Download
1 / 37
500 likes | 1.55k Views
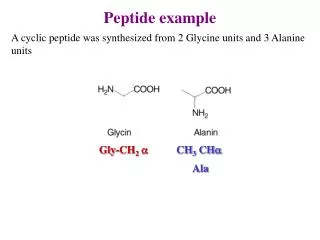
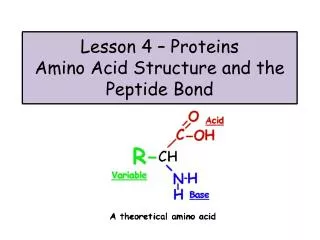
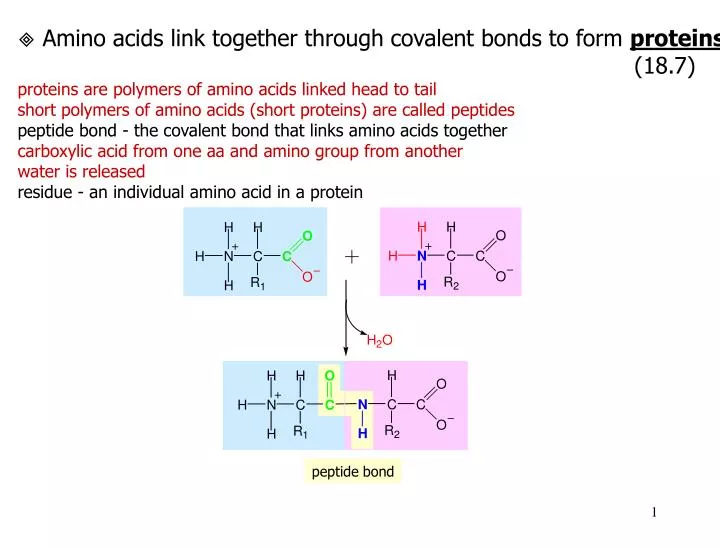
peptide bond. Amino acids link together through covalent bonds to form proteins (18.7) proteins are polymers of amino acids linked head to tail short polymers of amino acids (short proteins) are called peptides peptide bond - the covalent bond that links amino acids together

E N D
peptide bond Amino acids link together through covalent bonds to form proteins (18.7) proteins are polymers of amino acids linked head to tail short polymers of amino acids (short proteins) are called peptides peptide bond - the covalent bond that links amino acids together carboxylic acid from one aa and amino group from another water is released residue - an individual amino acid in a protein
R1R2 amino terminus carboxyl terminus R2R1 Peptides and proteins are directional amino terminus - end with free amino group carboxyl terminus - end with free carboxylic acid group proteins are synthesized and specified from the amino to carboxyl terminus when writing peptide names using full aa names, drop the “ine” from each aa except the carboxyl end and replace with “yl”
Threonine and valine can combine to form two different dipeptides. Draw them and write their names using full names, three letter and one letter abbreviations.
Identify the amino acids in the following dipeptide and tripeptide, and write their names using full names, three letter and one letter abbreviations.
