Download

1 / 45
450 likes | 583 Views
Cluster Analysis & Hybrid Models Business Application & Conceptual Issues Oct 4, 2005. Today’s Outline. Introduction & Intro to Clustering Applied Problem- Dissertation Conceptual/Practical Issues Research Ideas Good Clusters/Bad Clusters & Interpretation

E N D
Cluster Analysis & Hybrid Models Business Application & Conceptual Issues Oct 4, 2005 William B. Hakes, Ph.D.-V 100305
Today’s Outline • Introduction & Intro to Clustering • Applied Problem- Dissertation • Conceptual/Practical Issues • Research Ideas • Good Clusters/Bad Clusters & Interpretation • Applied Problem II/Binary Clustering • Applied Problem III- Interpretation- Clustering from a Survey • Trees (RI)- Intro • Dissertation RI • For Further Research William B. Hakes, Ph.D.-V 100305
Introduction • A financial analyst of an investment firm is interested in identifying groups of mutual funds that are look alike in a “true” context, not simply based on the way Morningstar rates them. • A marketing manager is interested in identifying similar cities (across multiple dimensions) that can be used for a test marketing campaign in which a new product might be introduced. • The Director of Marketing at a telecom firm wants to understand the types of people that he already knows are candidates for the firm’s new internet data service • A Golf Club General Manager wants to understand the “natural” segments of his members so that he can better utilize his clubs assets and understand how he might ideally want the club to look in the future. William B. Hakes, Ph.D.-V 100305
Cluster Overview • Cluster Analysis- its easy when: • You have a relatively small sample • You have nice, neat data • Your variables are continuous • Cluster Analysis- The Real World • Sometimes sample are small, but in business they’re large • We’d like our data to be free from error, containing no outliers, but that is rarely the case. • Variables are often a mix of continuous and categorical data William B. Hakes, Ph.D.-V 100305
Clustering- Some Competing Macro Views • A) Cluster entire customer base (General Purpose Clusters) • Build predictive models across products • See how your “targeted” customers fall into the clusters, if they provide separability • -or- • B) Build predictive models on base • Determine the “targets” for a specific campaign • Cluster those “targets” based only on actionable information (Specific Purpose Clusters) • -or- • Cluster Analysis as a primary end-analysis • Correct option depends on how you’ll use it! William B. Hakes, Ph.D.-V 100305
Quantitative Problem Domain Cluster Analysis • Why Cluster Analysis? • Commonly Applied: • Targeted Army recruitment- Faulds and Gohmann (2001) • Identify “natural” segments of Euro tourists- Yuksel and Yuksel (2002) • Uncover “natural” groups of common business goals across 15 countries- Hofstede et al. (2002) • Prostate cancer treatment on various types of cells- Li & Sarkar (2002) • Cluster analysis… • Identifies subgroups within a larger group • Makes each object (customer, product etc.)within each group as similar as possible while making the subgroups as different as possible from one another. William B. Hakes, Ph.D.-V 100305
Quantitative Problem Domain Cluster Analysis cont’d • How Does Cluster Analysis Work? • Variable Selection • Generally must be on similar/identical scales (standardized) • Metric- Ordinal/Interval/Ratio • Non-metric data • Correlation & outliers distort results • Principle Components & Factor Analysis as Inputs • Construct similarity/proximity matrix to view relationship between all observations across all variables: • Euclidean Distance (most commonly used) • Other distances measures include Euclidean, Squared Euclidean, City Block, Mahalonobis • Correlation- but consider (1, 2, 1, 2) and (9, 10, 9, 10) vs. (1, 2, 1, 2) and (1, 1, 2, 2) • Association (Jaccard coefficient for binary variables) William B. Hakes, Ph.D.-V 100305
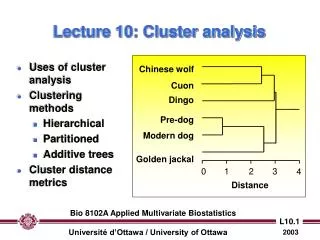
