1 / 32
330 likes | 443 Views
Enables you to run AWS Lambda functions globally so that you can process and respond to user requests at low latencies. Running Lambda functions in close geographical proximity to users helps satisfy a number of use cases, such as website personalization, Search Engine

E N D
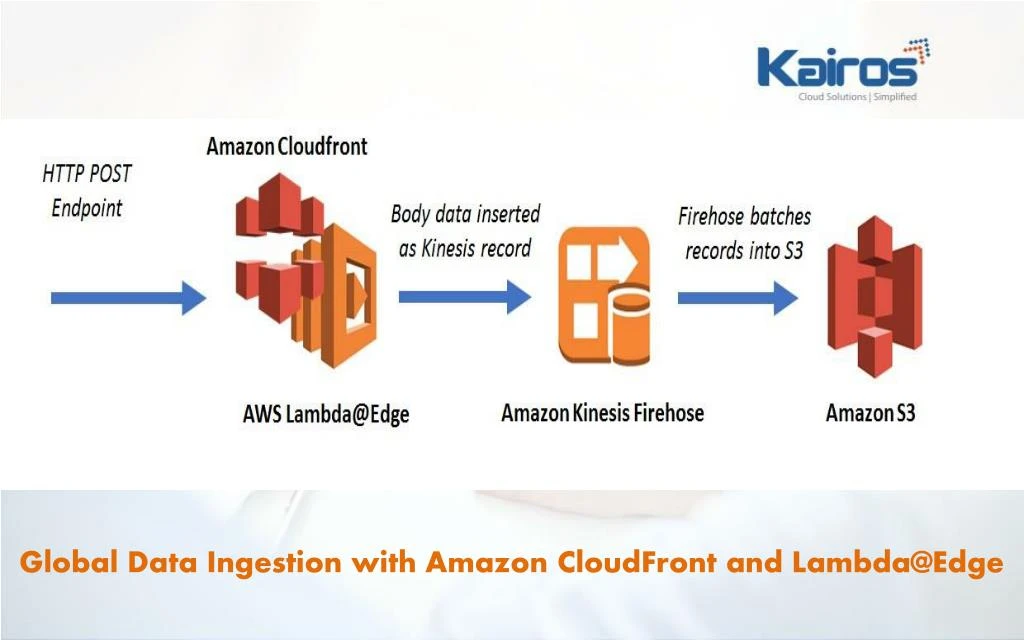
Global Data Ingestion with Amazon CloudFront and Lambda@Edge
Lambda@Edge enables you to run AWS Lambda functions globally so that you can process and respond to user requests at low latencies. Running Lambda functions in close geographical proximity to users helps satisfy a number of use cases, such as website personalization, Search Engine Optimization (SEO), URL re-writes, and A/B testing – just to name a few. Today we announced that Lambda@Edge can now access the HTTP Request Body. This functionality enables new use cases to leverage the benefits of edge computing. In this post, we’ll take a look at one specific scenario: a global data ingestion passthrough through Amazon CloudFront, Lambda@Edge, and Amazon Kinesis Firehose into Amazon S3. You can use Amazon Kinesis Firehose as a serverless streaming ingestion engine for many different kinds of data, ranging from log files to impression data. By ingesting data from producers, the data can be stored durably and is readily available for analysis. Many customers use the AWS SDKs or the Kinesis Producer Library to ingest data, or they install Kinesis Agents for ingestion and ease-of-use. But when your data producers are distributed across a highly-volatile number of clients, you’ll need a scalable service to handle the traffic. An example of this is when clients just use web browsers, and incorporating SDK/producer library into your website might not be easy. Since Amazon Cloudfront speaks plain HTTP (no AWS SDK required), the client side javascripts (example: web bugs/beacons etc) can easily communicate with the HTTP endpoint of CloudFront. With CloudFront’s integration with Lambda@Edge, you can create an ingestion layer with Amazon Kinesis Firehose by using just a few simple configuration steps and lines of code. After the data is ingested into Kinesis Firehose, it can be durably saved in a storage solution such as Amazon S3.