the electrons in the double bond here, are shared a lot with this bond (the C-N bond) The peptide bond has partial double bond character you cannot rotate around the C=O or C-N bonds. causes the peptide bond and protein backbone to be planar (flat) side chains alternate above and below plane The peptide bond is trans the carboxyl oxygen and amide hydrogen are on opposite sides to minimize steric interactions of the oxygen and hydrogen (overlapping of e- clouds = repulsion)
Four Tiers of Protein Structure (18.8-18.11) Primary structure (1° structure) amino acid sequence of the protein written from amino to carboxyl terminus The amino acid sequence determines its 3D structure (which then determines its properties.) depends solely on covalent bonds Why determine primary structure? 1. Determining primary structure is the first step in characterizing a protein - can help determine the function of a protein by comparison to other protein sequences 2. primary structure determines 3D structure (which then determines its properties.) 3. changes in 1° can make protein fold differently or cause disease (sickle cell anemia results from a change of 1 amino acid in hemoglobin glu to val) 1° Structure determines 3D shape and therefore protein function (or dysfunction)
Experimental determination of 1° structure STEP 5 STEP 6
- 2 3 4 5 n COO + H3N Experimental determination of 1° structure Split the protein into several tubes Step 1 - use for amino acid constituent analysis Determine which amino acids are present and in what proportions use high acid concentration and high temps (100-110 C) for 12-36 hours hydrolyzes peptide bonds determines number of possible cleavage sites for steps 3 and 4. resulting solution put through an amino acid analyzer to aa present and ratios only identifies which amino acids are present and ratios- not their order Step 2 - use for end group analysis Identify N-terminal and C-terminal amino acids can be used to determine the number of polypeptide chains - process is automated N-terminal Edman degradation reliable for polypeptide chains up to 40-60 amino acids + - 1 2 3 4 5 n H3N COO Original peptide Phenyl isothiocyanate (Edman’s reagent) - 1 2 3 4 5 n COO Modified peptide Can be used in another round as in steps 3 and 4 amino acid derivative can be easily identified +
- COO - n COO Step 2 (cont.) C-terminal Enzymatic analysis with carboxypeptidases carboxypeptidases are exopeptidase (cleave end bonds) Four carboxypeptidases are used since not one enzyme will use each aa as substrate “ase” is the ending given to denote an enzyme Carboxy means it works on the carboxyl end of the protein Peptid because they cleave peptide bonds + - n-1 n 1 2 3 4 5 H3N COO Original peptide Treat with carboxypeptidases H2O + n-1 1 2 3 4 5 H3N + amino acid is easily identified
chymotrypsin N-ala-ser-phe-pro-lys-gly-gly-met-arg-trp-asp-met-gly-tyr-lys-ala-cys-C CN-Br trypsin Steps 3 and 4- Fragmentation of the Polypeptide Chain goal is to produce the correct size polypeptide fragments for sequencing through Edman degradation (Step 4 below) automated Edman is reliable for polypeptide chains up to 40-60 amino acids most proteins are >100 aa so the protein must be broken into fragments break up large protein into smaller polypeptides using endopeptidases & cyanogen bromide Site Specific peptidases - enzymes that cleave peptide bonds at very specific sites in the protein Most commonly used endopeptidases: Enzyme name Peptide bond cleavage Specificity Trypsin cleaves after R or K amino acids Chymotrypsin cleaves after Y, W, and F Commonly used chemical: cyanogen bromide (CN-Br) - cleaves after M will see all fragments end in M except 1 and that is the carboxyl end of the protein
chymotrypsin ala-ser-phe-pro-lys-gly-gly-met-arg-trp-asp-met-gly-tyr-lys-ala-cys CN-Br trypsin Chymotrypsin digestion yields 4 fragments (remember, their sequences are unknowon at this time): ala-ser-phe pro-lys-gly-gly-met-arg-trp asp-met-gly-tyr lys-ala-cys Trypsin digestion yields 4 fragments also: ala-ser-phe-pro-lys gly-gly-met-arg trp-asp-met-gly-tyr-lys ala-cys Cyanogen bromide digestion yields 3 fragments: ala-ser-phe-pro-lys-gly-gly-met arg-trp-asp-met gly-tyr-lys-ala-cys
