Download

1 / 45
450 likes | 575 Views
Cognitive Neuroscience and Embodied Intelligence. Networks of Neurons. Based on a courses taught by Prof. Randall O'Reilly , University of Colorado, Prof. Włodzisław Duch , Uniwersytet Mikołaja Kopernika and http://wikipedia.org/.

E N D
Cognitive Neuroscience and Embodied Intelligence Networks of Neurons Based on a courses taught by Prof. Randall O'Reilly, University of Colorado, Prof. Włodzisław Duch, Uniwersytet Mikołaja Kopernika and http://wikipedia.org/ http://grey.colorado.edu/CompCogNeuro/index.php/CECN_CU_Boulder_OReilly http://grey.colorado.edu/CompCogNeuro/index.php/Main_Page Janusz A. Starzyk
Individual neurons allow to detect single features. How can we use a neuron’s model? Neurons and rules Classical logic: If A1 and A2 and A3 then Conclusion e.g. If Headache and Muscle ache and Runny nose then Flu Neural threshold logic: If M of N conditions are fulfilled then Conclusion Conditions can have various weights; classical logic can be easily realized with the help of neurons. There’s a continuum between rules and similarity: rules are useful for a few variables - for many variables: similarity. |W-A|2 = |W|2 + |A|2 - 2W.A = 2(1- W.A), for normalized X, A, so a strong excitation = a short distance (large similarity ).
Demon (gr. daimon - one who divides or distributes), Demons observing features: | vertical line D1 -- horizontal line D2 / forward slash D3 \ backslash D4 Pandemonium in action V demons 3, 4 => D5 T demons 1, 2 => D6 A demons 2, 3, 4 => D7 K demons 1, 3, 4 => D8 demons 6,7,8 => D9 The better it fits the louder they shout. Demon making decisions: D9 doesn’t distinguish TAK from KAT ... for this we need sequence recognition Each demon makes a simple decision but the entirety is quite complex.
What traits should we observe to understand speech? language? images? faces? Act creatively? http://psych.colorado.edu/~oreilly/cecn_download.html Simulations: write equations describing how good is the fit, how loud the demons should shout. How to reduce biology to equations? Simulations Synaptic efficiency: how strong Activity of a presynaptic neuron: how many vesicles, how much neurotransmitter per vesicle, how much is absorbed by the postsynaptic Postsynaptic: how many receptors, geometry, distance from the spine etc. Extreme simplification: one number characterizing efficiency.
What properties does a neural network have? How to set a neural network to do something interesting? Neurons and networks Biology: networks are in the cortex (neocortex) and subcortical structures. Excitatory neurons (85%) and inhibitory neurons (15%). Excitations can be: • mainly in one direction • signal transformation; • in both directions • supplementing missing information • agreeing upon hypotheses and strengthening weak signals. • most excitatory neurons are bi-directional. Inhibition: controls mutual excitations, necessary to avoid extra feedback (epilepsy). The entirety makes possible the interpretation of incoming information in the light of knowledge of its meaning, encoded in the network structure.
Does the cortex have some general properties or does its structure depend on the function: perceptive, motor, associative? General network structure There is a functional specialization of the cortex, observable differences in various areas (division of the cortex into Brodmann’s fields). The general scheme is retained: • A excitatory neurons • main NT is glutamic acid, • AMPA receptor opens Na+ channels, excites long axons, communication within and between neural groups • NMDA receptor opens Ca++ channels, leads to learning • around 85%, mainly pyramidal cells, spiny stellate cells + ... • B inhibitory neurons • main NT is GABA (gamma-aminobutyric acid), opens Cl- channels, interneurons, local projections, regulation of the excitation level; • GABA-A short-term effect BAGA – B long-term effect • around 15%: basket cells and chandelier cells + ...
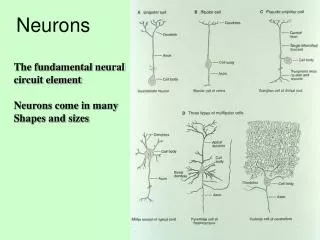
Pyramidal, spiny stellate, basket, chandelier, spindle cells
The cortex has a thickness of 2-4 mm and consists of 6 layers, with different thicknesses in different parts of the brain. A B C D Laminar structure A - the visual cortex has a thicker input layer 4a-c; B - the parietal cortex has thicker hidden layers 2 and 3; C - the motor cortex has thicker output layers 5-6; D – the prefrontal cortex doesn’t have markedly thicker layers.
