Download

1 / 17
170 likes | 321 Views
Delta-MSE D issimilarity in Suboptimal K-Means Clusterin g. Mantao Xu and Pasi Fränti. UNIVERSITY OF JOENSUU DEPARTMENT OF COMPUTER SCIENCE JOENSUU, FINLAND. Int. Conf. on Pattern Recognition Cambridge, UK, August 2004. Problem Formulation.

E N D
Delta-MSE Dissimilarity inSuboptimal K-Means Clustering Mantao Xu and Pasi Fränti UNIVERSITY OF JOENSUU DEPARTMENT OF COMPUTER SCIENCE JOENSUU, FINLAND Int. Conf. on Pattern Recognition Cambridge, UK, August 2004
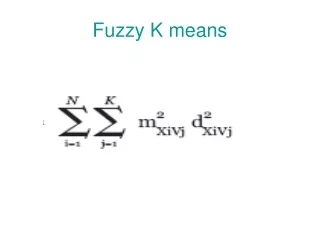
Problem Formulation Given N data samplesX={x1, x2, …, xN}, construct the codebook C ={c1, c2, …, cM} such that mean-square-error is minimized. The class membership p (i) is
Traditional K-Means Algorithm • Iterations of two steps: • assignment of each data vector with class membership • computing cluster centroid • Characteristics: • Randomized initial partition or codebook • Convergence to a local minimum • Use of L2, L1 and L distance • Fast and easy implementation • Extensions: • Kernel K-Means algorithm • EM algorithm • K-Median algorithm
Motivation Investigation on a clustering algorithm that: • Estimate the initial partition close to optimal solution in each principal component direction • Choose the best solution with minimum F-ratio amongst the K-Means clusterings obtained from all principal components • Apply a heuristic dissimilarity that is derived by moving a given vector from one cluster to another
Selecting K-Means initial partiton Selection of initial partionbased on PCA and the dynamic programming technique: • The d number of suboptimal partition is estimated by dynamic programming in done-dimensional subspaces respectively. • The d number of subspaces are constructed through principal component analysis • The final solution is chosen amongst the d number of K-Means clusterings obtained in the d number of pricinpal components
Principal component analysis The principal component analysis can be written as solving the eigenvalue problem of the covariance matrix for a training set. The covariance matrix of the given training set is The d number of one-dimensional subspaces can be extracted by project all data smaples into the d possible number of eigenvectors yj, j = 1,,d
Dynamic programming in principal component direction The optimal convex partition Qk={(qj-1,qj]| j=1,,n} in each principal direction w can be estimated by dynamic programming in terms of MSE distortion on the principal component subspace: (1) or in terms of MSE distortion on original feature space: (2)
,G )=AddVariance Delta-MSE(x 4 2 x 2 y 1 G G y x x 2 1 4 1 2 y 3 x 3 Delta-MSE(x ,G )=RemovalVariance 4 1 Application of Delta-MSE Dissimilarity Move vector x fromcluster ito cluster j, the change of the MSE function [10] caused by this move is:
Three K-Means algorithms conducted in experimental tests • K-D tree based K-Means: selects its initial cluster centroids from the k-bucket centers of a kd-tree structure that is recursively built by principal component analysis • Opt-L2: the suboptimal K-Means algorithm to estimate a suboptimal initial partition by dynamic programming in the principal component direction, in which L2 distance is used for clustering parititions • Opt-DMSE : the suboptimal K-Means algorithm to estimate a suboptimal initial partition by dynamic programming in the principal component direction, in which Delta-MSE dissimilarity is used for clustering parititions
Datasets k Method F - ratio C - rate Opt - L 1.2387 59.44% 2 Opt - DMSE auto - mpg 5 1.2346 60.97% KTree - L 1.3200 51.74% 2 Opt - L 3.5161 17.39% 2 Opt - DMSE Boston 9 3.5104 21.74% KTree - L 4.0827 13.79% 2 Opt - L 10.266 69.40% 2 Opt - DMSE Di abetes 2 10.089 69.60% KTree - L 10.087 60.12% 2 Comparison of the three K-Means clustering algorithms Performance comparisons (in F-ratio validity indices and classification rate ) of the three K-Means algorithms on the practical numbers of clusters
Conclusions The suboptimal K-Means algorithm with use of the Delta-MSE dissimilarity provides a simple approach to the problem of local optimality appearing in the K-Means clustering, It outperforms algorithm that uses L2 distance and the comparative kd-tree based clustering algorithm, The classification performance gains of the proposed approach over the two others increases with the number of clusters.
Further Work • Solving the k-center clustering problem by iteratively incorporating the multi-class Fisher discriminant analysis and the dynamic programming technique, • Solving the k-center clustering problem by incorporating the kernel PCA technique and the dynamic programming technique, • Solving the k-center clustering problem by incorporating the ICA technique and the dynamic programming technique.