While we’re using Amazon Kinesis Firehose as an example in this blog, Amazon Kinesis Streams works as well. The following are the services that we’ll be using:
To help this solution scale globally, users in different locales will receive local geographical acknowledge that the message was received. Responding locally is much faster than sending traffic to the origin first, as shown in the following diagram:
Another advantage of using CloudFront together with Lambda@Edge is that you can use the built-in security that AWS Web Application Firewall (WAF) provides. By using WAF, you can whitelist and blacklist client IP addresses, and you’re protected against other malicious application traffic as well. In the following steps, we’ll guide you through setting up CloudFront, and then we’ll show you how to configure Lambda@Edge to ingest client data into Amazon Kinesis Firehose over the internet. 1 – Create a CloudFrontdistribution We’ll start by creating a CloudFront distribution that can point to any origin on S3. We don’t need a real origin for our example because Lambda@Edge always executes on HTTP POST requests for Viewer Requests, therefore traffic will never reach the origin (There’s more about how this works in the Lambda@Edge setup steps). CloudFront requires an origin when you create a distribution, though, so we’re setting up an empty one.
Open the CloudFront console at https://console.aws.amazon.com/cloudfront. choose Create Distribution.
4. Choose the options for the distribution, using the guidance in the following diagram. You can leave the default settings for anything that isn’t called out here.
It may take a few minutes for the CloudFront distribution to deploy to the AWS global edge locations. The distribution will then show a Status of Deployed and a State of Enabled as shown below: Make a note of the Distribution ID and Domain Name. We’ll need to specify the distribution ID when we create the trigger for our Lambda@Edge function, and the domain name is required when we send the POST request.
2 – Create Kinesis Firehose delivery streams Next, you need to create a Kinesis Firehouse delivery stream in every AWS region where you have users. This delivery stream will ingest the data from the Lambda@Edge function. In this section, we’ll show you how to set up this function: In the AWS Management Console, choose the US-East-1 (N. Virginia) region, and then navigate to the Kinesis service. On the left pane, choose Data Firehose, then click Create Delivery Stream In Step 1 of the setup process, under Delivery Stream Name, type a name and remember it because it will be used in the Lambda function in Module 3. Also configure the radio button, Direct PUT or other sources
4. In Step 2, leave defaults and click Next 5. In Step 3, choose Amazon S3 as the Destination, and select an S3 Bucket (or create a new one) for the destination for the data ingestion. Optionally, you can specify a prefix name to further categorize this data in the S3 bucket. Then Click Next.
6. In Step 4, you can leave the default Buffer size and intervals (or specify your own). Also, create or choose/create an IAM role and ensure it has PUT permissions to the S3 bucket set up in Step 3.
In the last Step 5, review the settings and create the Delivery Stream. • Notes: • For best performance, you can create a Kinesis Firehose in every region where the clients may send data. For this solution brief and code, use the same Firehose Delivery Stream Name in every region. • Remember to note the name of the Kinesis Firehose name to use in the next section. • 3 – Build a Lambda@Edge ingestion function • With the CloudFront distribution and the Kinesis Firehouse streams in place, the next step is to create the Lambda@Edge function. • In the AWS Management Console, choose the US-East-1 (N. Virginia) region, and then navigate to the Lambda service. • Choose Create Function, and then Author From Scratch.
3. Enter a name for your function, and then, for Runtime, choose Node.js 6.10. 4. For Role, select Create Custom Role. This will open a new window into Identity and Access Management (IAM):
In the new pop-up window, we’re going to create and reference a new IAM Role that we’ll call kinesis_producer. To set it up, do the following: • Policy Documents: AmazonKinesisFullAccess and AWSLambdaBasicExecutionRole
Trust Relationship policy document: Js { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "edgelambda.amazonaws.com", "lambda.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }
6. Under Configuration Designer, choose CloudFront, then choose the Cloudfront trigger icon. 7. Under Configure triggers, in the Distribution text box, enter the CloudFront distribution ID for the distribution created in Step 1.
For the other settings, choose the following: • For Cache behavior, choose *. • For CloudFront event, choose Viewer request. • For Include Body, select the check box. • For Enable trigger and replicate, select the check box.
Because the CloudFront trigger event is Viewer request, all client viewer requests will execute this Lambda@Edge function. And because our function then inserts the request into Kinesis, the CloudFront distribution won’t ever access the origin server. This is why we simply configure to any origin server to use with the CloudFront distribution.
