance through I/O, L, H priority virtual lanes: L: Home node, low priority. H: Forwarded requests, replies • Also guarantee forwards always serviced by targets: e.g. owner writes back to home, holds data until home acknowledges. • Removes NACK/Retry traffic, as well as “ownership change” (DASH), retry-counts (Origin), “No, seriously” (Token). • Routing toward empty buffers for old messages linear buffer dependence on N. Share buffer space among lanes, and “CMI” invalidations avoid deadlock.
Evaluation Methodology • Admittedly favorable OLTP benchmarks chosen (TPC-B and TPC-D modifications) • Simulated and compared to performance of aggressive OOO core (Alpha 21364) with integrated coherence and cache hardware • “Fudged” for full-custom effect • Four evaluations: P1 (One-core Piranha @ 500MHz), INO (1GHz single-issue in-order aggressive core), OOO (4-issue 1GHz) and P8 (Spec. system)
Questions/Discussion • Deadlock avoidance w/o NACK • CMP vs SMP • “Fishy” evaluation methodology? • Specialized computing • Buildability?