Functional division of layers: input layer4, receives information from the thalamus, senses; output layers5/6, subcortical centers, motor commands; hidden layers2/3, transform local information and information from distant neuron groups, coming through axons on layer 1. Layer connections In each layer we have local bi-directional connections. Hidden layers: extract certain attributes of the signal, strengthen some and weaken others; this enables the realization of complex signal transformations. This kind of organization is also required by the episodic memory.
1) Input layer4,initial processing of outside information. 2) Hidden layers2/3, further processing, associations, a little I/O.3) Output layers5/6, subcortical centers, motor commands. Connections in more detail these blocks may be connected sequentially
Unidirectional connections are rare, but this model can be generalized to a situation with feedback. Bottom-up processing: collectively, neural detectors perform transformations, categorize chosen signals, differentiating similar from dissimilar ones. Simple transformations Detectors create a representation of information coming in to the hidden layer. Simplest case: binary images of digits in a 5x7 grid on input, all images similar to the given digit should activate the same unit hidden in the 5x2 grid.
Activate the Emergent simulator and select projects, then select chapter_3, and transform.proj The view is from older version of the simulator PDP++ Digit detector - simulation The window ...Network_0 shows the network structure, two layers, input and output. Looking at the weights connected with the selected hidden unit: click on r.wt, and then on the given unit: the weights are matched precisely to the digits.
Input weights for the selected digit r.wt shows weights for hidden units, here all 0 or 1. s.wt shows individual connections, eg. the left upper input corner =1 for 5 and 7. Digit detector - network
Instead of r.wt we select act (in ...network_0). In the control window select step, activating one step, the presentation of successive digits. Digit detector - operation The degree of activation of the hidden units for the selected digit is large (yellow or red color), for the others it is zero (gray color). Those easily distinguished, eg. 4, have a higher activation than those which are less distinct, eg.3.
What is the activity of individual detectors in response to a single input image? In the control window select the TrialOutputData tab in the right window -- you will see a graph and a colorful grid display. For each image all units activate to a certain degree; we can see here the large role of the thresholds, which allow us to select the correct unit; in the control window we can turn off the thresholds (biases off) and see that some digits are not, recognized. Grid Display
From the ControlPanelwindow select Cluster Init and Cluster Run to generate a cluster plot. Clustering with the help of a cluster plot illustrates the reciprocal similarity of vectors, the length of line d(A,B) = |A-B|. Similarity of images Hierarchical clustering of vectors representing input images: highly probable are the digits 8 and 3: 13 identical bits, as well as 4 and 0, only 4 common bits.
From the ControlPanelwindow select Noisy_digits, Apply and Step observing in window Network, we watch activation of hidden neurons. Likelihood of distorted images We have image + 2 distorted images, likelihood of distorted digits is shown by the cluster plots.
A change in the conductivity of the leakage channels affects the selectivity of neurons, for smaller values of ĝl . In the window decrease ĝl =6, to 5 and 4. More associations less precision. Leakage channels (potassium) ĝl =6 ĝl = 5 ĝl = 4
We will apply the network for digits to letters... only S resembles 8, the other hidden units don’t recognize anything. Detectors are specialized for specific tasks! We won’t recognize Chinese characters if we only know Korean. Letters Cluster plots for the representation of letters before and after the transformation.
Local representations : one hidden neuron represents one image these neurons are referred to as grandmother cells. Distributed representations : many neurons respond to one image, each neuron takes part in reactions to many images. Local and distributed representations Observation of the neural response in the visual cortex of a monkey to different stimuli confirms the existence of distributed representations
Images can be represented in a distributed manner by an array of their traits (feature-based coding). Traits are present "to a certain degree." Hidden neurons can be interpreted as the degree of detection of a given feature – that's what you do in fuzzy logic. Distributed representations Advantages of distributed representation (DR): ?
Images can be represented in a distributed manner by an array of their traits (feature-based coding). Traits are present "to a certain degree." Hidden neurons can be interpreted as the degree of detection of a given feature – that's what you do in fuzzy logic. Distributed representations Advantages of distributed representation (DR): • Larger memory size: images can be represented by combining the activation of many units; n local units = 2n combinations. • Similarity: similar images have comparable DR, partly overlapping. • Generalization: new images activate various DR usually giving an approximation to sensory response, between A and B. • Resistance to damage, system redundancy. • Exactness: DR of continuous features is more realistic than discrete local activations. • Learning: becomes easier for continuous small changes in DR.
