Download

1 / 42
420 likes | 569 Views
Implementazione del File System nel Sistema Operativo Unix. (Bach: the Design of the Unix Operating System (cap: 4, da 5.1 a 5.7, 5.12). Argomenti. Index node (I-NODE) gestione dei file mediante i-node struttura dei file regolari e delle directory accesso ai file mediante directory

E N D
Implementazione del File System nel Sistema Operativo Unix (Bach: the Design of the Unix Operating System (cap: 4, da 5.1 a 5.7, 5.12)
Argomenti • Index node (I-NODE) • gestione dei file mediante i-node • struttura dei file regolari e delle directory • accesso ai file mediante directory • layout di un file system Unix • strutture dati per la gestione dei file • system call per la gestione dei file • pipes
Punto di vista dell’utente: eseguibili • File regolari: testo …….. • Directory: Per organizzare il file system • file speciali: device fisici (tty, disks, printers...) • Pipe: (per la comunicazione fra processi) Punto di vista del kernel: i-nodes + data
INDEX-NODE (I-NODE) • i-node: rappresentazione interna di un file unix (blocco indice) • Gli i-node risiedono su disco • vengono copiati in memoria se necessario (in-core i-node) pippo link: pluto file i-node ........
un i-node su disco contiene: • Proprietario del file • tipo di file • diritti di accesso • data di accesso (al file, all’i-node) • numero di link al file (link counter) • indirizzi dei blocchi che contengono il file • dimensioni del file
un i-node in memoria contiene: • numero dell’inode su disco • file system di appartenenza • numero di istanze attive del file (es. compilatore) • STATO DELL’I-NODE: • locked? • c’é un processo in attesa? • l’i-node in memoria é stato modificato? • il file in memoria é stato modificato?
1 2 3 4 ... ... :::: :::: :::: i-node su disco: in core i-node list free list (cache di i-node inattivi) Se un file acceduto non é in memoria, il s.o. cerca prima l’i-node nella free list
accesso ad un i-node (iget) • Cerca l’i-node in memoria primaria • se non lo trovi, copia l’i-node da disco su un i-node della free list (possibilmente libero) • se free-list = empty ERRORE • incrementa il numero di istanze attive del file (reference count + 1) • se i-node = locked WAIT • N.B.: un i-node é locked solo nella system call che lo usa.
rilascio un i-node (iput) • Decrementa il numero di istanze attive del file (reference count := reference count -1) • se reference count == 0 • metti l’i-node nella free list • se l’i-node é stato modificato, copialo su disco • 3 casi: • il file é cambiato • l’access-time é cambiato • il proprietario / i permessi sono cambiati. • Questa gestione é valida per qualsiasi tipo di file
Struttura dei file regolari • Ogni blocco del disco é identificato da un numero • Ogni i-node contiene un elenco dei blocchi che memorizzano il file • Unix adotta l’allocazione gerarchica indicizzata dei blocchi del file
direct 0 direct 1 ... 256 indirizzi ... direct 9 single indirect double indir. triple indirect i puntatori ai blocchi del file nell’i-node data blocks 1024 B 1024 B 1024 B 1024 B 1024 B 1024 B 1024 B (1KB x 10)+(1KB x 256)+(1KB x 2562)+(1KB x 2563)=16GB
11 2 10 12 3 2720 0 0 0 0 4096 0 9 76 8 1 0 278 ---- Esempio data block n. 4096 un puntatore a 0 non fa riferimento ad alcun blocco data block n. 76
Allocazione gerarchica indicizzata • I puntatori con valore 0 non allocano blocchi, e quindi non si spreca spazio • L’accesso é molto veloce per i file piccoli (< 10k) • Si puó aumentare la dimensione dei blocchi per velocizzare l’accesso ai file grandi ma AUMENTA LA FRAMMENTAZIONE INTERNA • Si puó usare un blocco per contenere l’ultimo frammento di piú file (implementazione BSD) • Si puó anche mettere l’i-node nel 1o blocco del file (per file piccolissimi si risparmia molto spazio)
Struttura delle directory (semplificata) • DIRECTORY: file organizzato ad array. Ogni entry ha due campi di 2 e 14 byte i-node number file name (216 file) (attualmente il file name puó essere lungo 512 chars) • il kernel alloca spazio per ogni directory come per i file ordinari • Solo il kernel puó scrivere direttamente in una directory, in modo da garantirne la struttura.
