Download

1 / 49
490 likes | 509 Views
Explore how RDF addresses Babelization, versioning, and lack of consistent semantics in SOA, enabling data integration and model unification.

E N D
RDF and SOA David Booth, Ph.D. <dbooth@hp.com>HP Software 2007-02-27 Latest version: http://dbooth.org/2007/rdf-and-soa/rdf-and-soa-slides.ppt These slides are based on the paper at http://dbooth.org/2007/rdf-and-soa/rdf-and-soa-paper.htm
Some issues mentioned yesterday • Ken: "Someone walks in with a 40 page schema, and someone else walks in with a 60 page schema" • Namespace/vocabulary/schema management problem • Chris: "that concept is almost what I need, but not quite, so I need to define my own" • Paul: "Super billing system, with everyone's features" • Jonathan: "Top down policy enforcement is bucking the tide" • Skip: "too difficult to reuse [schemas]" • Nick: "I see customers spending 80% of their time on getting their documents right, not on the interfaces or how to exchange them" • Ben: "WS interop doesn't solve my problem. I need my services to interoperate"
Outline • The problem with XML in SOA • Babelization • Versioning • What's wrong with "THE model" • Lack of consistent semantics across models • The case for RDF in SOA • Data integration • Consistent semantics • Versioning • Validation • Bridging between XML and RDF • XML as an RDF serialization
Problem 1: Babelization • Success of Web services causes new challenges • Each Web service defines its own interface: • XML messages in/out • WSDL doc describes a “language” for interacting with that service • As services multiply, these languages multiply • What do the messages mean? • Result: “Babelization” (http://www.w3.org/2002/Talks/1218-semweb-dbooth/slide43-0.html )
Babelization impedes integration • Each service speaks its own language • Cannot easily connect them in new ways • Each message type has its own data model • Cannot easily integrate data
Problem 2: Versioning • Need to be able to independently version both clients and services • XML is brittle • Versioning is a constant problem
History of data model design in XML • Version 1: This is the model. • Version 2: Oops! No, *this* is the model. • Version 3: This is the model today, but here's an extensibility point for tomorrow. . . . Then, after integrating with another model: • Version 4: This is the *super* model (with extensibility for tomorrow, of course). . . . Eventually, after integrating with more models: • Version 5: This is the super-duper-*ultra* model (with extensibility, of course) • etc.
Schema Hell • Model gets very complex • Each app/component only uses one part of it • Lots of optionality: hard to know what is really used • Example: RosettaNet Purchase Order • Over 500 elements, 75% optional • Trading partners take 2-3months to negotiate through optionality
Moral: There is no such thing as THE model. • There are many models. There always will be. • Standard model is always beneficial when practical • But only possible in the micro -- not the macro • Why? • Different apps need different models • Hard to get agreement as org/committee grows • App needs change over time • Org changes over time
Problem 3: No consistent semantics • 1000s of applications • 1000s of schemas • How do they relate to each other? • <foo:CustAddress> == <bar:ShippingAddr>
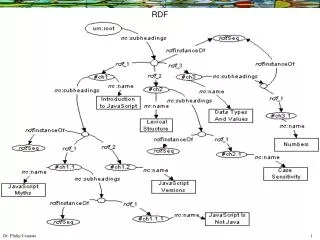
RDF • Relational data model framework • W3C standard >6 years • Language for making statements about things • Used to express both: • Ontologies (with OWL), and • Instance data
Key features of RDF • Syntax independent (specifies model) • Some existing serializations: RDF/XML, N3, Turtle • Consistent semantics • Based on URIs • Great for data integration problems • Data "mashups"
Why RDF excels at data integration • New data models can be easily added • Old and new data models co-exist in merged model • Relationships between the old and new models are expressed explicitly • Both old and new can be used simultaneously
Red App has model • Need to integrate Red & Blue models into new Green model. How?
Model integration in XML • Option 1: Red and Blue models become subtrees of Green model • Very little gained • Relationships are implicit in the processing code • Option 2: Design a new model • How is it different in RDF?
Step 1: Merge RDF • Same nodes (URIs) join automatically
Step 2: Add relationships between Red & Blue models • (Relationships are also RDF)
Step 3: Define Green model • (Making use of Red& Blue models)
What the Blue app sees • No difference!
What the Red app sees • No difference!