Quantitative Problem Domain Cluster Analysis cont’d • How Does Cluster Analysis Work? • Choose clustering algorithm • Hierarchical- n clusters of size 1 until one cluster remains (EDA & Research) • Choose algorithm to determine how distance is to be computed between clusters. • Iteratively, we continue to “relax" our criterion as to what is and is not unique….lower our threshold regarding the decision when to declare two or more objects to be members of the same cluster (see Dendogram) • Ward’s Method*, single Linkage, centroid, etc. • Non-Hierarchical (K-Means)- assign objects to clusters based on pre-specified number of clusters (Practical Implementation) • Choose seeds for n clusters (often pre-determined) • Clusters are formed, new centroids computed, new clusters formed • A Dual approach is recommended (Hartigan,1975 ; Milligan, 1980 ; Punj & Stewart, 1983) • Use hierarchical clustering to compute estimated cluster centroids • Use centroids as the Cluster seeds for a K-Means analysis William B. Hakes, Ph.D.-V 100305
Quantitative Problem Domain Cluster Analysis cont’d • Choosing the Number of Clusters • Hierarchical- n clusters are formed (use dendogram) • K-Means • Form pre-specified k number based on theory (Milligan, 1980; Hair et al., 1998) • Form pre-specified k number based on application • Consult the“Pseudo-F” in either case to assess solution (Lattin, et al., 2003; Punj & Stewart, 1983) • Interpretation of Clusters • Which variables are important? How important? • Univariate F-Tests on Cluster Centroids • Perspicuity via “art” in initial steps • Perspicuity via a different technique (a hybrid) William B. Hakes, Ph.D.-V 100305
Toward a Hybrid Approach After a predictive model is built, how can variables best be pre-processed for cluster analysis so that rule induction on the resulting clusters provides maximum perspicuity while minimizing the art involved?? …. perhaps a hybrid model so as to minimize the “art” involved while maximizing perspicuity and applicability. William B. Hakes, Ph.D.-V 100305
Clustering- A Problematic Example (I) • Take the following example: You are a firm trying to generate clusters about the Atlanta area with the objective of understanding zip codes to which you want to “mass”market your products. • Many different races exist. How do you cluster them? Typically, its: • 1) White • 2) African American • 3) Asian • 4) Hispanic • 5) Native American • 6) Non-white other • What will clustering do with this variable as it groups people? William B. Hakes, Ph.D.-V 100305
A Problematic Example cont’d • Can you cluster this simple example? • How will you interpret it (e.g., what’s a common way to look at the “answer” to see if you agree with the differentiation)? William B. Hakes, Ph.D.-V 100305
A Problematic Example cont’d • Cluster Means- What do they tell us? • Assume we have three clusters, and along the “race” dimension, they are as follows: • Cluster 1- Mean=2 • Cluster 2- Mean=4 • Cluster 3- Mean=1 • How do you: • Use this data to assign people into clusters? • Interpret means? William B. Hakes, Ph.D.-V 100305
Binary Variables- One Possible Solution? William B. Hakes, Ph.D.-V 100305
Binary Variables- A Closer Look • How will these cases cluster? • What can we do about it? • How similar are persons 101, 102 & 103 to one another….are they more alike or more different? William B. Hakes, Ph.D.-V 100305
Applied Problem II • A Golf Club General Manager wants to understand the “natural” segments of his members so that he can better utilize his clubs assets and understand how he might ideally want the club to look in the future. • How can cluster analysis help? • We took a look at the following • Demographic Information • Usage Information • Cost Information • Some data was measured and some was survey data • Note that in clustering you may use N dummy variables (rather than N-1 in dependent techniques like regression) William B. Hakes, Ph.D.-V 100305
Application of Binary Clustering - Above data taken from one question off of 30Q customer survey. 5 Clusters were formed. - Note that a dummy separated n ways will sum to 100% only if there are no missing responses. William B. Hakes, Ph.D.-V 100305
