Download

1 / 14
140 likes | 154 Views
Investigate the impact of morpheme extraction on IR for Bengali and Hindi. Implement rule-based stemming approaches. Compare performance for optimal results. Future work includes exploring exclusions lists and improving rule sets.

E N D
Debasis Ganguly, Johannes Leveling, Gareth J.F. Jones CNGL, School of Computing, Dublin City University, Ireland DCU meets MET: Bengali and Hindi Morpheme Extraction
Outline Motivation Task Description Bengali Stemming Approach Hindi Stemming Approach Results Conclusions and Future Work
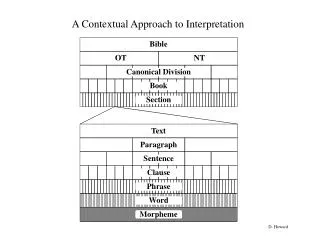
Motivation • Some languages have complex inflectional and derivational morphology, i.e. the same base form can correspond to multiple surface word forms • Example: • company, companies → company; • hopeful → hope • For information retrieval, indexing surface forms would lead to many mismatches between query terms and index terms extracted from documents • Index base forms/stems: Reduce different surface forms to the same index form (stem, lemma) to increase the chance of matching query term with document terms
Task Description Morpheme Extraction Task: Investigate effect of morphologic analysis/ lemmatization/ stemming on information retrieval (IR) performance (for Indian languages) Subtasks: Subtask 1: manual evaluation of morpheme extraction Subtask 2: IR evaluation using the proposed morpheme representation as index terms. Evaluation metric is mean average precision (MAP)
Stemming Approaches Light vs aggressive stemming Rule-based vs. corpus-based stemming manually created vs. cluster of related words iteratively remove word suffixes problem: overstemming, i.e. removed suffix is too long e.g. international/intern; news/new understemming, i.e. removed suffix is too short e.g. forgetfulness/forgetful irregular forms e.g. feet/foot; women/woman
Our Bengali Stemming Approach Rule-based stemmer created by native speaker Focus on nouns (most important for IR) Four categories [Bhattacharya et al. 2005]: Title markers added as suffixes to proper nouns e.g. “দেবী” (Mrs.), “বাবু”(sir) Classifier forplurality and specificity/gender of a noun e.g. ছবিগুলো (Pictures), ছবিটা (the Picture), ছাত্রী (female student) Case marker for possessive or accusative relations e.g. পরিবারের (family’s) Emphasizer to emphasize the current word e.g. ছবিই (only a picture), ছবিটাই (only this picture)
Bengali Stemmer Drop emphasizers (iteratively) e.g. আধিক্যই আধিক্য Drop classifiers and case markers e.g. মন্ত্রীরাও মন্ত্রী, ভারতের ভারত Drop title markers e.g. মমতাদেবী মমতা Drop plural suffixes e.g. ভারতীয়দের ভারতীয় Drop derivational suffixes e.g. স্থিতীশীল স্থিতী
Our Hindi Stemming Approach Hindi has less complex inflectional morphology fewer stemming rules Rule-based stemmer Stemming rules manually created by native Hindi speaker
Hindi Stemmer Iteratively remove Hindi vowels, Matras, Anusvara, and “य” (character ya) from the right of a string until first consonant is encountered Drop derivational suffixes, e.g. लड़कों (to boys)लड़का (boy) लड़कियों (to girls) लड़की (girl)
MET Experiments Experiments for Bengali and Hindi Stemmers implemented in C Submission as source code Stemmed forms are used for retrieval with Terrier
Conclusions Bengali stemmer: 2nd best performance Hindi stemmer: Best performance Both have also been used successfully in previous ad-hoc IR experiments for FIRE
Future work Explore use of exclusion lists for irregular cases Extend rule set (i.e. handle verbs) Compare to other stemmers for Bengali/Hindi e.g. Indian language in version 4 of Lucene; stemmers from Jacques Savoy’s web page on cross-language IR Investigate morphology of named entities
Thank+s for your attention Anyquestion+s ?