Download

1 / 20
240 likes | 695 Views
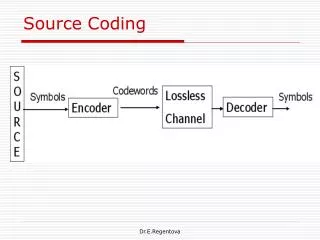
Source Coding. Hafiz Malik Dept. of Electrical & Computer Engineering The University of Michigan-Dearborn hafiz@umich.edu http://www-perosnal-engin.umd.umich.edu/~hafiz. Overview. Information Source. Source Encode. Encrypt. Channel Encode. Multiplex. Pulse Modulate. Multiple Access.

E N D
Source Coding Hafiz Malik Dept. of Electrical & Computer Engineering The University of Michigan-Dearborn hafiz@umich.edu http://www-perosnal-engin.umd.umich.edu/~hafiz
Overview Information Source Source Encode Encrypt Channel Encode Multiplex Pulse Modulate Multiple Access Frequency Spreading BandpassModulate XMT Source Coding – eliminate redundancy in the data, send same information in fewer bits Channel Coding – Detect/Correct errors in signaling and improve BER
What is information? • Student slips on ice in winter in Southfield, MI • Professor slips on ice, breaks arm, class cancelled • Student slips on ice in July in Southfield, MI • Which statement contains the most information? • Statement with unpredictability factor conveys the most new information and surprise Information (I) is related to -log(Pr{event}) Here, Pr{event} 1 I 0, & Pr{event} 0 I ∞]
Measure of Randomness • Let we have two events, E1 & E2 with Pr{E1} = p & Pr{E2} = q • {E1 U E2} = S • Here p=1-q • Entropy: average information per source output 1.0 0.5 0 Entropy H (bits) 0 0.5 1.0 Probability, p
Comments on Entropy • When log is taken to base 2, unit of H bits/event & for base e nats • Entropy is maximum for a uniformly distributed random variable • Example:
Calculate the average information in bits/character in English assuming each letter is equally likely Example: Average Information Content in English Language
Real-world English But English characters do not appear with the same frequency in the real-world English literature, probabilities of each character are assumes as , Pr{a}=Pr{e}=Pr{o}=Pr{t}=0.10 • Pr{h}=Pr{i}=Pr{n}=Pr{r}=Pr{s}=0.07 • Pr{c}=Pr{d}=Pr{f}=Pr{l}=Pr{p}=Pr{u}=Pr{y} =0.02 • Pr{b}=Pr{g}=Pr{j}=Pr{k}=Pr{g}=Pr{v}=Pr{w}=Pr{x}=Pr{z} =0.01
Example Binary Sequence • X, P(X=1) = P(X=0) = ½ • Pb=0.01 (1 error per 100 bits) • R=1000 binary symbol/sec
Source Coding • Goal is to find an efficient description of information sources • Reduce required bandwidth • Reduce memory to store • Memoryless –If symbols from source are independent, one symbol does not depend on next • Memory – elements of a sequence depend on one another, e.g. UNIVERSIT_?, 10-tuple contains less information since dependent
Source Coding (II) • This means that it’s more efficient to code information with memory as groups of symbols
Desirable Properties • Length • Fixed Length – ASCII • Variable Length – Morse Code, JPEG • Uniquely Decodable – allow user to invert mapping to the original • Prefix-Free – No codeword can be a prefix of any other codeword • Average Code Length (ni is code length of ith symbol)
Uniquely Decodable and Prefix Free Codes • Uniquely decodable? • Not code 1 • If “10111” sent, is code 3 ‘babbb’or ‘bacb’? Not code 3 or 6 • Prefix-Free • Not code 4, • prefix contains ‘1’ • Avg Code Length • Code 2: n=2 • Code 5: n=1.23
Huffman Code • Characteristics of Huffman Codes: • Prefix-free, variable length code that can achieve the shortest average code length for an alphabet • Most frequent symbols have short codes • Procedure • List all symbols and probabilities in descending order • Merge branches with two lowest probabilities, combine their probabilities • Repeat until one branch is left
0.4 0.4 0.2 0.4 0.2 0.2 0.2 0.4 0.2 0.2 0.1 0.1 1 0 a 0.4 1 0 b 0.6 0.2 1 0 c 0.4 0.1 1 0 d 0.1 1 0 e Compression Ratio: 3.0/2.4=1.25 Entropy: 2.32 0.2 0.1 f 0.1 Huffman Code Example 0.6 0.4 1.0 The Code: A 11 B 00 C 101 D 100 E 011 F 010 0.2
Example: • Consider a random vector X = {a, b, c} with associated probabilities as listed in the Table • Calculate the entropy of this symbol set • Find the Huffman Code for this symbol set • Find the compression ratio and efficiency of this code
Extension Codes • Combine alphabet symbols to increase variability • Try to combine very common 2,3 letter combinations, e.g.: th,sh, ed, and, the,ing,ion
Lempel-Ziv (ZIP) Codes • Huffman codes have some shortcomings • Know symbol probability information a priori • Coding tree must be known at coder/decoder • Lempel-Ziv algorithm use text itself to iteratively construct a sequence of variable length code words • Used in gzip, UNIX compress, LZW algorithms
Lempel-Ziv Algorithm • Look through a code dictionary with already coded segments • If matches segment, • send <dictionary address, next character> and store segment + new character in dictionary • If no match, • store in dictionary, send <0,symbol>
Code Dictionary Address Contents Encoded Packets LZ Coding: Example • Encode [a b a a b a b b b b b b b a b b b b b a] 1 a < 0 , a > Note: 9 code words, 3 bit address, 1 bit for new character, 2 b < 0 , b > 3 aa < 1 , a > 4 ba < 2 , a > 5 bb < 2 , b > 6 bbb < 5 , b > 7 bba < 5 , a > 8 bbbb < 6 , b > < 4 , - >
Notes on Lempel-Ziv Codes • Compression gains occur for long sequences • Other variations exist that encode data using packets and run length encoding: <# characters back, length, next character>