9. Choose Add to create the trigger. Now we’ll add the Lambda@Edge code and configuration. 10. Scroll up, and then select the Edge_Producer Lambda function.
11. Scroll down, and then copy the following Node.js code into the inline editor. Js 1 exports.handler = (event, context, callback) => { 2 varbodyData = new Buffer(event.Records[0].cf.request.body.data, 'base64').toString("utf-8"); 3 var AWS = require('aws-sdk'); 4 //varkinesisfh = new AWS.Firehose({region: 'us-east-1'}); //uncomment if you want a specific-region of Firehose 5 varkinesisfh = new AWS.Firehose(); //or provision a firehose in every region where Lambda may run 6 varparams = { 7 DeliveryStreamName: 'edgetest', /* required */ 8 Record: { /* required */ 9 Data: JSON.stringify({bodyData}) 10 } 11 }; 12 varresponseBody = "Successfully Submitted Record"; 13 responseBody += bodyData; 14 responseBody += context.invokedFunctionArn; 15 responseBody += "Invoke Id: "; 16 responseBody += context.invokeid;
17 kinesisfh.putRecord(params, function(err, data) { 18 if (err) console.log(err, err.stack); // an error occurred 19 else console.log(responseBody); // successful response 20 }); 21 var headers = []; 22 headers['strict-transport-security'] = [{ 23 key: 'Strict-Transport-Security', 24 value: "max-age=31536000; includeSubdomains; preload" 25 }]; 26 headers['content-security-policy'] = [{ 27 key: 'Content-Security-Policy', 28 value: "default-src 'none'; img-src 'self'; script-src 'self'; style-src 'self'; object-src 'none'" 29 }]; 30 headers['x-content-type-options'] = [{ 31 key: 'X-Content-Type-Options', 32 value: "nosniff" 33 }]; 34 const response = { 35 body: responseBody, 36 bodyEncoding: 'text', 37 headers,
38 status: '200', 39 statusDescription: 'OK' 40 }; 41 callback(null, response); 42 return response; 43 }; Note the following: Line 2 : This line converts the Base64-encoded body data into a human-readable string. Body data is now available from the event record: event.Records[0].cf.request.body.data Line 4: If your Firehose is created in a single region (in this case N. Virginia), you can uncomment this line (make sure that you also delete the line that follows). This will add latency for the message acknowledgement response. Line 7: Enter the name of your Kinesis Firehose delivery stream here (replace “edgetest”).
Configure the following Lambda@Edge settings: For Network, choose No VPC For Memory, choose the lowest option (128MB) For Timeout, choose 0 minutes 5 seconds
All finished! Now let’s test our Lambda@Edge function by using a simple HTTP request engine, such as Postman, to send POST requests to our Cloudfront Distribution domain name. Note that the Lambda@Edge execution logs will appear in CloudWatch in the region closest to the user. Here’s an example of a curl command you can use to test from a client: curl <cloudfront URL> --request POST --data <ingestion data> In the above curl test command, <cloudfront URL> is the endpoint created by Cloudfront and <ingestion data> is the type of data you’d like to ingest. The example above works well for unauthenticated requests. If you’d like to build authentication into your Lambda@Edge function using AWS services such as Amazon Cognito, see the following blog post: Authorization@Edge. You can also leverage other forms of security and protection through CloudFront’s integration with AWS Web Application Firewall. For example, for this use-case, you could whitelist known IP adresses that may be trusted data producers of this traffic.
Conclusion Now that body access is available for Lambda@Edge, you can follow this straightforward guidance to set up a front-end for edge-enabled global data ingestion using AWS serverless services. This cost-effective approach can help you speed up performance as well as take advantage of built-in security controls available as part of the AWS cloud. This Article Source is From : https://aws.amazon.com/blogs/networking-and-content-delivery/global-data-ingestion-with-amazon-cloudfront-and-lambdaedge/?sc_channel=sm&sc_campaign=launch_&sc_publisher=TWITTER&sc_country=Global&sc_geo=GLOBAL&sc_outcome=awareness&trkCampaign=sm_CloudFront_0c95796b_Lambda_at_Edge_access_to_request_body&trk=_TWITTER&sc_content=CloudFront_0c95796b_Lambda_at_Edge_access_to_request_body&sc_category=AWS_Lambda&linkId=55556494
THANK YOU http://www.kairostech.com