Project loc_dist.proj from chapter_3. To represent digits we now use 5 units. The network reacts to the presence of certain features, eg. the first hidden neuron reacts to => Experiment with RR Distributed representations can work even on randomly selected fetures: new DR = projection of input images to some feature space. Grid display shows the distribution of net activation and output of the network, showing the degree of presence of a given feature. The cluster plot looks completely different than for a local network.
Networks almost always have feedback between neurons. Recurrence: secondary, repeated activation; from this come networks with recurrence (bidirectional). Feedback Advantages of feedback in NN: ?
Networks almost always have feedback between neurons. Recurrence: secondary, repeated activation; from this come networks with recurrence (bidirectional). Bottom-up and top-down, or recognition and imagination. Feedback Recurrence makes possible the completion of images, formation of resonances between associated representations, strengthening of weak activations and the initiation of recognition. Example: recognize the second letter in simple words: CART (faster) BAZS (slower) Strange: text recognition proceeds from letters to words; so how does a word help in the recognition of a letter?
A network with a hidden layer 2x5, connected bi-directionally with the inputs. Symmetrical connections: the same weights Wij=Wji. Recurrence for digits The center pixel activates 7 hidden neurons, each hidden neuron activates all the pixels of a given digit, but the inputs are always taken from the images of the digits. Combinations of hidden neuron activations
Project pat_complete.proj in Chapter_3. A network with one 5x7 layer, connected bi-directionally with itself. Symmetrical connections: the same weights Wij=Wji. Units belonging to image 8 are connected to themselves with a weight of 1, remaining units have a weight of 0. Activations of input units here are not fixed by the images (hard clamping), but only initiated by the images (soft clamping), so they can change. Completion of images Check the dependence of the minimum number of units sufficient to reconstruct the image from the conductivity of ion channels. For a large ĝl start from a partial image requires a greater and greater number of correctly initialized pixels, for ĝl = 3 we need >6 pixels, for ĝl = 4 we need >8 pixels, for ĝl = 5 we need >11 pixels.
Project amp_top_down.proj in Chapter_3. From a very weak activation of some image, amplification processes can lead to full activation of the image or uncontrolled activation of the whole network. The network currently has two hidden layers. Recurrent amplification A weak excitation leads to a growth in activation of neuron 2, and reciprocal activation of neuron 1. For a large ĝl>3.5theeffect disappears. The same effect can be achieved through feedback inside a single layer. Weak activation of letters suffices for word recognition, but word recognition can amplify letter activation and accelerate the response.
Project amp_top_down.dist.projin Chapter_3. Distributed activation can lead to uncontrolled activation of the whole network. Two objects: TV and Synthesizer; 3 features: CRT monitor, Speaker and Keyboard. The TV has CRT and Speaker, the Synthesizer has Speaker and Keyboard – one feature in common. Amplifying DR Feedback leads to activation of layer 1, then 2, then 1 again, repeatedly. From the ctrl panel we select GridView, then Run choosing UniqueEnv input data Starting from an arbitrary activation at the input, Speaker activates both neurons, TV and Synthesizer, and all 3 features in layer 1, in effect all elements are completely active. Manipulating the value of ĝl~ 1.737 shows how unstable these networks are => we need inhibition!
We need a mechanism which reacts dynamically, not a constant leak current – negative feedback, inhibitory neurons. Inhibitory interactions What are the uses of inhibition: ?
We need a mechanism which reacts dynamically, not a constant leak current – negative feedback, inhibitory neurons. Inhibitory interactions Two types of inhibition: thanks to the use of these same input projections, we can anticipate activations and inhibit directly; this selective inhibition allows for the selection of neurons best suited to specific signals. Inhibition can also be a reaction to excessive activation of a neuron. Inhibition leads to sparse distributed representations. Feedforward inhibition: depends on the activation of the lower level Feedback inhibition: reacts to activation within the layer
A model with inhibitory neurons is costly: there are additional neurons and the simulation must be done with small increments in time to avoid oscillation. We can use simpler models with competition among neurons, leading to the selection of a generally small number of active neurons (sparse distributed representation). Inhibitory parameters Inhibitory parameters: • g_bar_i_inhib, self-inhibition of a neuron • g_bar_i_hidden, inhibition of hidden neurons • scale_ff, weight of ff connections, input-inhibition • scale_fb, weights of reciprocal connections
Winner Takes All, leaves just 1 active neuron and doesn't lead to distributed representation. In the implementation of Kohonen’s SOM the winner is chosen along with its neighborhood. Activation of the neighborhood depends on distance from the winner. Other approaches use combinations of excitatory and inhibitory neurons: McClelland and Rumelhart – interactive activation and competition; introduced the superiority of the higher layer over the lower, allowing for the supplementation of missing features and making predictions Grossberg introduced bi-directional connections between layers using minicolumnar structures with separate inhibitory neurons Layer 6 - next layer interaction poziome 2/3 feedback 4 5 inhibition poziome 6 input activation WTA and SOM approximation
k Winners Take All, the most common approximation leaving only k active neurons. Idea: inhibitory neurons decrease activation so that no more than k neurons can be active at the same time. Find the k most active neurons in the layer; calculate what level of inhibition is necessary so that only these remain above the threshold. kWTA approximation • The distribution of activation levels in a larger network should have a Gaussian character. • We have to find this level of threshold activation giQso that for a value between k and k+1 it could be balanced by inhibition: • Two methods: basic and averaged. • Weaker winners are eliminated by the minimal threshold value • kWTA model constitutes a simplification of biological interactions
Equilibrium for potential Q for which currents don't flow is established by the level of inhibitory conductance. Basic kWTA For confirmation, that only k neurons are above the threshold we take: Typically constant q=0.25; depending on the distribution of excitation across the layer, we can have a clear separation (c) or inhibit highly active neurons (b).
