Download

1 / 29
300 likes | 553 Views
Data Mining : Intelligent Data Analysis for Knowledge Discovery Yike Guo Dept. of Computing Imperial College. Goal Basic Concepts of Data Mining Data Mining Techniques Data Mining Applications Future Research Trends on Data Mining Reference Books

E N D
Data Mining : Intelligent Data Analysis for Knowledge Discovery Yike GuoDept. of ComputingImperial College
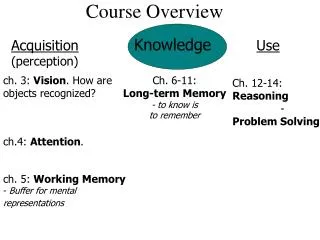
Goal Basic Concepts of Data Mining Data Mining Techniques Data Mining Applications Future Research Trends on Data Mining Reference Books Advances in Knowledge Discovery and Data Mining U.M Fayyad and G, Piatetsky-Shapiro AAAI/MIT Press. 1996 Predictive Data Mining: A Practical Guide Sholom M.Weiss and Nitin Indurkhya Morgan Kaufmann Publishers, Inc. 1997 Intelligent Data Analysis, Springer 1999 Post-genome Informaticsby Minoru Kanehisa, Oxford University Press, 2000 Course Overview
What does the data say? Day Outlook Temperature Humidity Wind Play Tennis 1 Sunny Hot High Weak No 2 Sunny Hot High Strong No 3 Overcast Hot High Weak Yes 4 Rain Mild High Weak Yes 5 Rain Cool Normal Weak Yes 6 Rain Cool Normal Strong No 7 Overcast Cool Normal Strong Yes 8 Sunny Mild High Weak No 9 Sunny Cool Normal Weak Yes 10 Rain Mild Normal Weak Yes 11 Sunny Mild Normal Strong Yes 12 Overcast Mild High Strong Yes 13 Overcast Hot Normal Weak Yes 14 Rain Mild High Strong No
Limitation of traditional database querying: Most queries of interest to data owners are difficult to state in a query language “ find me all records indicating fraud”=> “ tell me the characteristics of fraud” (Summarisation) “find me who likely to buy product X” (classification problem) “find all records that are similar to records in table X” (clustering problem) Ability to support analysis and decision making using traditional (SQL) queries become infeasible (query formulation problem ). Why Data Mining
Terabyte databases, consisting of billions of records, are becoming common Relational data model is the defacto standard A relational database : set of relations A relation : a set of homogenous tuples Relations are created, updated and queried using SQL Query = Keyword based search SELECT telephone_number FROM telephone_book WHERE last_name = “Smith” Relational Database Revisited
Provides a well-defined set of operations: scan, join, insert, delete, sort, aggregate, union, difference Scan -- applies a predicate P to relation R For each tuple tr from R if P(tr) is true, tr is inserted in the output stream Join -- composes two relations R and S For each tuple tr from R For each tuple ts from S if join attribute of tr equals to join attribute of ts form output tuple by concatenating tr and ts SQL : Relational Querying Language
Relational database. A table (relation) is a set and the three basic table operations shown here are extensions of the standard set operations. Volume Journal MUID Pages Year Paper 1 Paper 2 Paper 3 Paper 4 . . . . SELECT PROJECT Volume Journal MUID Author Pages Year JOIN Author MUID Author 1-1 Author 1-2 Author 2-1 Author 2-2 Author 2-3 Author 3-1 . . . .
It is not solvable via query optimisation Has not received much attention in the database field or in traditional statistical approaches These problems are of inductive features: learning from data rather than search from data Natural solution is via train-by-example approach to construct inductive models as the answers The Query Formulation Problem Consider the query : What kinds of weather condition are suitable for playing tennis ?
Why Data Mining Now • Data Explosion • Business Data :organisations such as supermarket chains, credit card companies, investment banks, government agencies, etc. routinely generate daily volumes of 100MB of data • Scientific Data: Scientific and remote sensing instruments collect data at the rates of Gigabytes per day: far beyond human analysis abilities. • Data Wasting • Only a small portion (5% - 10%) of the collected data is ever analysed • Data that may never be analysed continues to be collected, at great expense. • We are drowning in data, but starving for knowledge!
What is Data Mining Data Mining: a non-trivial intelligent data analysis process for identifying valid, useful and understandable patterns from databases.
