Download

1 / 34
340 likes | 482 Views
The performance Improving of Microprocessor World. By Ming-Haw Jing The current status of microprocessors The instructions set architecture The concept of pipelining The structure of pipelining The problems solving of pipelining The computer system architecture The metrics of the computer.

E N D
The performance Improving of Microprocessor World By Ming-Haw Jing The current status of microprocessors The instructions set architecture The concept of pipelining The structure of pipelining The problems solving of pipelining The computer system architecture The metrics of the computer
Original Big Fishes Eating Little Fishes
Mainframe Work- station PC Mini- computer Mini- supercomputer Supercomputer Massively Parallel Processors 1988 Computer Food Chain
Technology Trends(Summary) Capacity Speed (latency) Logic 2x in 3 years2x in 3 years DRAM 4x in 3 years 2x in 10 years Disk 4x in 3 years 2x in 10 years
Performance and Technology Trends 1000 100 10 Performance 1 0.1 1965 1970 1975 1980 1985 1990 1995 2000 Year Supercomputers Mainframes Minicomputers Microprocessors
Mainframe Work- station PC Server Supercomputer 1998 Computer Food Chain Mini- supercomputer Mini- computer Massively Parallel Processors Now who is eating whom?
software instruction set hardware Instruction Set Architecture (ISA)
Application Programming Language Compiler ISA Datapath Control Function Units Transistors Wires Pins Where Is The Instruction Set? Answers per month Operations per second (millions) of Instructions per second: MIPS (millions) of (FP) operations per second: MFLOP/s Megabytes per second Cycles per second (clock rate)
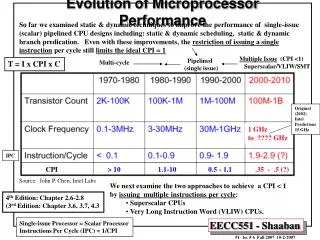
Evolution of Instruction Sets Single Accumulator (EDSAC 1950) Accumulator + Index Registers (Manchester Mark I, IBM 700 series 1953) Separation of Programming Model from Implementation High-level Language Based Concept of a Family (B5000 1963) (IBM 360 1964) General Purpose Register Machines Complex Instruction Sets Load/Store Architecture (CDC 6600, Cray 1 1963-76) (Vax, Intel 432 1977-80) RISC (Mips,Sparc,HP-PA,IBM RS6000,PowerPC . . .1987) VLIW/PIC (IA-64. . .1999)
Instruction Format of MIPS Register-Register 6 5 11 10 31 26 25 21 20 16 15 0 Op Rs1 Rs2 Rd Opx Register-Immediate 31 26 25 21 20 16 15 0 immediate Op Rs1 Rd Branch 31 26 25 21 20 16 15 0 immediate Op Rs1 Rs2/Opx Jump / Call 31 26 25 0 target Op
A B C D Pipelining is Natural! • Laundry Example • Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold • Washer takes 30 minutes • Dryer takes 30 minutes • Folder takes 30 minutes • Dasher takes 30 minutesto put clothes into drawers
A B C D Sequential Laundry 2 AM 12 6 PM 1 8 7 11 10 9 • Sequential laundry takes 8 hours for 4 loads • If they learned pipelining, how long would laundry take? 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 T a s k O r d e r Time
2 AM 12 6 PM 1 8 7 11 10 9 Time 30 30 30 30 30 30 30 T a s k O r d e r A B C D Pipelined Laundry: Start work ASAP • Pipelined laundry takes 3.5 hours for 4 loads!
Pipelined Datapath of CPU Instruction Fetch Instr. Decode Reg. Fetch Execute Addr. Calc. Write Back Memory Access
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Load Ifetch Reg/Dec Exec Mem Wr The FiveStages of Load • Ifetch: Instruction Fetch • Fetch the instruction from the Instruction Memory • Reg/Dec: Registers Fetch and Instruction Decode • Exec: Calculate the memory address • Mem: Read the data from the Data Memory • Wr: Write the data back to the register file
Visualizing Pipelining I n s t r. O r d e r
Time IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB Program Flow IFetch Dcd Exec Mem WB Pipelined Execution Representation
Time (clock cycles) I n s t r. O r d e r ALU Im Dm Reg Reg Inst 0 ALU Inst 1 Dm Reg Im Reg Inst 2 ALU Im Dm Reg Reg Inst 3 ALU Im Dm Reg Reg Inst 4 ALU Dm Reg Im Reg Why Pipeline?