OBJECT 1 + - OBJECT2 + a (1,1) b (1,0) - c (0,1) d (0,0) Jaccard Coefficient Many different uses , but its works great for clustering (see SPSS) a___ Sj = a + b + c where a is the sum of agreement (+ +) and b, c represent the sums of absent/present combinations (i.e. + - , and - +, respectively). The table below shows this convention of lettering for counts when calculating the similarity between two objects. Values of d are not considered because they represent complete disagreement. Jaccard Process Sample William B. Hakes, Ph.D.-V 100305
Summary of Binary Clustering • Assists when we want to understand the “natural” segments • How can binary cluster analysis help (using Jaccard or otherwise)? • Allows us to use categorical data. • Gives us unique summary insight into the true percentages of each cluster along various dimensions. • Not tricked by the zero problem- if zero’s are “true” zero’s, then clustering can be VERY interpretable • No program as of yet that integrates Jaccard algorithm with traditional algorithms. • Cluster different sets of variables and then cluster the clusters using Jaccard (dummy the cluster membership) • Invent your own technique!!!! (i.e. K-Modes) • All clustering should be “checked” with domain experts for validation. William B. Hakes, Ph.D.-V 100305
Applied Problem III- F&B Survey Analysis For Illustration Purposes Only William B. Hakes, Ph.D.-V 100305
Can Clustering Help…… For Illustration Purposes Only William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Clusters vs. Member Info Can we look at member information we know to be true in order to measure the accuracy of member responses & therefore the clusters? William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Clustering Overview • What are the primary Clusters that exist at the Club? • Big Spenders (8% of Member Base) Age = 53 1 Child Golf/Tennis/Fitness = 4x per month • Opportunity Knocks w/Kids (58% of Member Base) Age = 47 1.5 Children, under 14 Golf=2x/mo SwimPool=8x/mo • Seniors (15% of Member Base) • Age = 69 No Children Golf /Tennis= 3x/mo • Opportunity Knocks no Kids (17% of Member Base) • Age = 56 If Kids, most are 18+ Heaviest Fitness 3x/mo Golf 6x/mo Pool • Heavy All-Around Users (4% of Member Base) • Age = 52 1 Child, Age 11+ Golf/Swim/Fitness = 15x per month William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Results by Question Q4 and Q5 plotted together…What is the relationship between the factors that members find important when selecting a restaurant and their level of satisfaction? 5 High Importance + High Satisfaction = Increased Loyalty Satisfaction 4 Service Quality of Food Atmosphere Price Speed Menu Variety Quality of Wine 3 4 5 Importance Q4- What factors are important to you in selecting a restaurant? Q5- How satisfied are you with the same factors at the Club? William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Importance vs. Satisfaction “Big Spenders” Note that the actual scale begins at “1” but there were no responses measured below “3” William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Importance vs. Satisfaction “Opp Knocks/kids” Note that the actual scale begins at “1” but there were no responses measured below “3” William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Importance vs. Satisfaction “Seniors” Note that the actual scale begins at “1” but there were no responses measured below “3” William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Importance vs. Satisfaction “Opp Knocks no kids” Note that the actual scale begins at “1” but there were no responses measured below “3” William B. Hakes, Ph.D.-V 100305
F&B Survey Analysis – Importance vs. Satisfaction “Heavy Users” Note that the actual scale begins at “1” but there were no responses measured below “3” William B. Hakes, Ph.D.-V 100305
Points to Ponder- Clustering • Pros- • 1) Good for exploratory analysis • 2) Helps discover previous unsuspected relationships • 3) One of very few techniques that focuses on the groups it creates, not the variate that creates them • Cons- • Difficult to interpret/often not actionable • Deemed as too “soft” by some statisticians and businesses • Out of sample customer assignment is very tough • Solution- Hierarchical Non-Hierarchical Consult Expert -or- • Hierarchical Non-Hierarchical RuleInduction Consult Expert William B. Hakes, Ph.D.-V 100305