Data: set of facts F ( records in a database) Pattern : An expression E in a language L describing data in a subset FE of F and E is simpler than the enumeration of al l the facts of FE. FE is also called a class and E is also called a model or knowledge. Data Mining Process: data mining is a multi-step process involving multiple choices, iteration and evaluation. It is non-trivial since there is no closed-form solution. It always involve intensive search. Validity : E is true (with high probability) for F Useful : patterns are not trivial inductive properties of data Understandable: patterns should be understandable by data owners to aid in understanding the data/domain
Data Mining and Decision Support Data Warehousing: create/ select target database Sampling: choose data for building models Data Cleaning: supply missing values eliminate noisy data Data Mining: choose data mining tasks choose data mining methods to extract patterns / knowledge Data Reduction and Projection: derive useful features dimensionality reduction Model Test and Evaluation: test the accuracy of the model consistency check model refinement Machine Learning Technologies Decision Support
DataWarehousing • “ A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decision-making process.” --- W. H. Inmon • A data warehouse is • A decision support database that is maintained separately from the organization’s operational databases. • It integrates data from multiple heterogeneous sources to support the continuing need for structured and /or ad-hoc queries, analytical reporting, and decision support.
Modeling Data Warehouses • Modeling data warehouses: dimensions & measurements • Star schema: A single object (fact table) in the middle connected to a number of objects (dimension tables) radically. • Snowflake schema: A refinement of star schema where the dimensional hierarchy is represented explicitly by normalizing the dimension tables. • Fact constellations: Multiple fact tables share dimension tables. • Storage of selected summary tables: • Independent summary table storing pre-aggregated data, e.g., total sales by product by year. • Encoding aggregated tuples in the same fact table and the same dimension tables.
Time Dimension Table Sales Fact Table Product Dimension Table Many Time Attributes Time_Key Many Product Attributes Product_Key Store Dimension Table Location Dimension Table Store_Key Many Location Attributes Many Store Attributes Location_Key unit_sales dollar_sales Measures Yen_sales Example of Star Schema
Customer Orders Shipping Method Customer CONTRACTS AIR-EXPRESS ORDER TRUCK PRODUCT LINE Time Product ANNUALY QTRLY DAILY PRODUCT ITEM PRODUCT GROUP DISTRICT SALES PERSON REGION DISTRICT COUNTRY DIVISION Geography Promotion Organization A Star-Net Query Model
OLAP: On-Line Analytical Processing • A multidimensional, LOGICAL view of the data. • Interactive analysis of the data: drill, pivot, slice_dice, filter. • Summarization and aggregations at every dimension intersection. • Retrieval and display of data in 2-D or 3-D crosstabs, charts, and graphs, with easy pivoting of the axes. • Analytical modeling: deriving ratios, variance, etc. and involving measurements or numerical data across many dimensions. • Forecasting, trend analysis, and statistical analysis. • Requirement: Quick response to OLAP queries.
OLAP Architecture • Logical architecture: • OLAP view: multidimensional and logic presentation of the data in the data warehouse/mart to the business user. • Data store technology: The technology options of how and where the data is stored. • Three services components: • data store services • OLAP services, and • user presentation services. • Two data store architectures: • Multidimensional data store: (MOLAP). • Relational data store: Relational OLAP (ROLAP).
All, All, All Construction of Data Cubes All Amount Comp_Method, B.C. Amount 0-20K 20-40K 40-60K 60K- sum Province B.C. Prairies Comp_Method Ontario sum Database Discipline … ... sum Each dimension contains a hierarchy of values for one attribute A cube cell stores aggregate values, e.g., count, sum, max, etc. A “sum” cell stores dimension summation values. Sparse-cube technology and MOLAP/ROLAP integration. “Chunk”-based multi-way aggregation and single-pass computation.
Ad Hoc Queries: Q: How many customers do we have in London? A: 32776 Decision Support with Data Warehouse
OLAP: Q:What are the sales figures for Y in the different regions:
Statistics: Q: Is there a relation between age and buy behaviour? A: Older clients buy more
Data Mining: Q: What factors influence buying behaviour ? Age Old Young Middle Hair color Wage N L H B W Y Y N N • A1: : Young men in sports cars buy 3 times as much audio equipment (clustering/regression): • A2: Older woman with dark hair more often buy rinse (classification) • A3: Buyers of cars are also the buyers of houses (asociation)
Commercial : Fraud detection: Identify Fraudulent transaction Loan approval: Establish the credit worthiness of a customer requesting a loan Investment analysis : Predict a portfolio's return on investment Marketing and sales data analysis: Identify potential customers; establishing the effectiveness of a sales campaign Medical: Drug effect analysis : from patient records to learn drug effects Disease causality analysis Political policy: Election policy : people’s voting patterns Social policy: tax/benefit policy Manufacturing: Manufacturing process analysis: identify the causes of manufacturing problems Experiment result analysis : Summarise experiment results and create predictive models Example Data Mining Applications
Related Fields: • Machine learning: Inductive reasoning • Statistics : Sampling, Statistical Inference, Error Estimation • Pattern recognition: Neural Networks, Clustering • Knowledge Acquisition, Statistical Expert Systems • Data Visualisation • Databases: OLAP, Parallel DBMS, Deductive Databases • Data Warehousing: collection, cleaning of transactional data for on-line retrial