Download

1 / 45
520 likes | 830 Views
Introduction to CUDA heterogeneous programming. Katia Oleinik koleinik@bu.edu Scientific Computing and Visualization Boston University. Architecture. NVIDIA Tesla M2070: Core clock: 1.15GHz Single instruction 448 CUDA cores 1.15 x 1 x 448 = 515 Gigaflops double precision (peak)

E N D
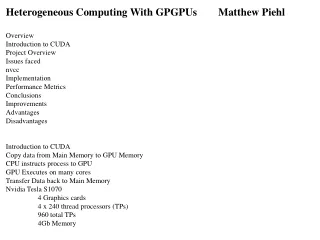
Introduction to CUDAheterogeneous programming Katia Oleinikkoleinik@bu.eduScientific Computing and VisualizationBoston University
Architecture NVIDIA Tesla M2070: Core clock: 1.15GHz Single instruction 448 CUDA cores 1.15 x 1 x 448 = 515 Gigaflops double precision (peak) 1.03 Tflops single precision (peak) 3GB total dedicated memory Delivers performance at about 10% of the cost and 5% the power of CPU
Architecture • CUDA: • Compute Unified Device Architecture • General Purpose Parallel Computing Architecture by NVIDIA • Supports traditional OpenGL graphics
Architecture Memory Bandwidth: the rate at which data can be read from or stored into memory, expressed in bytes per second Tesla M2070: 148 GB/s Intel Xeon X5650: 32 GB/s
Architecture • Tesla M2070 Processor: • Streaming Multiprocessors (SM): 14 • Streaming Processors on each SM: 32 Total: 14 x 32 = 448 Cores Each Streaming Multiprocessor supports 1024 threads.
Architecture CUDA: SIMT philosophy: Single Instruction Multiple Thread Computationally intensive—The time spent on computation significantly exceeds the time spent on transferring data to and from GPU memory. Massively parallel—The computations can be broken down into hundreds or thousands of independent units of work.
Architecture # Copy tutorial files scc1 % cp –r /scratch/katia/cuda . # Request interactive session on the node with GPU scc1 % qrsh –l gpus=1 # Change directory scc1-ha1 % cd deviceQuery # Set Environment variables to link to CUDA 5/0 scc1-ha1 % module load cuda/5.0 # Execute deviceQuery program scc1-ha1 % ./deviceQuery
Architecture Information that we will need later in this tutorial: CUDA Driver Version / Runtime Version 5.0 / 5.0 CUDA Capability Major/Minor version number: 2.0 Total amount of global memory: 5375 MBytes (14) Multiprocessors x ( 32) CUDA Cores/MP: 448 CUDA Cores Total amount of constant memory: 65536 bytes Total amount of shared memory per block: 49152 bytes Total number of registers available per block: 32768
CUDA Architecture Information that we will need later in this tutorial: Warp size: 32 Maximum number of threads per multiprocessor: 1536 Maximum number of threads per block: 1024 Maximum sizes of each dimension of a block: 1024 x 1024 x 64 Maximum sizes of each dimension of a grid: 65535 x 65535 x 65535
CUDA Architecture Query device capabilities and measure GPU/CPU bandwidth. This is a simple test program to measure the memcopy bandwidth of the GPU and memcpy bandwidth across PCI-e # Change directory scc1-ha1 % cd bandwidthTest # Execute bandwidthTest program scc1-ha1 % ./bandwidthTest
CUDA Terminology CUDA: Host The CPU and its memory (host memory) Device The GPU and its memory (device memory)
CUDA: C Language Extensions • CUDA: • Based on industry-standard C • Language extensions allow heterogeneous programming • APIs for memory and device managing
Hello, Cuda! CUDA: Basic example HelloCuda1.cu #include <stdio.h> int main(void){ printf("Hello, Cuda! \n"); return(0); } To build the program, use nvcc compiler: scc-he1: % nvcc -o helloCuda1 helloCuda1.cu
Hello, Cuda! CUDA Language closely follows C/C++ syntax with minimum set of extensions: Function to be executed on the device(GPU) and called from host code __device__ void foo(){ . . . } NVCC compiler will compile the function that run on the device and host compiler (gcc) will take care about all other functions that run on the host (e.g. main() )
Hello, Cuda! CUDA: Basic example HelloCuda2.cu #include <stdio.h> __global__ voidcudakernel(void){ printf("Hello, I am CUDA kernel ! Nice to meet you!\n"); }
Hello, Cuda! CUDA: Basic example HelloCuda2.cu int main(void){ printf("Hello, Cuda! \n"); cudakernel<<<1,1>>>(); cudaDeviceSynchronize(); printf("Nice to meet you too! Bye, CUDA\n"); return(0); }
Hello, Cuda! CUDA: Basic example HelloCuda2.cu cudakernel<<<N,M>>>(); cudaDeviceSynchronize(); Triple angle brackets indicate that the function will be executed on the device (GPU). This function is called kernel. Kernel is always of type void. Program returns immediately after launching the kernel. To prevent program to finish before kernel is completed, we have call cudaDeviceSynchronize().
