Download

1 / 48
480 likes | 504 Views
Explore how pipelining splits tasks into stages to boost performance, with examples and challenges explained in detail.

E N D
COMP541Pipelined MIPS Montek Singh Apr 9, 2012
Topics • Today’s topic: Pipelining • Can think of it as: • A way to parallelize, or • A way to make better utilization of the hardware. • Goal: Try to use all hardware every clock cycle • Reading • Section 7.5 of textbook
Parallelism • Two types of parallelism: • Spatial parallelism • duplicate hardware performs multiple tasks at once • Temporal parallelism • task is broken into multiple stages • each stage operating on different parts of distinct instructions • also called pipelining • example: an assembly line
Parallelism Definitions • Some definitions: • Token: A group of inputs processed together to produce a group of outputs • a “bundle” • Latency: Time for one token to pass from start to end • Throughput: The number of tokens that can be processed per unit time • Parallelism increases throughput • Often sacrificing latency
Parallelism Example • Ben is baking cookies • 2-part task: • It takes 5 minutes to roll the cookies… • … and 15 minutes to bake them • After finishing one batch he immediately starts the next batch. What is the latency and throughput if Ben does NOT use parallelism? Latency = 5 + 15 = 20 min = 1/3 hour Throughput = 1 tray/ 20 min = 3 trays/hour
Parallelism Example • What is the latency and throughput if Ben uses parallelism? • Spatial parallelism: Ben asks Allysa to help, using her own oven • Temporal parallelism: Ben breaks the task into two stages: roll and baking. He uses two trays. While the first batch is baking he rolls the second batch, and so on.
Spatial Parallelism Latency = ? Throughput = ?
Spatial Parallelism Latency = 5 + 15 = 20 min = 1/3 hour (same) Throughput = 2 trays/ 20 min = 6 trays/hour (doubled)
Temporal Parallelism Latency = ? Throughput = ?
Temporal Parallelism Latency = 5 + 15 = 20 min = 1/3 hour Throughput = 1 trays/ 15 min = 4 trays/hour Using both techniques, the throughput would be 8 trays/hour
Pipelined MIPS • Temporal parallelism • Divide single-cycle processor into 5 stages: • Fetch • Decode • Execute • Memory • Writeback • Add pipeline registers between stages
Single-Cycle vs. Pipelined Performance • Pipelining • Break instruction into 5 steps • Each is 250 ps long (length of longest step) Write Reg and Read Reg occur during the first half and second half of the clock cycle, respectively. This allows more instr overlap!
Pipelining Abstraction • 5 stages of execution • instruction memory (fetch) • register file read • ALU/execution • data memory access • register file write (writeback)
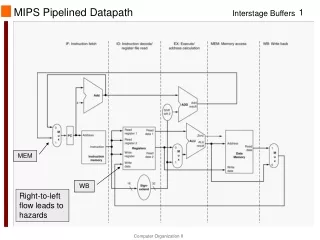
Single-Cycle and Pipelined Datapath • Key difference: insertion of pipeline registers
Multi-Cycle and Pipelined Datapath • Key difference: full-length registers for datapath and control
One Problem • There is a problem: • ResultW and WriteReg are out of step
Corrected Pipelined Datapath • Solution: One modification needed • Send both ResultW and WriteReg through an equal number of registers
Pipelined Control • What is similar/different w.r.t. single-cycle MIPS? • Same control signal values • Values must be delayed and delivered in correct cycles Control signals must go through registers as well!
Pipelining Challenges • “Hazards” • when an instruction depends on results from previous instruction that has not yet completed • 2 types of hazards: • Data hazard: register value not written back to register file yet • an instruction produces a result needed by next instruction • new value will be stored during write-back stage • new value needed by next instr during register read following too close behind! • Control hazard: don’t know which is next instruction • next PC not decided yet • cause by conditional branches • cannot fetch next instr if current branch is not yet decided
Data Hazard: Example • First instruction computes a result ($s0) needed by the next 3 instructions • first two cause problems • third actually does not!
Handling Data Hazards • Static/compiler approaches: • Insert nop’s (no operations) in code at compile time • Rearrange code at compile time • Dynamic/runtime approaches: • Forward data at run time • Stall the processor at run time
Compile-Time Hazard Elimination • Insert enough nopsbetween dependent instrs • Or re-arrange: move independent instructions earlier
Dynamic Approach: Data Forwarding • Also known as bypassing • results are actually available even though not stored in RF • grab a copy and send where needed! • Note: • forwarding actually not needed for sub. Why?
