Download

1 / 33
330 likes | 530 Views
The Design of the Borealis Stream Processing Engine. CIDR 2005 Brandeis University, Brown University, MIT. Kang, Seungwoo 2005.3.15. Ref. http://www-db.cs.wisc.edu/cidr/presentations/26 Borealis.ppt. One-line comment.

E N D
The Design of the Borealis Stream Processing Engine CIDR 2005 Brandeis University, Brown University, MIT Kang, Seungwoo 2005.3.15 Ref. http://www-db.cs.wisc.edu/cidr/presentations/26 Borealis.ppt
One-line comment • This paper presents an overview of the design for Borealis distributed stream processing engine with new features and mechanisms
Outline • Motivation and Goal • Requirements • Technical issues • Dynamic revision of query results • Dynamic query modification • Flexible and scalable optimization • Fault tolerance • Conclusion
Motivation and Goal • Envision the second-generation SPE • Fundamental requirements of many streaming applications not supported by first-generation SPE • Three fundamental requirements • Dynamic revision of query results • Dynamic query modification • Flexible and scalable optimization • Present the functionality and preliminary design of Borealis
Requirements • Dynamic revision of query results • Dynamic query modification • Flexible and highly scalable optimization
Changes in the models • Data model • Revision support • Three types of messages • Query model • Support revision processing • Time travel, CP views • Support modification of Op box semantic • Control lines • QoS model • Introduce QoS metrics in tuple basis • Each tuple (message) holds VM (Vector of Metrics) • Score function
Architecture of Borealis Modify and extend both systems, Aurora and Medusa, with a set of features and mechanisms
Dynamic revision of query results • Problem • Corrections of previously reported data from data source • Highly volatile and unpredictable characteristics of data sources like sensors • Late arrival, out-of-order data • Just accept approximate or imperfect results • Goal • Support to process revisions and correct the previous output result
(3pm,$11) (2pm,$12) (2:25,$9) (4:15,$10) (4:05,$11) (1pm,$10) Average price 1 hour Causes for Tuple Revisions • Data sources revise input streams: “On occasion, data feeds put out a faulty price [...] and send a correction within a few hours” [MarketBrowser] • Temporary overloads cause tuple drops • Data arrives late, and miss its processing wnd
New Data Model for Revisions header data • time: tuple timestamp • type: tuple type • insertion, deletion, replacement • id: unique identifier of tuple on stream (time,type,id,a1,...,an)
(3pm,$11) (2pm,$11) (2pm,$12) (3pm,$11) (2:25,$9) (1pm,$10) (2pm,$12) Average price Average price 1 hour 1 hour Revision Processing in Borealis • Closed model: revisions produce revisions
Revision Processing in Borealis • Connection points (CPs) store history (diagram history with history bound) • Operators pull the history they need Input queue Operator Stream S CP Most recent tuple in history Oldest tuple in history Revision
Discussion • Runtime overhead • Assumption • Input revision msg < 1% • Revision msg processing can be deferred • Processing cost • Storage cost • Application’s needs / requirements • Whether it is interested in revision msg or not • What to do with revision msg • Rollback, compensation ?? • Application’s QoS requirement • Delay bound
Dynamic query modification • Problem • Change certain attributes of the query at runtime • E.g. network monitoring • Manual query substitutions – high overhead, slow to take effect (starting with an empty state) • Goal • Low overhead, fast, and automatic modifications • Dynamic query modification • Control lines • Provided to each operator box • Carry messages with revised box parameters (window size, filter predicate) and new box functions • Timing problem • Specify precisely what data is to be processed according to what control parameters • Data is ready for processing too late or too early • old data vs. new parameter -> buffered old parameters • new data vs. old parameter -> revision message and time travel
Time travel • Motivation • Rewind history and then repeat it • Move forward into the future • Connection Point (CP) • CP View • Independent view of CP • View range • Start_time • Max_time • Operations • Undo: deletion message to roll back the state to time t • Replay • Prediction function for future travel 1 2 3 4 5 6 2 3 4 3 4 5 6
Discussion • How to determine whether timing problem occurs or not • Too early: Lookup data buffered in CP • Too late: Checking timestamp of the tuple • Checking overhead • “Performed on a copy of some portion of the running query diagram, so as not to interfere with processing of the running query diagram” • Who makes a copy, when, how to make? How to manage? • Future time travel • When is it useful? • E.g alarming ?
