Download

1 / 12
120 likes | 277 Views
Document Centered Approach to Text Normalization. Andrei Mikheev LTG University of Edinburgh SIGIR 2000. Abstract. Three problems of text normalization: Sentence Boundary Disambiguation (SBD)

E N D
Document Centered Approach to Text Normalization Andrei Mikheev LTG University of Edinburgh SIGIR 2000
Abstract Three problems of text normalization: • Sentence Boundary Disambiguation (SBD) • Disambiguation of capitalization when words are used in positions where capitalization is expected • Identification of abbreviations Use of the Document Centered Approach methods to reduce sentence boundary disambiguation with pre-built resources from existing corpora (i.e. Wall Street Journal and Brown)
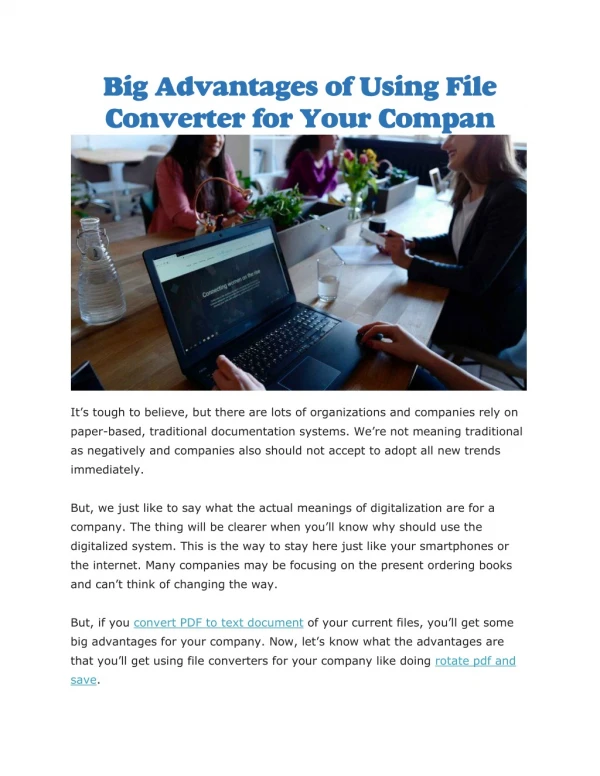
Introduction • Text cleaning and normalization is used to develop text processing and Information Retrieval applications. • Text normalization begins with disambiguation of capitalized words • Capitalization is expected for proper names, locations, people etc. • Ambiguity is presented with mandatory rule of capitalization in special positions (e.g., at the start of a sentence) • Disambiguation of capitalized words in ambiguous positions (also known as normalization) leads to identification of proper names • Study conducted by Church reflects: • reference to same thing/object (e.g., hurricane and Hurricane) • reference to different thing/object (e.g., apple [fruit] and Apple [computer])
Introduction (cont.) • Disambiguation serves toward sentence splitting/sentence boundary disambiguation (SBD) • Sentence splitting: the process of creating a sentence boundary using punctuation such as “!”, “?”, “.” • Periods can serve one or several roles at once: • splitting text information • denoting decimal points • denoting an abbreviation
Our Approach to SBD (Sentence Boundary Disambiguation) • Experiment began with use of Wall St. Journal corpus and the Brown corpus • Three tasks involved with both corpora • Sentence Boundary Disambiguation • Capitalized Word Disambiguation • Abbreviation Identification • Human-involved, labor-intensive programming of both corpora to recognize: • abbreviations that are followed by proper names (e.g., Mr. White) • abbreviations which are single-word, short and, in most cases, do not include vowels (e.g. kg., ft., etc.) • abbreviations consisting of a series of capitalized single letters separated by periods (e.g., Y.M.C.A., U.C.L.A., A.L.A., etc.) • With programming, error rates still proved to be too high within both corpora (15-16% error rate)
Document-Centered Approach • Document-Centered Approach (DCA): reviewing entire document to formulate disambiguation as it relates to capitalization of proper names and abbreviations • Generalized Principles for the DCA method: • if a word has been capitalized in an unambiguous position, this increases the probability that it is a proper name (e.g., “The Riders [as in the Rider family] said….”) • if a short word (e.g., “in.” standing for inches) is followed by a period, but occurs elsewhere in the document without a period, the likelihood is that it is not an abbreviation
Getting Abbreviations • Recognition of abbreviations process begins with using existing abbreviation lists • Enhancing existing abbreviation lists (which may be incomplete for existing document) by: • collecting unigram forms of abbreviations from existing document (e.g., Sun., which can stand for Sunday or the newspaper) • collecting bigram forms of abbreviations, which are made up of two words but recognized as one word (e.g., “Vitamin C.”)
Getting Capitalized Words • Disambiguation of capitalized words using the following methods: • The Sequence Strategy: the process of exploring sequences of proper nouns in unambiguous positions • Frequent List Lookup Strategy: a pre-programmed compilation of words that are frequently capitalized to denote proper names • Single Word Assignment: the process of reviewing the entire document to determine whether capitalized words in the document act as proper names • The “After Abbr.” Heuristic: the process of determining a proper name, when a capitalized word follows a capitalized abbreviation, the capitalized word is, in most cases, certainly a proper name
Getting Capitalized Words (cont.) • The Overall Performance: upon applying the four methods above, the final disambiguation results were: • 9% ambiguously capitalized words unclassified in Brown Corpus • 15% ambiguously capitalized words unclassified in Wall Street Journal Corpus • Ranking of the methods achieving best results for classifying ambiguously capitalized words: • Single Word Assignment • “After Abbr.” Strategy • Sequence Strategy
Assigning Sentence Breaks • The process of correctly recognizing the end of an idea, thought or statement, where a small, and in some cases, non-voweled word followed by a period and then by a lower cased word, we can assume that the small word is an abbreviation
Related Research • Two types of existing SBD systems: • Rule based system: A system comprised of manually built rules, encoded with lists of proper names, abbreviations, common words, etc. to recognize where sentences break within a document • Machine learning system: A system employing the use features such as word spelling, capitalization, suffix, word class, etc. to recognized potential sentence breaking punctuation • Examples of machine learning systems developed by: • Kuhn and de Mori • Clarkson and Robinson • Mani&MacMillan • Gale, Church and Yarowsky
Discussion • Final results of the Document Centered Approach: • This approach proved to be comparable to or even better than existing approaches • This approach does not require any human intervention for training • Simplicity of this approach resulted in high-running speed • This approach does not rely on pre-compiled statistics • Easy implementation, without installing new software • This system can be customized for specific domain usage