Download
1 / 3
30 likes | 188 Views
Learning Pastoralists Preferences via Inverse Reinforcement Learning (IRL) . Nikhil Kejriwal , Theo Damoulas , Rusell Toth , Bistra Dilkina , Carla Gomes, Chris Barrett . Introduction.

E N D
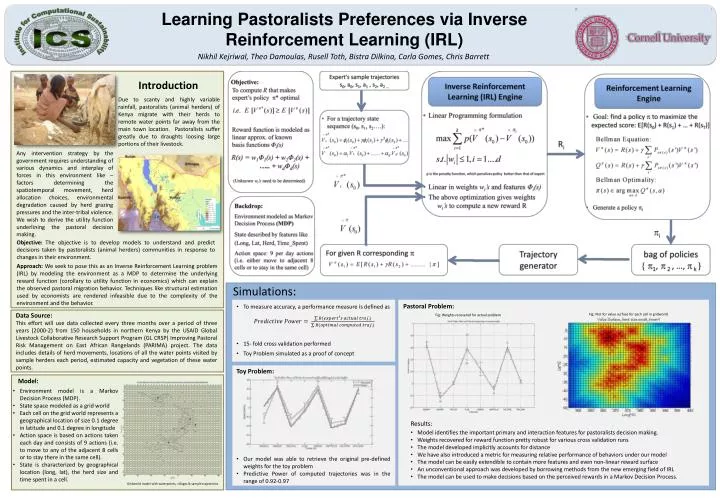
Learning Pastoralists Preferences via Inverse Reinforcement Learning (IRL) Nikhil Kejriwal, Theo Damoulas, RusellToth, BistraDilkina, Carla Gomes, Chris Barrett Introduction Due to scanty and highly variable rainfall, pastoralists (animal herders) of Kenya migrate with their herds to remote water points far away from the main town location. Pastoralists suffer greatly due to draughts loosing large portions of their livestock. Any intervention strategy by the government requires understanding of various dynamics and interplay of forces in this environment like – factors determining the spatiotemporal movement, herd allocation choices, environmental degradation caused by herd grazing pressures and the inter-tribal violence. We wish to derive the utility function underlining the pastoral decision making. Objective:The objective is to develop models to understand and predict decisions taken by pastoralists (animal herders) communities in response to changes in their environment. Approach: We seek to pose this as an Inverse Reinforcement Learning problem (IRL) by modeling the environment as a MDP to determine the underlying reward function (corollary to utility function in economics) which can explain the observed pastoral migration behavior. Techniques like structural estimation used by economists are rendered infeasible due to the complexity of the environment and the behavior. Simulations: Pastoral Problem: • To measure accuracy, a performance measure is defined as Data Source: This effort will use data collected every three months over a period of three years (2000-2) from 150 households in northern Kenya by the USAID Global Livestock Collaborative Research Support Program (GL CRSP) Improving Pastoral Risk Management on East African Rangelands (PARIMA) project. The data includes details of herd movements, locations of all the water points visited by sample herders each period, estimated capacity and vegetation of these water points. Fig: Plot for value surface for each cell in gridworld Fig: Weights recovered for actual problem • 15- fold cross validation performed • Toy Problem simulated as a proof of concept Toy Problem: Model: • Environment model is a Markov Decision Process (MDP). • State space modeled as a grid world • Each cell on the grid world represents a geographical location of size 0.1 degree in latitude and 0.1 degree in longitude • Action space is based on actions taken each day and consists of 9 actions (i.e. to move to any of the adjacent 8 cells or to stay there in the same cell). • State is characterized by geographical location (long, lat), the herd size and time spent in a cell. Results: • Model identifies the important primary and interaction features for pastoralists decision making. • Weights recovered for reward function pretty robust for various cross validation runs • The model developed implicitly accounts for distance • We have also introduced a metric for measuring relative performance of behaviors under our model • The model can be easily extendible to contain more features and even non-linear reward surface • An unconventional approach was developed by borrowing methods from the new emerging field of IRL • The model can be used to make decisions based on the perceived rewards in a Markov Decision Process. • Our model was able to retrieve the original pre-defined weightsfor the toy problem • Predictive Power of computed trajectories was in the range of 0.92-0.97 Gridworld model with waterpoints, villages & sample trajectories
Learning Pastoralists Preferences via Inverse Reinforcement Learning (IRL) Nikhil Kejriwal, Theo Damoulas, Rusell Toth, Bistra Dilkina, Carla Gomes, Chris Barrett Introduction Due to scanty and highly variable rainfall, pastoralists (animal herders) of Kenya migrate with their herds to remote water points far away from the main town location. Pastoralists suffer greatly due to draughts loosing large portions of their livestock. Any intervention strategy by the government requires understanding of various dynamics and interplay of forces in this environment like – factors determining the spatiotemporal movement, herd allocation choices, environmental degradation caused by herd grazing pressures and the inter-tribal violence. We wish to derive the utility function underlining the pastoral decision making. Objective:The objective is to develop models to understand and predict decisions taken by pastoralists (animal herders) communities in response to changes in their environment. Approach: We seek to pose this as an Inverse Reinforcement Learning problem (IRL) by modeling the environment as a MDP to determine the underlying reward function (corollary to utility function in economics) which can explain the observed pastoral migration behavior. Techniques like structural estimation used by economists are rendered infeasible due to the complexity of the environment and the behavior. Simulations: Pastoral Problem: • To measure accuracy, a performance measure is defined as Data Source: This effort will use data collected every three months over a period of three years (2000-2) from 150 households in northern