Download

1 / 49
490 likes | 663 Views
Stochastic Approximation and Simulated Annealing. Lecture 8. Leonidas Sakalauskas Institute of Mathematics and Informatics Vilnius, Lithuania EURO Working Group on Continuous Optimization. Content. Introduction. Stochastic Approximation : SPSA with Lipschitz perturbation operator;

E N D
Stochastic Approximation and Simulated Annealing Lecture 8 Leonidas Sakalauskas Institute of Mathematics and Informatics Vilnius, Lithuania EURO Working Group on Continuous Optimization
Content • Introduction. • Stochastic Approximation: • SPSA with Lipschitz perturbation operator; • SPSA with Uniform perturbation operator; • Standard Finite Difference Approximation algorithm. • Simulated Annealing • Implementation and Applications • Wrap-Up and Conclusions
Introduction In many practical problems of technical design some of the data may be subject to significant uncertainty which is reduced to probabilistic-statistical models. The performance of such problems can beviewed like constrained stochastic optimization programming tasks. Stochastic Approximation can be considered as alternative to traditional optimization methods, especially when objective functions are no differentiable or computed with noise.
Stochastic Approximation Application of Stochastic Approximation to solving of optimization problems, while the objective function is non-differentiable or nonsmooth and computed with noiseis a topical theoretical and practical problem. The known methods of Stochastic Approximation for solving of these problems use the idea of stochastic gradient and certain rules of changing of step length for ensuring the convergence.
Formulation of the optimization problem The optimization problem is (minimization) as follows: where is a bounded from below Lipshitz function.
Formulation of the optimization problem Let be generalized gradient of this function. Assume to be a set of stationary points: and to be a set of function values:
We consider a functionsmoothed by perturbationoperator: where is the value of the perturbation parameter. The functions smoothed by this operator are twice continuously differentiable (Rubinstein & Shapiro (1993), Bartkute & Sakalauskas (2004)), that offers certain opportunities creating optimization algorithms.
Advantages of SPSA At last time the interesting research was focussed on Stochastic Perturbation Stochastic Approximation (SPSA) It is enoughto calculate values of the function only in one orsome pointsfor the estimation of the stochastic gradient in SPSA algorithms, that promises for us toreduce numericalcomplexity of optimization.
SA algorithms 1. SPSA with Lipschitz perturbation operator. 2. SPSA with Uniformperturbation operator. 3. Standard Finite Difference Approximation algorithm.
GeneralStochasticApproximationscheme where stochastic gradient and This scheme is the same for different Stochastic Approximationalgorithms whose distinguish only by approach for stochastic gradient estimation.
SPSA with Lipschitz perturbation operator Gradient estimator of the SPSA with Lipschitz perturbation operator is expressed as: where -is the value of the perturbation parameter, vector -is uniformly distributed in the unit ball -is the volume of the n-dimensional ball (Bartkute & Sakalauskas (2007))
SPSA with Uniform perturbation operator Gradient estimator of the SPSA with Uniform perturbation operator is expressed as: where -is the value of the perturbation parameter, -is a vector consisting of variables uniformly distributed from the interval [-1;1] (Mikhalevitch et al (1987)).
Standard Finite Difference Approximation algorithm Gradient estimator of the Standard Finite Difference Approximation algorithmis expressed as: where -is the value of the perturbation parameter, vector -is uniformly distributed in the unit ball; -is the vector with zero components except ith one, which is equal to 1. (Mikhalevitch et al (1987)).
Rate of convergence Let consider that the function f(x)has a sharp minimum in the point , in which the algorithm converges when Then where A>0, H>0, K>0 are certain constants, is minimum point of the smoothed function.
Computer simulation The proposed methods were tested with following functions: where is a set of real numbersrandomly and uniformly generated in the interval , The samples of T=500 test functions were generated, when
Empirical and theoretical rates of convergence by SA methods
Volatility estimation by Stochastic Approximation algorithm Let us consider the application of SA to the minimization of the mean absolute pricing error for the parameter calibration in the Heston Stochastic Volatility model[Heston S. L.(1993)]. We consider the mean absolute pricing error (MAE) defined as: where N is the total number of options, and represent the realized market price and the implied the theoretical model price, respectively, while(n=6) are the parameters of the Heston model to be estimated.
To compute option prices by the Heston model, one needs input parameters that can hardly be found from the market data. We need to estimate the above parameters by an appropriate calibration procedure. The estimates of the Heston model parameters are obtained by minimizing MAE: Let considerthe Heston model for the Call option on SPX (29 May 2002).
Minimization of the mean absolute pricing error by SPSA and SFDA methods
Optimal Design of Cargo Oil Tankers In cargo oil tankers design, it is necessary to choose such sizes for bulkheads, that the weight of bulkheads would be minimal.
The minimization of weight of bulkheads for the cargo oil tank we can formulate like nonlinear programing task (Reklaitis et al (1986)): subject to where - lenght, - thikness. - width, -debt,
SPSA with Lipschitz perturbation for the cargo oil target design
Confidence bounds of the minimum (A=6.84241, T=100, N=1000)
Simulated AnnealingGlobal optimization methods • Global algorithms (bounds and branch algorithms, dynamic programming, full selection, etc) • Greedy optimization (local search) • Heuristic optimization
Metaheuristics • Simulated Annealing • Genetic Algorithms • Swarm Intelligence • Ant Colony • Taboo search • Scatter search • Variable neighborhood • Neural Networks • Etc.