In this version inhibitory conductance is placed between the average of the k most active neurons and the n-k remaining neurons. Averaged kWTA An intermediate value is computed from: Depending on the distribution we have in (b) a lower value than before but in (c) a higher value, which gives somewhat better results.
Project inhib.proj in Chapter_3. Input 10x10, hidden layer 10x10 2x10 inhibitory neurons, realistic proportions. A bi-directional network has a second hidden layer; kWTA stabilizes excitation leaving few active neurons. Detailed description: section 3.5.2 i 3.5.4 Projects with kWTA Project inhib_digits.proj in Chapter_3.
Feddback with second hidden layer Projekt Ch3 inhib.proj. Switch on Bdirexcite to add the second hidden layer that include inhibitory neurons. Initial activation similar to previous, but after significantly increases after second layer is activated. Seizure:bd_hidden_g_bar.i=1.1 Increases activity of the second layer may cause activation of all neurons. In this model one can test different effects of inhibition and average kWTA.
kWTA and digits Project Ch3 inhib_digits.proj. Network with local transformations to a single output neuron, for k=1 gives unique excitations. For distributed outputs, inhibition may only give single active output neurons (which is not sufficient to solve the problem without another layer) but for larger k gives combination of 2 or 3 units.
Environmental activations, and internal inhibition and activation compatible with the fixed parameters of the network, form a set of constraints on possible states; the evolution of activations in the network should lead to satisfaction of these constraints. Constraint satisfaction • Attractor dynamics • System energy • The role of noise Changes in time, starting from the "attractor basin,” or collection of different starting stages, approach a fixed state. Attractor states maximize harmony between internal knowledge contained in the network parameters and information from the environment.
The most general law of nature: minimize energy! What does an energy function look like? Energy where the summation runs through all the neuron pairs. Harmony = -E is greatest when energy is lowest. If the weights are symmetrical then the minimum of this energy function is at a single point (point attractor); if not then attractors can be cyclical, quasiperiodic or chaotic. For a network with linear activation the output is => The derivative of harmony = yj shows the direction of growth in harmony.
Fluctuations on the quantum level as well as the input from many coincidental processes in the greater neural network create noise. Noise changes the moments of impulse transmission, helps to prevent local solutions with low harmony, supplies energy effecting resonance, breaks impasses. The role of noise Noise doesn't allow a fall into routine, enables exploration of new solutions, is also probably necessary for creativity. Noise in the motor cortex. Demonstration of the role of noise in the visual system.
Constraint satisfaction is accomplished in the network by a parallel search through the neuron activation space. Inhibition allows us to restrict the search space, speeding up the search process if the solution still exists in an accessible area of the state space. Inhibition and constraint satisfaction Without kWTA all states in the configuration of two neurons are accessible; the effect of kWTA restriction is the coordination of activation of both neurons and a decrease in the search space.
Project cats_and_dogs.projin Chapter_3. Constraint satisfaction: cats and dogs • The knowledge encoded in the network is in the table. • The exercise described in section 3.6.4 leads to • A simple semantic network which can • Generalize and define unique characteristics • Show the relationship between characteristics • Determine if characterstics are stable • Supplement missing information
Project necker_cube.proj in Chapter_3 demonstrates bistability of perception. Bistability of perception: this cube can be seen with its closest face facing either left or right. Constraint satisfaction: Necker cube Bistable processes can be simulated allowing for noise. The exercise is described in section 3.6.5.