What fragments are produced by trypsin, chymotrypsin, and CNBr digestion of the following peptides? 1) gly-met-lys-gly-ala-cys-met-asp-trp-arg-met-val-tyr-iso-ala-cys-met-phe-leu Trypsin fragments gly-met-lys gly-ala-cys-met-asp-trp-arg met-val-tyr-iso-ala-cys-met-phe-leu Chymotrypsin fragments gly-met-lys-gly-ala-cys-met-asp-trp arg-met-val-tyr iso-ala-cys-met-phe leu CNBr fragments gly-met lys-gly-ala-cys-met asp-trp-arg-met val-tyr-iso-ala-cys-met phe-leu 1) VGCMAWGYLEMTSRGGF Trypsin fragments VGCMAWGYLEMTSR GGF Chymotrypsin fragments VGCMAW GY LEMTSRGGF CNBr fragments VGCM SWGYLEM TSRGGF
Step 5- Sequence determination of each polypeptide from steps 3 and 4 step 4 produces polypeptides whose sequences are still unknown. So, each polypeptide produced from digestion with trypsin, chymotrypsin, or cyanogen bromide treatment undergoes Edman degradation to determine its sequence. Step 6 - Fragment alignment The sequences of the fragments determined in step 5 are put together like a puzzle to produce the sequence of the original protein. Example: A solution of a small protein of unknown sequence was divided into two samples. One sample was treated with trypsin and the other with chymotrypsin. The smaller peptides obtained by trypsin treatment had the following sequences: Leu-Ser-Tyr-Ala-Ile-Arg Asp-Gly-Met-Phe-Val-Lys The smaller peptides obtained by chymotrypsin treatment had the following sequences: Val-Lys-Leu-Ser-Tyr Ala-Ile-Arg Asp-Gly-Met-Phe Deduce the sequence of the original protein. Trypsin treatment indicates 2 basic aa in the peptide, one of which must be the c-terminal aa - otherwise another fragment would have been produced that lacked a basic residue at the c end - like in chymotrypsin, there is a piece that does not have an aromatic at the end.
Secondary structure (2° structure) common structures in proteins that result from H- bonding of the backbone atoms only (the carbonyl and amide nitrogen) The a-Helix (alpha-helix) polypeptide backbone coils around an imaginary pole (like a telephone cord) in the figure on the left, green lines denote hydrogen bonds between the oxygen of C=O and the hydrogen of N-H In this figure, the side chains of the amino acids are shown in green and purple. Note how they stick out of the helix perpendicular to the direction of the helix. Most common 2° structure found in proteins. If you combine all of the amino acids from all proteins whose structures are known, 1/3 of the aa are found in an helix
Some proteins are composed entirely of a-helices There are 7 a-helices in this polypeptide. This polypeptide is part of hemoglobin. Hemoglobin has four of these polypeptides (called “subunits”) that interact non-covalently.
H-bonds are between the oxygenof a carbonyl and the amide hydrogen4 amino acids away What holds an alpha-helix together? Hydrogen bonds between carbonyl and amide nitrogen four aa away hydrogen bonds shown by dotted lines
The b-Sheet (beta-sheet) polypeptide backbone is stretched out like an extended accordion There are two kinds of b-sheets parallel anti-parallel
Antiparallel b-sheet with 5 strands H-bonds are between the oxygenof a carbonyl and the amide hydrogen on another strand Strand 1 Strand 3 Strand 5 Strand 2 Strand 4 What holds a beta-sheet together? Hydrogen bonds between carbonyl and amide nitrogen
Some proteins are composed almost entirely of b-sheets neuraminidase from influenza virus (pdb code 1EUU) Retinol binding protein (pdb code 1ggl)
Some proteins have both a-helices and b-sheets Carboxypeptidase (digestion protease) (pdb code 5CPA) Hexokinase (glycolysis) (pdb code 5CPA)
Tertiary structure (3° structure) overall 3D shape of all of the atoms in the protein (not just those involved in a-helices or b-sheets) proteins have different 3D shape compared to each other (though same family are similar) but each carboxypeptidase folds the same as every other carboxypeptidase secondary structure - interactions of backbone atoms tertiary structure - mainly results from interaction of side chains far apart in primary sequence or side chain-backbone interactions - residues far apart in primary sequence can be close together in space hydrophobic residues usually buried interior and hydrophilic on exterior Shape determining interactions in proteins 1. Hydrophobic interactions between non-polar side chains 2. H-bonds between side chains 3. H-bonds between backbone atoms 4. H-bonds between a side chain and a backbone atom 5. Salt bridge (ionic attraction between charged side chains) 6. Disulfide bonds (covalent bond between cysteine residues)