Hybrid Test Extracted Group of Targeted Customers Determine “Target “Group Variable pre-processing as inputs 3- X1 B1– XnBn (from Logit) 4- Principal Component Scores 1- Original Vars 2- Stdized Version of 1 Hierarchical Cluster Analysis (seeds developed) Extract the pre-specified number of clusters as seeds for next stage Original Vars Std Vars Logit Vars PCA Vars K-means Cluster Analysis (refined solutions) Generate a pre-specified number of clusters using seeds from prior CA Logistic Regression Original Vars Std Vars Logit Vars PCA Vars Input each cluster solution into RI program and create RI solutions Rule Induction (CART) Orig Var RI Solution Std Var RI Solution Logit Var RI Solution PCA Var RI Solution Transform rules into text descriptions and submit to Expert Panel for review Expert Panel Review Each of 4 RI Solutions tested for Usefulness/Perspicuity using ANOVA/Tukey’s HSD)
Dissertation- Testing a Hybrid Method • Credit Data: real-world data from financial services (auto loans) • Predictive Model differentiating “goods” vs. “bads” • Given that we think you’re “good”, what else is there? • Cross selling opportunities • You’re a good risk, but certainly there is more to offer you • Consider GE Capital • Purchasing Data: real-world motor-home data from overseas company • Predictive Model differentiating buyers vs. non-buyers • Given that we think you’re a “buyer”, what else is there? • Compelling qualitative messages • You’re likely a buyer, but certainly all buyers are not the same • Consider XYZ Telecom William B. Hakes, Ph.D.-V 100305
A Hybrid Approach • Why is a Hybrid model necessary for perspicuity? • Predictive Models- Most methods are 1st Order • Differentiate target group from non-target group (binary) • Determine model which best differentiates pre-defined groups (3 or more categories). • Cluster Analysis- • Simply identifies similar items/customers within a population (Fasulo, 1999). • Rule Induction- • Requires a pre-defined dependent variable so that key independent variables may be distinguished • The Hybrid model: • Converts a numerical model into a second order model expressed in natural language If-Then rules, exposing the behavior of the system to view (Whalen & Gim, 1999). • “Explains group membership” rather than simply “proportioning variance”. William B. Hakes, Ph.D.-V 100305
Overview of Decision Trees/Rule Induction RI- Rules are induced based upon a set of inputs and a criterion (dependent) variable Although many different techniques exist such as CART, ID3, CHAID, and many others, they all tend to utilize the following procedures, even though they each have different splitting rules (Whalen & Gim, 1999): 1) Identify a dependent variable of interest along with a set of independent (predictor) variables. 2) Compare all cutpoints of predictor variables to find the one that best predicts the dependent variable (using some statistical rule, though these rules differ among methods). 3) Identify the next best rule (a predictor variable along a certain cutpoint) in each of the sub-samples already defined by (2). 4) Continue to split until all remaining subsamples are homogenous with respect to the dependent variable. 5) The set of if-then rules from the analysis are applied to a validation set to determine performance. William B. Hakes, Ph.D.-V 100305
PATIENTS = 215 SURVIVE 178 82.8% DEAD 37 17.2% Is BP<=91? <= 91 > 91 Terminal Node A SURVIVE 6 30.0% DEAD 14 70.0% NODE = DEAD PATIENTS = 195 SURVIVE 172 88.2% DEAD 23 11.8% Is AGE<=62.5? > 62.5 <= 62.5 Terminal Node B SURVIVE 102 98.1% DEAD 2 1.9% NODE = SURVIVE PATIENTS = 91 SURVIVE 70 76.9% DEAD 21 23.1% Is SINUS<=.5? <=.5 >.5 Terminal Node C SURVIVE 14 50.0% DEAD 14 50.0% NODE = DEAD Terminal Node D SURVIVE 56 88.9% DEAD 7 11.1% NODE = SURVIVE Trees (Binary) Are Fundamentally Simple William B. Hakes, Ph.D.-V 100305
Credit Cluster Size Comparison Credit: Hierarchical K-Means William B. Hakes, Ph.D.-V 100305
back Variable Definitions: T2924X= <=1 Trd 30dpd in 24 mo AGEAVG = Age Avg Open Trd TOTBAL = TotBal of all trades RVTRDS = # Rev Trades Appendix 6a Credit RI Tree: PCA Vars 2a 1b 3b 1a 3a