Time (clock cycles) IF ID/RF EX MEM WB I n s t r. O r d e r add r1, r2, r3 sub r4, r1, r3 and r6, r1, r7 or r8, r1, r9 xor r10, r1, r11 Data Hazard on R1
Time (clock cycles) ALU Mem Mem Reg Reg ALU Mem Mem Reg Reg ALU Mem Reg Reg Mem Control Hazard Solutions • Stall: wait until decision is clear for branch instruction I n s t r. O r d e r Add Beq Load
Time (clock cycles) IF ID/RF EX MEM WB ALU add r1,r2,r3 Reg Reg Im Dm ALU sub r4,r1,r3 Dm Reg Im Reg ALU Im Dm Reg Reg and r6,r1,r7 ALU Im Dm Reg Reg or r8,r1,r9 ALU Dm Reg Im Reg xor r10,r1,r11 Data Hazard on r1: I n s t r. O r d e r
Time (clock cycles) IF ID/RF EX MEM WB ALU add r1,r2,r3 Reg Reg Im Dm ALU sub r4,r1,r3 Dm Reg Im Reg ALU Dm Reg Im Reg and r6,r1,r7 ALU Im Dm Reg Reg or r8,r1,r9 ALU Dm Reg Im Reg xor r10,r1,r11 Data Hazard Solution: I n s t r. O r d e r
I-Fet ch DCD MemOpFetch OpFetch Exec Store IFetch DCD ?? Structural Hazard I-Fet ch DCD OpFetch Jump Control Hazard IFetch DCD ?? IF DCD EX Mem WB RAW (read after write) Data Hazard IF DCD EX Mem WB WAW Data Hazard (write after write) IF DCD EX Mem WB IF DCD OF Ex Mem IF DCD OF Ex RS WAR Data Hazard (write after read) Pipeline Hazards
Loop Unrolling in Superscalar Loop: LD F0,0(R1) 1 LD F6,-8(R1) 2 LD F10,-16(R1) ADDD F4,F0,F2 3 LD F14,-24(R1) ADDD F8,F6,F2 4 LD F18,-32(R1) ADDD F12,F10,F2 5 SD 0(R1),F4 ADDD F16,F14,F2 6 SD -8(R1),F8 ADDD F20,F18,F2 7 SD -16(R1),F12 8 SD -24(R1),F16 9 SUBI R1,R1,#40 10 BNEZ R1,LOOP 11 SD -32(R1),F20 12
Loop Unrolling in VLIW Memory Memory FP FP Int. op/ Clockreference 1 reference 2 operation 1 op. 2 branch LD F0,0(R1) LD F6,-8(R1) 1 LD F10,-16(R1) LD F14,-24(R1) 2 LD F18,-32(R1) LD F22,-40(R1) ADDD F4,F0,F2 ADDD F8,F6,F2 3 LD F26,-48(R1) ADDD F12,F10,F2 ADDD F16,F14,F2 4 ADDD F20,F18,F2 ADDD F24,F22,F2 5 SD 0(R1),F4 SD -8(R1),F8 ADDD F28,F26,F2 6 SD -16(R1),F12 SD -24(R1),F16 7 SD -32(R1),F20 SD -40(R1),F24 SUBI R1,R1,#48 8 SD -0(R1),F28 BNEZ R1,LOOP 9
T NT Predict Taken Predict Taken T T NT NT Predict Not Taken Predict Not Taken T NT Dynamic Branch Prediction Solution: 2-bit scheme where change prediction only if get misprediction twice
Branch Prediction: Taken or not Taken Branch Target Buffer (BTB): Address of branch index to get prediction AND branch address (if taken) Predicted PC
Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap (latency) Proc=60%/yr. (2X/1.5yr) 1000 CPU Moore’s Law 100 Processor-Memory Performance Gap:(grows 50% / year) Performance 10 DRAM=9%/yr. (2X/10 yrs) DRAM 1 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 Time
Levels of the Memory Hierarchy Upper Level Capacity Access Time Cost Staging Xfer Unit faster CPU Registers 100s Bytes <10s ns Registers prog./compiler 1-8 bytes Instr. Operands Cache K Bytes 10-100 ns 1-0.1 cents/bit Cache cache cntl 8-128 bytes Blocks Main Memory M Bytes 200ns- 500ns $.0001-.00001 cents /bit Memory OS 512-4K bytes Pages Disk G Bytes, 10 ms (10,000,000 ns) 10 - 10 cents/bit Disk -5 -6 user/operator Mbytes Files Larger Tape infinite sec-min 10 Tape Lower Level -8
31 9 4 0 Cache Tag Example: 0x50 Cache Index Byte Select Ex: 0x01 Ex: 0x00 Stored as part of the cache tate Valid Bit Cache Tag Cache Data Byte 31 Byte 1 Byte 0 0 : 0x50 Byte 63 Byte 33 Byte 32 1 : 2 3 : : : Byte 1023 Byte 992 31 : 1 KB Direct Mapped Cache, 32B blocks
Processor Control Tertiary Storage (Disk/Tape) Secondary Storage (Disk) Second Level Cache (SRAM) Main Memory (DRAM) Datapath On-Chip Cache Registers Speed (ns): 100s 10,000,000s (10s ms) 10,000,000,000s (10s sec) 10s 1s Size (bytes): 100s Ms Ks Gs Ts A Modern Memory Hierarchy
800 700 600 500 SPEC Perf 400 300 200 100 0 gcc li doduc spice fpppp nasa7 eqntott tomcatv epresso matrix300 Benchmark SPEC First Round