Data Forwarding • Forward to Execute stage from either: • Memory stage or • Writeback stage • Forwarding logic for ForwardAE: if ((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM) then ForwardAE= 10 else if ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW) then ForwardAE= 01 else ForwardAE= 00 • Forwarding logic for ForwardBE same, but replace rsE with rtE
Data Forwarding if ((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM) then ForwardAE= 10 else if ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW)) then ForwardAE= 01 else ForwardAE= 00
Forwarding may not always work… • Example: Load followed immediately by R-type • loads are harder to deal with because they need mem access! • need one extra cycle, compared to R-type instructions lw has a 2-cycle latency!
Stalling • Stall for a cycle, then forward • solves the Load followed by R-type problem
Stalling Control • Stalling logic: lwstall = ((rsD == rtE) OR (rtD == rtE)) AND MemtoRegE StallF = StallD = FlushE = lwstall
Stalling Control lwstall = ((rsD == rtE) OR (rtD == rtE)) AND MemtoRegE StallF = StallD = FlushE = lwstall
Control Hazards • beq: • branch is not determined until the fourth stage of the pipeline • Instructions after the branch are fetched before branch occurs • These instructions must be flushed if the branch is taken
Effect & Solutions • Could always stall when branch decoded • Expensive: 3 cycles lost per branch! • Could predict banch outcome, and flush if wrong • Branch misprediction penalty • Instructions flushed when branch is taken • May be reduced by determining branch earlier
Control Hazards: Flushing • Flushing • turn instruction into a NOP (put all zeros) • renders it harmless!
Control Hazards: Early Branch Resolution Introduced another data hazard in Decode stage (fix a few slides away)
Control Hazards with Early Branch Resolution Penalty now only one lost cycle
Aside: Delayed Branch • MIPS always executes instruction following a branch • So branch delayed • This allows us to avoid killing inst. • Compilers move instruction that has no conflict w/ branch into delay slot
Example • This sequence add $4 $5 $6 beq $1 $2 40 • reordered to this beq $1 $2 40 add $4 $5 $6
Control Forwarding and Stalling Hardware • Forwarding logic: ForwardAD = (rsD !=0) AND (rsD == WriteRegM) AND RegWriteM ForwardBD = (rtD !=0) AND (rtD == WriteRegM) AND RegWriteM • Stalling logic: branchstall = BranchD AND RegWriteE AND (WriteRegE == rsD OR WriteRegE == rtD) OR BranchD AND MemtoRegM AND (WriteRegM == rsD OR WriteRegM == rtD) StallF = StallD = FlushE = lwstall OR branchstall
Branch Prediction • Especially important if branch penalty > 1 cycle • Guess whether branch will be taken • Backward branches are usually taken (loops) • Perhaps consider history of whether branch was previously taken to improve the guess • Good prediction reduces the fraction of branches requiring a flush
Pipelined Performance Example • Ideally CPI = 1 • But less due to: stalls (caused by loads and branches) • SPECINT2000 benchmark: • 25% loads • 10% stores • 11% branches • 2% jumps • 52% R-type • Suppose: • 40% of loads used by next instruction • 25% of branches mispredicted • All jumps flush next instruction • What is the average CPI?
Pipelined Performance Example • SPECINT2000 benchmark: • 25% loads • 10% stores • 11% branches • 2% jumps • 52% R-type • Suppose: • 40% of loads used by next instruction • 25% of branches mispredicted • All jumps flush next instruction • What is the average CPI? • Load/Branch CPI = 1 when no stalling, 2 when stalling. Thus, • CPIlw = 1(0.6) + 2(0.4) = 1.4 • CPIbeq = 1(0.75) + 2(0.25) = 1.25 • Average CPI = (0.25)(1.4) + (0.1)(1) + (0.11)(1.25) + (0.02)(2) + (0.52)(1) = 1.15
Pipelined Performance • Pipelined processor critical path: Tc = max { tpcq + tmem + tsetup, 2(tRFread + tmux + teq+ tAND+ tmux + tsetup), tpcq + tmux+ tmux + tALU + tsetup, tpcq + tmemwrite + tsetup, 2(tpcq + tmux + tRFwrite) }
Pipelined Performance Example Tc = 2(tRFread + tmux + teq + tAND + tmux + tsetup ) = 2[150 + 25 + 40 + 15 + 25 + 20] ps= 550 ps
Pipelined Performance Example • For a program with 100 billion instructions executing on a pipelined MIPS processor, • CPI = 1.15 • Tc = 550 ps Execution Time = (# instructions) × CPI × Tc = (100 × 109)(1.15)(550 × 10-12) = 63 seconds
Summary • Pipelining benefits • use hardware more efficiently • throughput increases • Pipelining challenges/drawbacks • latency increases • hazards ensue • energy/power consumption increases • All modern processors are pipelined • some have way more than 5 pipeline stages • some Pentium’s have had 20-40 pipeline stages!