Quaternary structure (4° structure) some proteins have more than one amino acid chain (called subunits) that interact non-covalently. The arrangement of these subunits with each other is 4° structure. dimer - protein with 2 subunits (2 non-covalently linked polypeptide chains) trimer - protein with 3 subunits tetramer - protein with 4 subunits Examples: Hemoglobin - tetramer ATP Synthase - trimer
Sickle Cell Diseases Group of diseases affecting shape and oxygen carrying capacity of red blood cells. mainly affects persons of African or Mediterranean descent (Italian, Spanish) Inherited diseases - not contagious Diseases are diseases of the protein hemoglobin result from mutations in hemoglobin genes or lack of production of hemoglobin autosomal recessive diseases Disease and Protein Structure beta chain (146 aa) alpha chain (141 aa) beta chain (146 aa) Heme alpha chain (141 aa) oxygen binds here Hemoglobin is a tetramer
Hemoglobin genes two sets of hemoglobin genes - one set from mother and one set from father each set contains 2 alpha genes (chromosome 16) and 1 beta gene (chromo 11) gives a total of 4 alpha genes and 2 beta genes in normal hemoglobin production, the amt. of alpha produced=amt of beta alpha and beta chains have only 20% sequence homology but virtually identical 3D Types of hemoglobin: Hemoglobin A - normal hemoglobin - normal alpha and beta chains Hemoglobin F - fetal hemoglobin - has higher affinity for oxy than Hgb A - production declines by 6 months of age - normal alpha chains; beta replaced by gamma chains Hemoglobin S - normal alpha chains, mutated beta chainwhere Glu-6 is replaced by Val - sickle cell Hemoglobin C genes - normal alpha genes, mutated beta geneswhere Glu-6 is replaced by lys beta-thalassemia - normal genes but less beta produced alpha - thalassemia - normal genes but less alpha produced
AA AS AS AS AA AA AS AS SS AA AA AS AS Sickle Cell Disease is not necessarily Sickle Cell Anemia Common Types of Hemoglobin proteins 1) Hemoglobin AA - normal, healthy hemoglobin 2) Sickle Cell Trait (AS) - alpha genes normal - one normal beta gene, one beta sickle - healthy and will have no symptoms associated with sickle cell disease. - both normal and sickle hemoglobin produced; mostly normal since a binds to b better 3) Sickle Cell Anemia (SS) - alpha genes normal - two sickle beta genes 4) Sickle C Disease (SC) - alpha genes normal - one sickle beta gene - one hemo C disease 5) Sickle beta-thalassemia (S/b-thalassemia) - alpha genes normal - one sickle and thala Sickle Cell Trait Pedigree Sickle Cell Anemia Pedigree
normal red blood cells sickle red blood cells Sickle hemoglobin has same affinity for oxygen as normal hemoglobin but in low oxygen areas (veins and venous capillaries), hemoglobin molecules clump together clumping causes together causing red blood cells to become sickle in shape and become hard sickle, hard red blood cells don’t flow through capillaries as easily - get caught and block capillaries blocking blood and oxygen flow to tissues shortness of breath, stokes, fatigue, infections, jaundice, lung blockage, leg ulcers, bone damage, kidney damage, eye damage, and obviously low rbc counts. Normal rbc survive about 120 days but sickle rbc usually last 20 days - sickle cell patients have less rbc and so less hemoglobin
Hemoglobin Clumping in Sickle Cell Anemia: Hemoglobin molecules clump under low oxygen concentrations (venous blood) due to hydrophobic interactions between different hemoglobin molecules Hbg S - Glutamic acid at position 6 of the beta chains are mutated to valine - Hydrophobic patch on the beta chain of another hemoglobin molecule - val-6 and hydrophobic patch (ala, phe, leu) interact
Diagnosing Sickle Cell Disease Electrophoresis - uses a gel to separate molecules based on size, charge and/or shape - At the pI of a specific protein - the protein molecule carries no net charge and does not migrate in an electric field. - At pH above the pI - the protein has a net negative charge and migrates towards the anode (the positive end). - At pH below the pI - the protein obtains a net positive charge on its surface and migrates towards the cathode (the negative end). For proteins of same size, migration depends on net charge - the more negatively charged, the faster the migration towards anode cathode anode