CUDA: C Language Extensions There is a number of cuda functions: Device management: cudaGetDeviceCount(), cudaGetDeviceProperties() Error management: cudaGetLastError(), cudaSafeCall(), cudaCheckError() Device memory management: cudaMalloc(), cudaFree(), cudaMemcpy()
Hello, Cuda! CUDA: Basic example HelloCuda2.cu To build the program, use nvcc compiler: scc-he1: % nvcc -o helloCuda2 helloCuda2.cu –arch sm_20 The ability to print from within the kernel was added in a later generation of architectural evolution. To request the support of Compute Capability 2.0, we need to add this option into compilation command line.
Hello, Cuda! CUDA: Basic example HelloCudaBlock.cu #include <stdio.h> __global__ voidcudakernel(void){ printf("Hello, I am CUDA block %d !\n", blockIdx.x); } int main(void){ . . . cudakernel<<<16,1>>>(); . . . } To simplify compilation process we will use Makefile: % make HelloCudaBlock
CUDA: C Language Extensions CUDA provides special variable for thread identification in the kernal: dim3threadIdx; // thread ID within the block dim3blockIdx; // block ID within the grid dim3blockDim; // number of threads per block dim3gridDim; // number of blocks in the grid In the simple 1-dimentional case, we use only the first component of each variable, e.g. threadIdx.x
CUDA: Blocks and Threads Host Serial Code Device Device Kernel A Host Serial Code Kernel B
CUDA: C Language Extensions CUDA: Basic example HelloCudaThread.cu #include <stdio.h> __global__ voidcudakernel(void){ printf("Hello, I am CUDA thread %d !\n", threadIdx.x); } int main(void){ . . . cudakernel<<<1,16>>>(); . . . }
CUDA: Blocks and Threads • One kernel is executed on the device at a time • Many threads execute each kernel • Each thread execute the same code (SPMD) • Threads are grouped into thread blocks • Kernel is a grid of thread blocks • Threads are scheduled as sets of warps • Warp is a group of 32 threads • SM executes same instruction on all threads in the warp • Blocks cannot synchronize and can run in any order
Vector Addition Example CUDA: vectorAdd.cu __global__ voidvectorAdd(const float *A, constfloat *B, float*C, intnumElements){ inti = blockDim.x * blockIdx.x + threadIdx.x; if (i < numElements) { C[i] = A[i] + B[i]; } }
Vector Addition Example CUDA: vectorAdd.cu threadIdx.x threadIdx.x threadIdx.x threadIdx.x 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 blockIdx.x = 0 blockIdx.x = 1 blockIdx.x = 2 blockIdx.x = 3 inti = blockDim.x * blockIdx.x + threadIdx.x; Unlike blocks, threads have mechanisms to communicate and synchronize
Vector Addition Example CUDA: vectorAdd.cu device memory allocation intmain(void) { . . . float*d_A = NULL; err = cudaMalloc((void**)&d_A, size); float*d_B= NULL; err = cudaMalloc((void**)&d_B, size); float*d_C= NULL; err = cudaMalloc((void**)&d_C, size); . . . }
Vector Addition Example CUDA: vectorAdd.cu intmain(void) { . . . // Copy input values to the device cudaMemcpy(d_A, &A, size, cudaMemcpyHostToDevice); cudaMemcpy(d_A, &A, size, cudaMemcpyHostToDevice); . . . }
Vector Addition Example CUDA: vectorAdd.cu intmain(void) { . . . // Launch the Vector Add CUDA Kernel intthreadsPerBlock = 256; intblocksPerGrid =(numElements + threadsPerBlock - 1) / threadsPerBlock; vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N); err = cudaGetLastError(); . . . }
Vector Addition Example CUDA: vectorAdd.cu intmain(void) { . . . // Copy result back to host cudaMemcpy(&C, d_C, size, cudaMemcpyDeviceToHost); // Clean-up cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); . . . }
Timing CUDA kernel CUDA: vectorAddTime.cu float memsettime; cudaEvent_tstart, stop; // initialize CUDA timer cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start,0); // CUDA Kernel . . . // stop CUDA timer cudaEventRecord(stop,0); cudaEventSynchronize(stop); cudaEventElapsedTime(&memsettime,start,stop); printf(" *** CUDA execution time: %f *** \n", memsettime); cudaEventDestroy(start); cudaEventDestroy(stop);
Timing CUDA kernel CUDA: vectorAddTime.cu scc-ha1 %make // specify the number of threads per block scc-ha1 % vectorAddTime128 • Explore the CUDA kernel execution time based on the block size: • Remember: • CUDA Streaming Multiprocessor executes threads in warps (32 threads) • There is a maximum of 1024 threads per block (for our GPU) • There is a maximum of 1536 threads per multiprocessor (for our GPU)
Dot Product CUDA: dotProd1.cu a3 a1 a2 a0 b1 C b3 b2 b0 * * + * * C = A * B = ( a0, a1, a2, a3) * ( b0, b1, b2, b3 ) = a0* b0 +a1* b1 + a2* b2 +a3* b3
Dot Product CUDA: dotProd1.cu A block of threads shares common memory, called shared memory Shared Memory is extremely fast on-chip memory To declare shared memory use __shared__ keyword Shared Memory is not visible to the threads in other blocks
Dot Product CUDA: dotProd1.cu #define N 512 __global__ voiddot( int*a, int*b, int*c ) { // Shared memory for results of multiplication __shared__ inttemp[N]; temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x]; // Thread 0 sums the pairwise products if( threadIdx.x == 0 ) { int sum = 0; for( inti= 0; i< N; i++ ) sum += temp[i]; *c = sum; } } What if thread 0 starts to calculate sum before other threads completed their calculations?