byte offset in directory symbolic name of files i-node number 80 48 32 16 64 0 ... 2 1276 ... 83 0 2114 1798 crash passwd init ... motd .. . struttura della directory /etc
Conversione da path-name a i-node • L’accesso ai file avviene mediante path-names • il kernel lavora con i-node • Ci vuole un ALGORITMO di CONVERSIONE dal path-name all’i-node • Directory di partenza: • root (/) : i-node memorizzato in una var. globale • current directory: i-node memorizzato nella u-area
Algoritmo di conversione algoritm namei /* conversione pathname - inode input pathname; output inode; { if (pathname starts from root) working inode = root inode else working inode = current directory inode; while (there is no more pathname) { read next path name; verify that working inode is of directory, and access permission ok; read directory (working inode); if (component matches an entry in directory (working inode)) { get inode number for matched component; release working inode; working inode = inode of matched component } else /* component not in directory */ return (no inode)} return (working inode); }
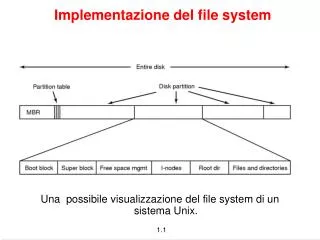
Struttura interna del File System boot block super block i-node list data blocks.... • boot block (blocco 0) • super block (blocco 1) • i-node list • data blocks
Super Block Il super block é una struttura che contiene le informazioni fondamentali su file system: • dimensioni del file system • numero di blocchi liberi • indice del 1o blocco libero della lista • dimensioni della lista di i-node • numero di i-node liberi • indice del 1o i-node libero nella lista di i-node lib. • flag per indicare che il super block é stato modif.
Altri tipi di file Unix • PIPE: • file di contenuto transitorio • i dati possono essere letti solo nell’ordine in cui sono stati scritti (FIFO) • dimensione massima: 10 blocchi (i 10 blocchi ad indirizzamento diretto dell’i-node) • servono per le comunicazioni veloci tra processi
Altri tipi di file Unix • File speciali: • corrispondo ai device fisici • l’i-node non fa riferimento a blocchi di memoria • una subroutine di sistema usa il device nel modo giusto attraverso due valori registrati nell’i-node: • MAJOR NUMBER = tipo di device (tty, disco, ...) • MINOR NUMBER = numero di unitá del device • i file speciali possono essere usati dai programmi come si usano i file regolari
Strutture dati per gestire i file aperti: • User file table: • lista dei file aperti per processo (memoriz. nella u-area) • di solito ha 20 entry (max 20 file aperti contemp.) • le entry puntano alla File table • File table: • lista dei file aperti globale • sempre in memoria centrale • ogni entry contiene l’offset della prossima read/write • ogni entry punta ad un in-core i-node • Lista degli in-core i-node
System call “OPEN” • fd = open(“file”,MODE) (fd: user file descriptor) • il kernel: • recupera l’i-node di “file” e controlla i permessi • alloca una nuova entry nella FILE TABLE che punterá all’in-core i-node • setta a zero l’offset del puntatore in lettura/scrittura • alloca una nuova entry nella USER FILE TABLE che punta alla entry corrispondente nella FILE TABLE • il file descriptor fd ha come valore l’indice della entry nella USER FILE TABLE
in-core i-node list file table 0 1 2 3 4 5 6 7 ... count read 1 count /etc/passwd 2 .... ..... .... .... ..... .... count rd-wrt 1 count myfile 1 ... .... ... ... .... ... count write 1 ... ... ... ... ... ... ... ... ... File tables del kernel user file table • un file aperto in scrittura (fd = 5), ed uno aperto sia in lettura (fd = 3) che in scrittura (fd = 4)
Perché la open: • L’utente usa un file system simbolico • il s.o. lavora solo in termini di i-node e blocchi • la open stabilisce un collegamento efficiente tra un file e la sua organizzazione fisica • la “close”distrugge il collegamento
User file descriptor 0, 1, 2 • 0 = Standard Input (STDIN) • 1 = Standard Output (STDOUT) • 2 = Standard Error (SDTERR) • stdin, stdout, stderr sono assunti di default da tutti i processi • la convenzione é utile per la redirezione dell’input/output e per l’uso delle pipe • possono essere gestiti come normali file (cioé chiusi, riassegnati, riaperti, ...)