Hemoglobin electrophoresis Test that determines the types of hemoglobin in a patient different forms of hemoglobin will migrate in an electric field differently because of different charges: Hemoglobin A Hemoglobin S - changes glutamic acid (neg) to valine (neutral) - one less negative than A per beta chain so 2 less neg total Hemoglobin C - changes glutamic acid (neg) to lysine (pos) - two less negative than A and one less than S per chain - so, four less than A and two less than S origin Cathode (-) Hbg C Hbg S Power Supply Hbg A Anode (+)
Patient 3 Patient 1 Patient 2 Patient 4 Patient 5 Patient 6 Control Control origin C - S Patient Disease 1 2 3 4 5 6 F A + Determine the type of hemoglobin disease (if present) in patients whose hemoglobin electrophoresis patterns are as follows:
Disease and Protein Structure (Application on pg. 533) Prions - “proteinaceous infectious particles” In 1997, Stanley Prusiner (a neurologist) won the Nobel Prize for Physiology and Medicine for discovering prions prions are naked proteins that infect and destroy brain tissue first time something other than organisms containing nucleic acid could replicate and cause disease - met w/ high level of criticism - eventually most accepted hypothesis Spongiform Encephalopathy - general category of diseases caused by prions Brains infected with prions look like a sponge. The holes are areas of brain cells that have died as a result of prion infection. Takes the form of a sponge Greek for brain Greek for disease Symptoms: dementia, Involuntary and irregular jerking movements, loss of vision, speech, coordination, depression, withdrawal
Prion diseases affect many species can be inherited or acquired: Prion diseases can be a genetic disorder or can be acquired through: 1) Eating infected animal parts (brain/spinal cord) - cross species2) Brain surgery - prions remain infectious on surgical instruments after sterilization3) Corneal transplant 4) Contaminated growth hormone from pituitary glands5) spontaneous mutation
PrPc PrPsc Prions are Molecular Transformers Key players: PrPc - protein normally attached outside nerve cells in brain - mainly a-helical (“c” for cellular) Prpsc - identical in sequence to Prpc but is - mainly b-sheet (“sc” for scrapie) - over-abundant in brain tissue of scrapie sheep Prion theory: Prpsc has identical primary structure to Prpc but has a different 3D shape. Prpsc causes Prpc to change shape into more Prpsc which clog cells because normal cellular enzymes that destroy proteins are ineffective against Prpsc. Prpsc eventually causes infected cells to lyse which releases Prpsc into adjacent brain tissue to recruit even more Prpc to change shape - cycle continues. Nothing added - nothing deleted - just a change in shape!
Evidence that Prions are Proteins When PrPsc is purified, scrapie infectivity is also purified The amount of PrPsc directly coincides with infectivity levels Procedures known to destroy nucleic acids do not destroy prion infectivity PrP gene mutations that lead to inherited prion disease also produce PrPsc Over-production of PrP increases rate of prion disease PrP knock-out mice did not get prion disease after inoculation with prion material
Destroying Protein Structure (Section 18.12) Protein denaturation Protein hydrolysis - hydrolysis of peptide bonds to produce amino acidsdestroys all levels of protein structure - even primary Protein denaturation - protein unfolding - primary structure still intact primary structure intact Review: What forces hold proteins in a specific 3-D shape? Hydrogen bonding van der Waals salt bridges hydrophobic dipole-dipole
Methods of protein denaturation pH changes - cause amino acids to alter their protonation state so can destroy hydrogen bonding and salt bridgesionic concentration - high salt out-competes amino acids for each othertemperature - increased thermal motions break energy barriers - supplies enough energy to overcome the forces holding a molecule togethermechanical agitation - beating of egg whites causes proteins to denature detergents - makes solution more hydrophobic so protein unfolds organic compounds - polar solvents like acetone and ethanol - make solution more hydrophobic and also compete for hydrogen bonding with amino acid side chains reducing/oxidizing agents - break/form disulfide bonds most denaturation is reversible but there are many cases where the protein can renature when the reason for its denaturation is removed.