Optimization in a Distributed SPE • Goal: Optimized resource allocation • Challenges: • Wide variation in resources • High-end servers vs. tiny sensors • Multiple resources involved • CPU, memory, I/O, bandwidth, power • Dynamic environment • Changing input load and resource availability • Scalability • Query network size, number of nodes
Quality of Service • A mechanism to drive resource allocation • Aurora model • QoS functions at query end-points • Problem: need to infer QoS at upstream nodes • An alternative model • Vector of Metrics (VM) carried in tuples • Content: tuple’s importance, or its age • Performance: arrival time, total resource consumed, .. • Operators can change VM • A Score Function to rank tuples based on VM • Optimizers can keep and use statistics on VM
State Confidence Area Thermal Hydration Cognitive Life Signs Wound Detection 90% 60% 100% 90% 80% Physiologic Models S S S Example Application: Warfighter Physiologic Status Monitoring (WPSM)
VM ([age, confidence], value) HRate Model1 RRate Merge Model2 Temp Sensors Models may change confidence. SF(VM) = VM.confidence x ADF(VM.age) Score Function age decay function
Borealis Optimizer Hierarchy End-point Monitor(s) Global Optimizer Neighborhood Optimizer Local Monitor Local Optimizer Borealis Node statistics trigger decision
Optimization Tactics • Priority scheduling - Local • Modification of query plans - Local • Changing order of commuting operators • Using alternate operator implementations • Allocation of query fragments to nodes - Neighborhood, Global • Load shedding - Local, Neighborhood, Global
Priority scheduling • Highest QoS Gradient box • Evaluate the predicted-QoS score function on each message with values in VM • average QoS Gradient for each box • By comparing average QoS-impact scores between the inputs and outputs of each box • Highest QoS-impact message from the input queue • Out-of-order processing • Inherent load shedding behavior
A C B D S1 S2 A B S1 Connected Plan Cut Plan C D r r S2 2cr 2r 2r 4cr 3cr 3cr Correlation-based Load Distribution • Under the situation that network BW is abundant and network transfer delays are negligible • Goal: Minimize end-to-end latency • Key ideas: • Balance load across nodes to avoid overload • Group boxes with small load correlation together • Maximize load correlation among nodes
Load Shedding • Goal: Remove excess load at all nodes and links • Shedding at node A relieves its descendants • Distributed load shedding • Neighbors exchange load statistics • Parent nodes shed load on behalf of children • Uniform treatment of CPU and bandwidth problem • Load balancing or Load shedding?
Node A Node B 4C C r1 r2 App1 3C C r1 r2 App2 Local Load Shedding Goal: Minimize total loss r2’ 25% 58% CPU Load = 5Cr1, Cap = 4Cr1 CPU Load = 4Cr2, Cap = 2Cr2 CPU Load = 3.75Cr2, Cap = 2Cr2 No overload No overload A must shed 20% B must shed 50% A must shed 20% A must shed 20% B must shed 47%
Node A Node B 4C C r1 r2 App1 3C C r1 r2 App2 Distributed Load Shedding Goal: Minimize total loss r2’ 9% r2’’ 64% CPU Load = 5Cr1, Cap = 4Cr1 CPU Load = 4Cr2, Cap = 2Cr2 No overload No overload A must shed 20% B must shed 50% A must shed 20% A must shed 20% smaller total loss!
data Proxy control Sensors control message from the optimizer Extending Optimization to Sensor Nets • Sensor proxy as an interface • Moving operators in and out of the sensor net • Adjusting sensor sampling rates
Discussion • QoS-based optimization • QoS score calculations, statistics maintaining • tuple basis • Fine-grained but lots of processing • Application’s burden • QoS specifications • How to facilitate the task?
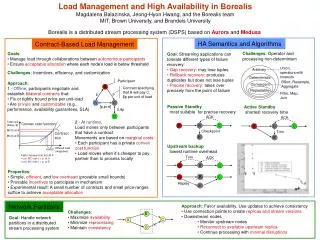
Node 3 U m U S m Node 3’ Node 1’ Node 2’ U m s3’ Fault-Tolerance through Replication • Goal: Tolerate node and network failures s3 Node 1 Node 2 U S m s1 s2 s4
Fault-Tolerance Approach • If an input stream fails, find another replica • No replica available, produce tentative tuples • Correct tentative results after failures STABLE UPSTREAM FAILURE Missing or tentative inputs Failure heals Another upstream failure in progress Reconcile state Corrected output STABILIZING
Conclusions • Next generation streaming applications require a flexible processing model • Distributed operation • Dynamic result and query modification • Dynamic and scalable optimization • Server and sensor network integration • Tolerance to node and network failures • http://nms.lcs.mit.edu/projects/borealis
Discussion • Distributed environment • Load management • Fault tolerance • How about data routing / forwarding issue ?? • Other problems not tackled?