Kenya by the USAID Global Livestock Collaborative Research Support Program (GL CRSP) Improving Pastoral Risk Management on East African Rangelands (PARIMA) project. The data includes details of herd movements, locations of all the water points visited by sample herders each period, estimated capacity and vegetation of these water points. Fig: Plot for value surface for each cell in gridworld Fig: Weights recovered for actual problem • 15- fold cross validation performed • Toy Problem simulated as a proof of concept Toy Problem: Model: • Environment model is a Markov Decision Process (MDP). • State space modeled as a grid world • Each cell on the grid world represents a geographical location of size 0.1 degree in latitude and 0.1 degree in longitude • Action space is based on actions taken each day and consists of 9 actions (i.e. to move to any of the adjacent 8 cells or to stay there in the same cell). • State is characterized by geographical location (long, lat), the herd size and time spent in a cell. Results: • Model identifies the important primary and interaction features for pastoralists decision making. • Weights recovered for reward function pretty robust for various cross validation runs • The model developed implicitly accounts for distance • We have also introduced a metric for measuring relative performance of behaviors under our model • The model can be easily extendible to contain more features and even non-linear reward surface • An unconventional approach was developed by borrowing methods from the new emerging field of IRL • The model can be used to make decisions based on the perceived rewards in a Markov Decision Process. • Our model was able to retrieve the original pre-defined weightsfor the toy problem • Predictive Power of computed trajectories was in the range of 0.92-0.97 Gridworld model with waterpoints, villages & sample trajectories
Learning Pastoralists Preferences via Inverse Reinforcement Learning (IRL) Nikhil Kejriwal, Theo Damoulas, Rusell Toth, Bistra Dilkina, Carla Gomes, Chris Barrett Introduction Due to scanty and highly variable rainfall, pastoralists (animal herders) of Kenya migrate with their herds to remote water points far away from the main town location. Pastoralists suffer greatly due to draughts loosing large portions of their livestock. Any intervention strategy by the government requires understanding of various dynamics and interplay of forces in this environment like – factors determining the spatiotemporal movement, herd allocation choices, environmental degradation caused by herd grazing pressures and the inter-tribal violence. We wish to derive the utility function underlining the pastoral decision making. Objective:The objective is to develop models to understand and predict decisions taken by pastoralists (animal herders) communities in response to changes in their environment. Approach: We seek to pose this as an Inverse Reinforcement Learning problem (IRL) by modeling the environment as a MDP to determine the underlying reward function (corollary to utility function in economics) which can explain the observed pastoral migration behavior. Techniques like structural estimation used by economists are rendered infeasible due to the complexity of the environment and the behavior. Simulations: Pastoral Problem: • To measure accuracy, a performance measure is defined as Data Source: This effort will use data collected every three months over a period of three years (2000-2) from 150 households in northern Kenya by the USAID Global Livestock Collaborative Research Support Program (GL CRSP) Improving Pastoral Risk Management on East African Rangelands (PARIMA) project. The data includes details of herd movements, locations of all the water points visited by sample herders each period, estimated capacity and vegetation of these water points. Fig: Plot for value surface for each cell in gridworld Fig: Weights recovered for actual problem • 15- fold cross validation performed • Toy Problem simulated as a proof of concept Toy Problem: Model: • Environment model is a Markov Decision Process (MDP). • State space modeled as a grid world • Each cell on the grid world represents a geographical location of size 0.1 degree in latitude and 0.1 degree in longitude • Action space is based on actions taken each day and consists of 9 actions (i.e. to move to any of the adjacent 8 cells or to stay there in the same cell). • State is characterized by geographical location (long, lat), the herd size and time spent in a cell. Results: • Model identifies the important primary and interaction features for pastoralists decision making. • Weights recovered for reward function pretty robust for various cross validation runs • The model developed implicitly accounts for distance • We have also introduced a metric for measuring relative performance of behaviors under our model • The model can be easily extendible to contain more features and even non-linear reward surface • An unconventional approach was developed by borrowing methods from the new emerging field of IRL • The model can be used to make decisions based on the perceived rewards in a Markov Decision Process. • Our model was able to retrieve the original pre-defined weightsfor the toy problem • Predictive Power of computed trajectories was in the range of 0.92-0.97 Gridworld model with waterpoints, villages & sample trajectories