Consistent semantics • RDF facilitates consistent semantics • Terms have the same meaning across apps • Based on URIs • Semantics of different terms can be related declaratively • ESB can convert formats, but give no assurance of consistent semantics • Example: Security entitlements across applications
Versioning of message models • RDF makes message model versioning easier: • Syntax independence • Open World Assumption (OWA) • RDF does not address process flow versioning • REST addresses that • RDF : message models :: REST : process flow
Document Validation • XML is closed world (normally) • RDF uses open world assumption (normally) • Validation requires different approaches • There are pros and cons
Example: Missing data in XML vs. RDF • Suppose: • Address requires a city name, but • City name is missing • Q: CityName == "New York"? • In XML (closed world assumption): • Error. • In RDF (open world assumption): • Sure, why not? (No evidence to the contrary)
Validation in RDF • Techniques are available • World can be temporarily closed • Sample SPARQL query can check data • If query succeeds, data is complete • Tools can also help detect errors (e.g., Eyeball, by Chris Dollin, HP Labs Bristol)
Validating Messages • WSDL use is lopsided: • Written solely from the perspective of the service • Specifies input and output schemas • Service may not know how its clients use its data!
Kinds of Data Validation • Model integrity • Same for producer and consumer • Suitability for a particular use • Differs for producer and consumer
Producer Versus Consumer Validation • Data producer should provide validator for data it creates (model integrity) • E.g., sample SPARQL query • Data consumer should provide validator for data it expects (suitability for use) • E.g., sample SPARQL query
RDF and efficiency • RDF is not inherently inefficient • If you need the work done, it must happen somewhere • Jena, Arq, etc., are pretty good • There *is* a learning curve for RDF • Must learn what is efficient and inefficient, just as in programming and RDBMS queries • Can process directly in XML if RDF power is not needed
Fundamental Trends • Need for easier service and data integration is increasing • Flooded with data • Continually integrating new models & services • Need for consistent semantics is increasing
But Web services already use XML! • XML is well known and used • Legacy apps may require specific XML or other formats that cannot be changed • Standard RDF/XML serialization is verbose & ugly • How can we gain the benefits of RDF while still accommodating XML?
Recall: RDF is syntax independent • Specifies info model -- not syntax! • Can be serialized in any agreed-upon way • Can define specialized RDF serializations!
Defining new RDF serializations • New XML (or other) formats can be defined as specialized serializations of RDF • Mapping converts XML/other to RDF • XSLT/other can define mapping • Namespace or GRDDL can specify transformation • Analogous to microformats or micromodels, but: • not restricted to HTML/xhtml • not necessarily using standards-based ontologies • Can use app-specific ontologies
Mapping existing formats to RDF • Existing XML/other formats also can be mapped to RDF • Treat as specialized RDF serializations • XSLT/other can define mapping • Allows service to treat XML/other input as RDF • Both old & new formats
Documents on the wire can be XML, other or RDF Input can be normalized to RDF App processing can use RDF engine/store Normalizing to RDF Service RDF Normalizeto RDF XML/other Core appProcessing RDF Engine / Store Client
Different clients may require different formats: versions, etc. Can even change dynamically Can be normalized to RDF for common processing Core app is unaffected Supporting multiple client formats Service RDF Normalizeto RDF XML/other Core appProcessing RDF Engine / Store Client
Serialize to whatever formats are required Generate XML/other directly (or even RDF!), or SPARQL query can generate specific view virst Service Output Service Normalizeto RDF Core appProcessing RDF Engine / Store Client Serialize asXML/other/RDF
Granularity • Mapping from XML to RDF can be done with any level of granularity • Fine grained: • Every element, attribute, etc., in XML maps to 1+ RDF assertion • Permits more detailed inferences • Adds more complexity & processing up front • Coarse grained: • Entire chunk of XML maps into RDF • XML chunk is retained • RDF metadata can annotate XML chunk • Simpler, less processing up front • Information inside chunk is less accessible
Choosing appropriate granularity Consider: • What is significant from a distributed systems perspective? • What may be interpreted differently by someone else if its semantics are not pinned down? • When finer granularity is added later, differences may show up
Summary of Principles for RDF in SOA • Define interface contracts as though message content is RDF • Permit custom XML/other serializations as needed • Provide machine-processable mappings to RDF • Treat the RDF version as authoritative • Client and service should each provide both: • A model integrity validator for data it creates; and • A suitability for use validator for data it expects. • Choose RDF granularity that makes sense
Conclusions • Value of RDF in data integration is well proven • We have some evidence of its value in SOA, but need: • More exploration of graceful adoption paths • More work on transformation techniques • More work on validating RDF models in SOA context • Best practices for the above