Thread Synchronization CUDA: dotProd1.cu #define N 512 __global__ voiddot( int*a, int*b, int*c ) { // Shared memory for results of multiplication __shared__ inttemp[N]; temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x]; __syncthreads(); // Thread 0 sums the pairwise products if( threadIdx.x == 0 ) { int sum = 0; for( inti= 0; i< N; i++ ) sum += temp[i]; *c = sum; } }
Thread Synchronization CUDA: dotProd1.cu intmain(void) { . . . // copy input vectors to the device . . . // Launch CUDA kernel dotProductKernel<<<1, N >>> (dev_A, dev_B, dev_C); . . . // copy input vectors from the device . . . } But our vector is limited to the maximum block size. Can we use blocks?
Race Condition CUDA: dotProd2.cu Block 0 b3 sum sum b6 b5 b2 a3 b1 a0 a2 a1 a5 a6 a7 b7 a4 b4 b0 * * * * + + C * * * * Block 1
Race Condition CUDA: dotProd2.cu #define N (2048*2048) #define THREADS_PER_BLOCK 512 __global__ void dotProductKernel( int*a, int*b, int*c ) { __shared__ int temp[THREADS_PER_BLOCK]; intindex = threadIdx.x + blockIdx.x * blockDim.x; temp[threadIdx.x] = a[index] * b[index]; __syncthreads(); if( threadIdx.x == 0) { intsum = 0; for( inti= 0; i< THREADS_PER_BLOCK; i++ )sum += temp[i]; *c += sum; } } Blocks interfere with each other – Race condition
Race Condition CUDA: dotProd2.cu #define N (2048*2048) #define THREADS_PER_BLOCK 512 __global__ void dotProductKernel( int*a, int*b, int*c ) { __shared__ int temp[THREADS_PER_BLOCK]; intindex = threadIdx.x + blockIdx.x * blockDim.x; temp[threadIdx.x] = a[index] * b[index]; __syncthreads(); if( threadIdx.x == 0) { intsum = 0; for( inti= 0; i< THREADS_PER_BLOCK; i++ )sum += temp[i]; atomicAdd(c,sum); } }
Atomic Operations Race conditions - behavior depends upon relative timing of multiple event sequences. Can occur when an implied read-modify-write is interruptible Read-Modify-Write uninterruptible – atomic atomicAdd() atomicInc() atomicSub() atomicDec() atomicMin() atomicExch() atomicMax() atomicCAS()
CUDA Best Practices NVIDIA’s link: http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html Locate part of the slowest part of the code gcc -O2 -g -pgmyprog.c gprof ./a.out > profile.txt Compare the outcome with the original expectations. Use CUDA to parallelize code; Use optimize cu* libraries if possible; Overlapping data transfers, fine-tuning operation sequences
CUDA Debugging CUDA-GDB - GNU Debugger that runs on Linux and Mac: http://developer.nvidia.com/cuda-gdb The NVIDIA Parallel Nsightdebugging and profiling tool for Microsoft Windows Vista and Windows 7 is available as a free plugin for Microsoft Visual Studio: http://developer.nvidia.com/nvidia-parallel-nsight
This tutorial has been made possible by Scientific Computing and Visualization group at Boston University. Katia Oleinikkoleinik@bu.edu http://www.bu.edu/tech/research/training/tutorials/list/