Download

1 / 25
250 likes | 265 Views
Explore memory-based and sort-based inversion methods, index compression techniques, dynamic collections, and more to address the challenges of construction in the field of artificial intelligence research.

E N D
5.Index Construction 인공지능연구실
목차 • Memory-based inversion • Sort-based inversion • Exploiting index compression • Compressed in-memory inversion • Comparison of inversion methods • Constructing signature files and bitmaps • Dynamic collections
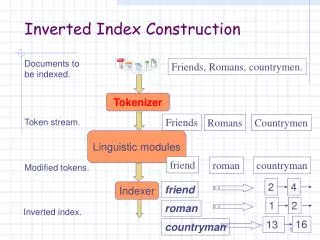
Memory-based inversion • Fig5.2, Fig5.3 • Assumed that the linked lists are sorted • Dynamic dictionary data structure • Linked list(reference point)
문제점? • 메모리 Resource 많이 필요 • the best method for small collections (Bible…) • Random Data 처리 못함
외부 Mergesort [logR] QSort <1,1,2> . . . . Sort-based inversion • Fig5.4, Fig5.5 K block Merged runs (fully sorted) Sorted runs Temporary File inital
문제점? • Two copies of temp files • 10~100Mbyte 범위에 적절
Exploiting index compression • To reduce the resource(space,time) -temporary file의 압축(sort-based) -inverted file을 main memory에서 만들고, index를 disk에 쓰기전에 decompressing • Compressing the temporary files • Multiway-merging • In-place multiway merging
Compressing the temporary files • Chapters 3 and 4장에서 설명됨 • Compression temporary file of<t,d,fdt> • t 요소때문에 약간의 압축 손실 발생 (예,unary+delta code,TREC collection) (가정) unary code t-gap(다음에오는 triple과의 t차이값) t-gap=0 → code 0, t-gap=1 → 10, t-gap=2 → 110 (0.6Mbyte 필요)
Multiway merging • Now, processor-intensive than dick-intensive • Reduce time by multiway-merge • Use if priority queue such as heap
In-place multiway merging(1) 1 OUTPUT BLOCK1 OUTPUT BLOCK3 RUN 1, BLOCK 2 2 RUN 1, BLOCK 2 OUTPUT BLOCK2 Heap RUN 2, BLOCK 2 RUN 2, BLOCK 3 RUN 3, BLOCK 1 RUN 3, BLOCK 2 Blocks in memory One per run Temporary file, On disk Block table In memory
In-place multiway merging(2) • 알고리즘 - 메모리의 각 run에서 b byte의 블록이 heap으로 이동 - heap에서 메모리내 output블록으로 b byte만큼이동 - output블록은 temporary file로 다시 쓰여짐(block table) • Slack의 사용 -입력프로세스보다 출력프로세스가 먼저 수행 되는 경향으로 빈블럭이 추가됨 Slack 추가 → permutation →compaction → truncation 처리 Second Edition) permutation → truncation 처리
Compressed in-memory inversionLarge memory inversion(1) Large main memory array - list of document numbers d, frequencies fdt Compared in-memory technique (Section 5.1) next pointer field 필요 없음. term t : ftlog N bits ftlog mt bits (mt : maximum within-document frequency ) preliminary pass 필요 : N, ft, mt
Compressed in-memory inversionLarge memory inversion(2) Two-pass Golomb-coded in memory First Pass - count ft, Ft - write ft, Ft to a lexicon file Second Pass - read lexicon file - calculate bt, btw =2log((N-ft)/ft), Bt - build a compressed in-memory inverted file - rebuild in-memory inverted file
Compressed in-memory inversionLexicon-based partitioning Subdivide into small tasks Lexicon-based, no extra disk make multiple second pass each processing one load - ex) three second pass Lexicon-based, extra disk Time save, Disk Space 낭비
Compressed in-memory inversionText-based partitioning Inversion and Merge In-memory inverted file 생성 Merge inverted file on disk Chunk Information file - frequency of each term in chunk Second temp disk file - disk current pointer
Constructing signature files and bitmaps Enough Main Memory signature of k documents k = 8M / W - W : signature width (bits) - M : main memory (bytes) Bitmap build a compressed inverted file decompress it and store it with unary code
Dynamic collections(1) ‘Insert’ operation append a new document to an existing collection ‘Edit’ operation alter, remove Expanding the text Expanding the index
Dynamic collectionsExpanding the text Inserting a new document the text of the collection must be expanded compression - cope with hitherto unseen symbol uncompression - escape flag, stored uncompressed periodically be completely rebuilt a new compression model
Dynamic collectionsExpanding the Index(1) ‘stop-press’ file accumulate update in a stop-press file rebuild when file too large drawback reindex (the data) time The Inverted file new-inserted document contains many terms variable-length recoreds
Dynamic collectionsExpanding the Index(2) Issue suitable file structure record extension record insertion
Dynamic collectionsExpanding the Index(2) Block Structure Fixed length blocks : b bytes - block address table, records, free space - figure 5.15 Main memory - record address table : record number, block number - free list - current last block of the file
Dynamic collectionsExpanding the Index(3) Access record 1) Record number 2) Block address from the record address table 3) Block read into memory 4) The address of the record within the block 5) Read the record
Dynamic collectionsExpanding the Index(4) Expanding a particular record sufficient free space 1) Block read 2) record 이동, make space 3) extension 추가 4) block table 수정, write insufficient free space - smallest record remove, insert extension - extended record remove, insert into new block
Dynamic collectionsExpanding the Index(5) Insert a record free list check - insert할 block 결정 - new block 생성 Block read/write (disk operation) general case : 2 worst case : 4 Reduce the number of disk operation using ‘update cache’