Download

1 / 25
250 likes | 272 Views
Learn the steps involved in normalizing microarray data, including background correction, within-slide normalization, and identifying differentially expressed genes. Explore methods like global normalization and print-tip normalization to ensure accurate analysis.

E N D
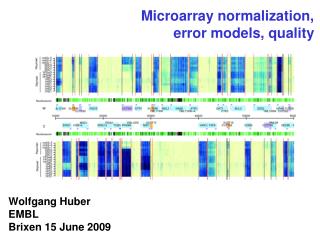
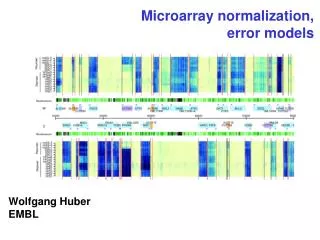
Normalization of Microarray Data Henrik Bengtsson (hb@maths.lth.se) Terry Speed (terry@stat.berkeley.edu) - how to do it!
Outline • The X Data Set • (R,G) (M,A) Transformation • Background correction or not? • Within slide normalization • Across slide normalization • Identifying differentially expressed genes • The X2 Data Set
The X Data Set • All slides are replicates and contains 5184 spots/genes. Three identical RNA preparations were done; (a) was hybridized to slide 1-3, (b) to slide 4-6, and (c) to slide 7-9. • All data is collected by GenePixTM Scanner and Software. The following analysis was done using [R] and the sma library by Terry Speed Group.
(R,G) (M,A) Transformation “Observed” data {(R,G)}n=1..5184: R = red channel signal G = green channel signal (background corrected or not) Transformed data {(M,A)}n=1..5184: M = log2(R/G) (ratio), A = log2(R·G)1/2 = 1/2·log2(R·G) (intensity) R=(22A+M)1/2, G=(22A-M)1/2
Background correction or not? Decision 1: No background correction
Within Slide Normalization Question: What kind of normalization should be applied: • No normalization, or • Global (lowess) normalization, or • Print-tip normalization, or • Scaled print-tip normalization?
No Normalization Non-normalized data {(M,A)}n=1..5184: M = log2(R/G)
Global (lowess) Normalization Global normalized data {(M,A)}n=1..5184: Mnorm = M-c(A) where c(A) is an intensity dependent function.
Print-tip Normalization Print-tip normalized data {(M,A)}n=1..5184: Mp,norm = Mp-cp(A); p=print tip (1-16) where cp(A) is an intensity dependent function for print tip p. Print-tip layout
Scaled Print-tip Normalization Scaled print-tip normalized data {(M,A)}n=1..5184: Mp,norm = sp·(Mp-cp(A)); p=print tip (1-16) where sp is a scale factor for print tip p (Median Absolute Deviation). After print-tip normalization After scaled print-tip normalization
Spatial Effects No normalization Global normalization Scaled Print-tip normalization Print-tip normalization
Another Quick Example Scaled print-tip normalization:
Within Slide Normalization Summary Question: What kind of normalization should be applied: • No normalization, or • Global (lowess) normalization, or • Print-tip normalization, or • Scaled print-tip normalization? Decision 2: Scaled print-tip normalization.
Across Slides Normalization Scaled print-tip normalization Median Absolute Deviation (MAD) Scaling Averaging
Average Over All Slides The “average” slide:
Cutoff by M values Top 5% of the absolute M values (|M| > 0.56):
Cutoff by T values Top 5% of the absolute T values (|T|>8.6) s.t. SE(M) > 0.03:
SE Cutoff Level In this data set, the number of genes found is insensitive to the SE cutoff level. About 1000 of the genes with smallest SE can be cutoff before it affects the final results.
103 Differentially Expressed Genes Top 5% of the absolute T values (|T|>8.6) s.t. SE(M) > 0.03, and top 5% of the absolute M values (|M|>0.56):
Location of Differentially Expressed Genes Location of the 4x4 grid sized microarray
25 Differentially Expressed Genes Gene: MavgAavgT SE 1 -2.26 9.9 -18.0 0.125 2 -1.97 10.3 -14.5 0.136 3 -1.50 9.6 -14.7 0.102 4 -1.47 9.8 -12.2 0.121 5 -1.40 9.3 -11.9 0.118 6 -1.30 9.9 -14.4 0.090 7 -1.29 9.7 -14.6 0.088 8 -1.28 10.0 -12.7 0.101 9 -1.27 9.2 -13.6 0.094 10 -1.19 10.7 -13.7 0.087 11 -1.18 9.8 -11.4 0.103 12 -1.17 9.9 -20.7 0.057 13 1.12 11.3 13.5 0.083 14 -1.07 11.4 -13.3 0.080 15 -1.05 9.6 -12.8 0.081 16 -1.02 9.9 -12.0 0.085 17 -1.01 9.3 -11.8 0.086 18 -0.99 11.0 -13.6 0.073 19 -0.99 9.8 -11.4 0.087 20 -0.97 10.5 -13.8 0.070 21 -0.96 9.6 -12.5 0.077 22 0.95 11.5 11.6 0.082 23 -0.94 10.3 -25.0 0.038 24 -0.93 9.8 -13.5 0.068 25 -0.90 11.6 -12.0 0.075 Top 2% of the absolute T values (|T|>11) s.t. SE(M) > 0.03 and top 2% of the absolute M values (|M|>0.9):
The X2 Data Set All slides are replicates and contains 5184 spots/genes. Three identical RNA preparations were done; (a) was hybridized to slide 1 & 2, (b) to slide 3 & 4, and (c) to slide 5 & 6.
93 Differentially Expressed Genes Top 5% of the absolute T values (|T|>5.6) s.t. SE(M) > 0.03) and top 5% of the absolute M values (|M|>0.38):
25 Differentially Expressed Genes Gene: MavgAavgT SE 1 1.97 12.5 8.3 0.237 2 1.27 9.7 18.2 0.070 3 1.23 13.2 7.5 0.164 4 1.12 12.3 19.2 0.058 5 0.93 14.2 7.7 0.122 6 0.86 13.7 10.2 0.085 7 -0.86 12.5 -8.1 0.106 8 -0.85 13.0 -17.0 0.050 9 -0.81 12.7 -16.3 0.050 10 -0.75 11.1 -8.6 0.088 11 -0.72 11.4 -11.4 0.063 12 -0.71 13.9 -15.6 0.045 13 0.66 10.0 9.4 0.071 14 0.66 10.8 9.2 0.072 15 -0.64 12.5 -15.2 0.042 16 0.64 9.6 7.9 0.081 17 -0.61 12.5 -7.5 0.081 18 -0.60 12.8 -18.2 0.033 19 0.59 11.4 8.3 0.071 20 -0.59 13.7 -8.3 0.071 21 -0.58 10.5 -7.2 0.081 22 -0.56 12.0 -12.5 0.045 23 0.55 11.7 9.1 0.061 24 -0.54 12.6 -7.6 0.071 25 0.53 11.2 9.5 0.056 Top 2% of the absolute T values (|T|>7.1) s.t. SE(M) > 0.03 and top 2% of the absolute M values (|M|>0.53):
Acknowledgement • Thanks to: • Jean Yee Hwa Yang • [R] Software (free): • http://www.r-project.org/ • The Statistical Microarray Analysis (sma) library (free): • http://www.stat.berkeley.edu/users/terry/zarray/Software/smacode.html