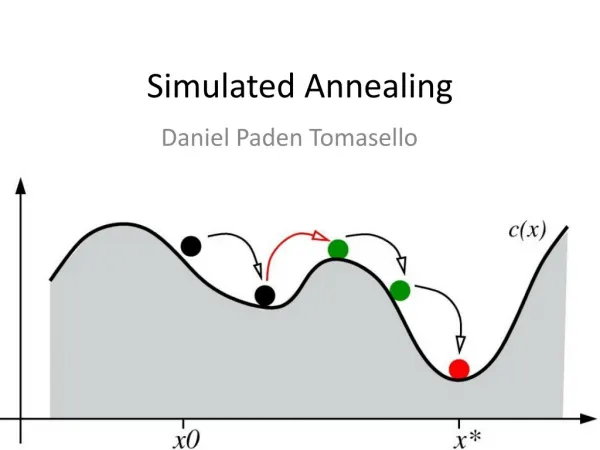
Simulated Annealing algorithm Simulated Annealing algorithm is developed by modeling steel annealing process (Metropolis et al. (1953)) A lot of applications in Operational Research and Data Analysis, etc.
Simulated Annealing Main idea: to simulate drift of current solution with probability distribution to improve solution updating - temperature function - neighborhood function
Simulated Annealing algorithm Step 1. Choose , , , set . Step 2. Generate drift with probability distribution Step 3. If and (Metropolis rule) then accept: ; otherwise Step 2
Improvement of SA by Pareto Type models The theoretical investigation of SA convergence shows, that in these algorithms Pareto type models can be applied to form search sequence (Yang (2000)). Class of Pareto models, main feature and parameter: Pareto model’s distributions have "heavy tails“. α - the main parameter of these models, which impacts the heaviness of the tail α –stable distributions are Pareto (follows to C.L.T.)
Pareto type (Heavy-tailed) distributions Main features: infinite variance, infinite mean Introduced by Pareto in the 1920’s Mandelbrot established the use of heavy-tailed distributions to model real-world fractal phenomena. There are a lot of other applications (financial market, traffic in computer and telecommunication networks, etc.).
Pareto type (Heavy-tailed) distributions Decay of Distributions Heavy-Tailed - Power Law (polynomial) Decay (e.g. Pareto-Levy): where 0 < α < 2 and C > 0 are constants
Comparison of tail probabilities for standard normal, Cauchy and Levy distributions In this table were compared the tail probabilities for the three distributions. It is clear that the tail probability for the normal quickly becomes negligible, whereas the other two distributions have a significant probability mass in the tail.
Improvement of SAS by Pareto type models The convergence conditions (Yang (2000)) indicate that, under suitable conditions, an appropriate choice of the temperature and neighborhood size updatingfunctions ensures the convergence of the SA algorithm to the global minimum of the objective function over the domain of interest. The following corollaries give different forms of temperature and neighborhood size updating functions corresponding to different kinds of generation probability density functions to guarantee the global convergence of the SA algorithm.
Improvement of SA in continuous optimization The above corollaries indicate that a different form of temperature updating function has to be used with respect to a different kind of generation probability density function in order to ensure the global convergence of the corresponding SA algorithm.
Convergence of Simulated Annealing Some Pareto-type models were explored. See the Table 1.
Testing of SA for continuous optimization In global and combinatorial optimization problems, when optimization algorithms are used, the reliability and efficiency of these algorithms is needed to be tested. Special testing functions, known in literature, are used for this. Some of these functions have one or more global minimum, some of them have global and local minimums. With the help of these functions it can be ensured, that the methods are efficient enough, thus, it is possible to test and prevent algorithms from being trapped in local minimum, as well as the speed and accuracy of convergence and other parameters can be watched.
Testing criteria By modeling SA algorithm with some testing functions with two different distributions, and changing some optional parameters, there were some questions: • which of these distributions guarantees the faster convergence to global minimum by value of objective function; • what are probabilities of finding global minimum, how can impact these probabilities the changing of some parameters; • what the proper number of iterations, which guarantees the finding global minimum with desirable probability.
Testing criteria Characteristics evaluated by Monte-Carlo simulation: • value of minimized objective function; • probability to find global minimum after some number of iterations. • These characteristics were computed by Monte-Carlo method - N realizations (N=100, 500, 1000) with K iterations each (K=100, 500, 1000, 3000, 10000, 30000).
Testing functions An example of test function: Branin’s RCOS (RC) function (2 variables): RC(x1,x2)=(x2-(5/(42))x12+(5/)x1-6)2+10(1-(1/(8)))cos(x1)+10; Search domain: 5 < x1 < 10, 0 < x2 < 15; 3 minima: (x1 , x2)*=(- , 12.275), ( , 2.275), (9.42478 , 2.475); RC((x1 , x2)*)=0.397887.
Simulation results Fig. 1. Probability to find global minimum by SA for Rastrigin function
Wrap-Up and Conclusions • The SA methods have been considered for comparison SPSA with Lipschitz perturbation operator; SPSA with Uniform perturbation operator and SFDA method as well Simulated Annealing; • Computer simulation by Monte-Carlo method has shown that the empirical estimates of the rate of convergence of SA for nondifferentiable functions corroborate the theoretical rates