file table 0 1 2 7 3 5 6 ... 4 count read 1 count write 1 count rd-wrt 1 ... .... ... count write 1 ... ... ... Esempio di redirezione dell’output user file table • ls > myfile • close(stdout) • fd=open(“myfile”,w) • exec(“ls”) • close(fd) • fd=open(stdout)
System call “READ” • n = read (fd, where_to_put_chars, how_many) • n = numero di caratteri letti • OFFSET = OFFSET + n • read é implementata in modo da poter richiedere la lettura di piú blocchi in anticipo per aumentare l’efficienza
System call “WRITE” • n = write (fd, where_to_get_chars, how_many) • n = numero di caratteri scritti • OFFSET = OFFSET + n • write puó richiedere l’allocazione di blocchi indiretti • puó non avere effetto immediato sul file su disco a causa del buffer cache Unix
System call “LSEEK” • position = lseek (fd, offset, from_where) • from_where: • 0 OFFSET ATTUALE = inizio file • 1 OFFSET ATTUALE = OFFSET ATT. + offset • 2 OFFSET ATTUALE = File size + offset
System call “CREATE” • fd = create(“file”,MODE) (fd: user file descriptor) • crea “file” se non esiste, o lo azzera se esiste • crea una entry per “file” nella directory specificata • crea un nuovo i-node e lo copia su disco • “file” é aperto in scrittura
7 ... 0 1 2 3 4 5 6 system call “CLOSE” count := count -1 file table • close(3) • close(5) i-node table user file table rilasciato count /etc/passwd 1 .... ..... .... .... ..... .... NULL count rd-wrt 1 NULL in-core i-node ritorna in free list ... .... ... ... .... ... rilasciato ... ... ... ... ... ... ... ... ...
System call “LINK” • link(existing_file_name, new_file_name) • Associa ad un file un nuovo nome • il kernel: • recupera l’i-node di “file” e controlla i permessi • link-counter = link-counter + 1 • alloca una nuova entry nella directory di new_file_name con nuovo nome, e l’i-node di existing_file_name • (é cosí che funziona anche il comando Unix ln) • questo tipo di link si chiama hard link
System call “UNLINK” • unlink(file_name) • rimuove un link a file_name • il kernel: • recupera l’i-node di “file” e controlla i permessi • link-counter = link-counter - 1 • rimuove l’entry dalla directory di file_name • se link-counter = 0, rimuovi l’i-node (é cosí che funziona anche il comando Unix rm)
Symbolic Link • il numero di un i-node é unico solo nell’ambito di un file system • un link fisico (hard link) non puó attraversare i file system • per fare ció si usano i link simbolici • ln -s /usr/local/bin/prolog myprolog • nella entry della directory per myprolog non viene registrato l’-inode del file prolog, ma il suo pathname assoluto. • il link counter non viene modificato
File di tipo “PIPE” • Permettono la comunicazione tra processi con un meccanismo di tipo FIFO • UNNAMED PIPE • vengono riferite solo mediante file descriptor • solo processi in relazione padre/figlio possono usare una unnamed pipe • sono automaticamente rimosse alla morte dei processi • NAMED PIPE • esistono nel file system • qualsiasi processo puó usarne una (se ha i permessi)
Unnamed PIPE • Risiedono solo in memoria primaria, per cui sono meccanismi di comunicazione velocissimi • Vengono implementate come file normali usando un i-node. • Solo i blocchi indirizzati direttamente vengono usati per lettura/scrittura, e sono gestiti in modo circolare. • ad ogni pipe sono associati un file descriptor in lettura ed uno in scrittura
0 5 1 6 2 7 3 8 4 9 pipe(fds) fds[0] = lettura int fds[2] fds[1] = scrittura write pointer read pointer offset 0 offset 10239 blocchi diretti dell’i-node
funzionamento della pipe • i dati vengono letti nell’ordine in cui sono stati scritti (no lseek) • i dati possono essere letti una sola volta (vengono “consumati”) • un dato non puó essere sovrascritto prima che sia stato letto (il processo scrittore é messo in wait) • la lettura di una pipe vuota provoca la sospensione del processo lettore
Esempio di uso di unnamed pipe char string[] = “hello” main() { char buf[1024] char *cp1, *cp2; int fds[2] cp1 = string; cp2 = buf; while (*cp1) *cp2++ = *cp1++; pipe(fds); for (;;) { write(fds[1], buf, 6); read (fds[0], buf, 6): } } Il processo scrive e legge sulla pipe all’infinito. Che succede se si scambiano i due comandi di scrittura/lettura?
named pipes • mknod(file_name, PIPE, 0); • crea il file file_name che viene gestito come una pipe • file_name é un file del file system, quindi ogni processo lo vede e puó usarlo, se ha i permessi. • anche questa pipe é sospensiva
esempio di uso di named pipe #include <fcntl.h> char string[] = ‘” hello”; main(argc,argv) int argc; char *argv[]; { int fd; char buf[256]; /* creazione di una named pipe con permessi di lettura/scrittura per tutti gli utenti */ mknod(“fifo”, 010777,0); if (argc == 2 ) fd = open(“fifo”, O_WRONLY); else fd = open(“fifo”, O_RDONLY); for(;;) if (argc == 2) write(fd, string, 6); else read(fd, string, 6); }