Issues for Further Research • Predictive Models differentiate one group from another, but what about types of groups within a target group?…How Many? • Cluster Analysis • Which variables are important in clustering? • What about out-of-sample assignment? • Clustering followed by 2nd Order Rule Induction (a.k.a. Decision Trees) • Develop clusters (2-stage) • Use as inputs into algorithm (“Best”Algorithm??) • Take simple rules and use to assess cases across a database • Cluster Analysis vs. Unsupervised NN’s William B. Hakes, Ph.D.-V 100305
Some Parting Thoughts…. Q- How much time should you spend properly defining the quantitative issue and designing the test?? A- A lot more than you think (up to 3x more than the actual “analysis”) Q- Are there opportunities for Analytics in the marketplace?? A- Yes- tremendous opportunities for people who can do more than Pivot Tables and Regression in Excel. Q- How do I “get my foot in the door” of analytics? A- Continue formal education Continue “informal” education as well Make “networking” part of your daily/weekly to-do list Join a firm that has years of experience in applied problem-solving William B. Hakes, Ph.D.-V 100305
Appendix Following are some slides that we may not have time to talk thru. Feel free to contact me with any questions. William B. Hakes, Ph.D.-V 100305
Overview of CART • Classification and Regression Trees • Origins in research conducted at Berkeley & Stanford • Leo Breiman, University of California, Berkeley • Jerry Friedman, Stanford University • Charles J. Stone, University of California, Berkeley • Richard Olshen, Stanford University • Solved a number of problems plaguing other decision tree methods (CHAID, ID3) • Very well known in biomedical and engineering arenas • Only recently becoming known in IT, DM, and AI circles William B. Hakes, Ph.D.-V 100305
Why CART Works Well • A binary splitting procedure can always reproduce a multi-way split • A binary splitting procedure will only partially partition on a database field if another sequence is better FYI- • CART (and trees in general) handle missing data very well • Tests show that when data are missing at random even 25% missing rates have minimal effect on CART accuracy • Costs of misclassification: allow for certain errors to be more serious than others • Fundamentally detects non-linear relationships • Rules can be automatically detected, or modified by user William B. Hakes, Ph.D.-V 100305
Binary Split Detects MultiWay Splits If the multi-way split is best, binary split method will find it If it is not best, binary method will move to another variable William B. Hakes, Ph.D.-V 100305
MultiWay Splits • Split made all at once could be too hasty • Even if age group is different, other variables might be even more valuable after the Age > 65, Age < 65 split • The database is fragmented rapidly • Even with 500,000 records, 5 consecutive 4-way splits leave about 2,000 records per partition • Binary splits are more patient, giving a better chance to find important structure William B. Hakes, Ph.D.-V 100305
Credit RI Translation (NOTE: this dataset is tough to translate in this context) • Credit RI Tree PCA Vars- Translated Rules: Cluster 1- (51% of Customers) - (1a) 81% of the customers in this cluster have: • Over the last 24 months, 1 or less trades rated 30 days past due. • Some information available regarding the average age of their open trades. • 5 or less “revolving” accounts. - (1b) The other 19% of the customers in this cluster have: • Over the last 24 months, 2 or more trades rated 30 days past due. • A total balance of all trades less than $3837.00. Cluster 2- (9% of Customers) - (2) Over the last 24 months, these customers have 1 or less trades rated 30 days past due. - (2) These customers have either no record of the age of their current accounts, or they only have “inquiries” into their credit history. Cluster 3- (40% of Customers) - (3a) 15% of the customers in this cluster have: • Over the last 24 months, 1 or less trades rated 30 days past due. • Some information available regarding the average age of their open accounts. • 6 or more “revolving” trades. - (3b) 85% of the customers in this cluster have: • Over the last 24 months, 2 or more trades rated 30 days past due. • A total balance of all trades is greater than or equal to $3837.00. William B. Hakes, Ph.D.-V 100305