Download
1 / 15
150 likes | 273 Views
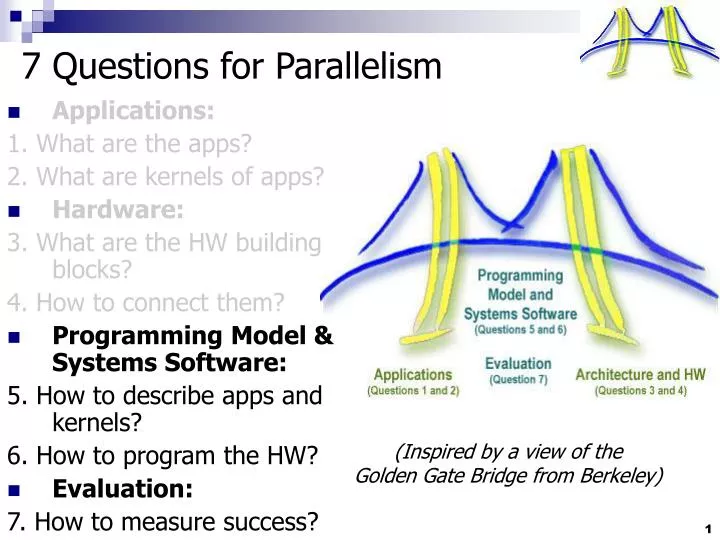
7 Questions for Parallelism. Applications: 1. What are the apps? 2. What are kernels of apps? Hardware: 3. What are the HW building blocks? 4. How to connect them? Programming Model & Systems Software: 5. How to describe apps and kernels? 6. How to program the HW? Evaluation:

E N D
7 Questions for Parallelism • Applications: 1. What are the apps? 2. What are kernels of apps? • Hardware: 3. What are the HW building blocks? 4. How to connect them? • Programming Model & Systems Software: 5. How to describe apps and kernels? 6. How to program the HW? • Evaluation: 7. How to measure success? (Inspired by a view of the Golden Gate Bridge from Berkeley)
How do we describe apps and kernels? • Observation 1: use Dwarfs. Dwarfs are of 2 types • Algorithms in the dwarfs can either be implemented as: • Compact parallel computations within a traditional library • Compute/communicate pattern implemented as framework Libraries • Dense matrices • Sparse matrices • Spectral • Combinational • Finite state machines Patterns/Frameworks • MapReduce • Graph traversal, graphical models • Dynamic programming • Backtracking/B&B • N-Body • (Un) Structured Grid • Computations may be viewed a multiple levels: e.g., an FFT library may be built by instantiating a Map-Reduce framework, mapping 1D FFTs and then transposing (generalize reduce)
Parallel patterns with serial plug-inse.g., MapReduce • Composition is hierarchical Composing dwarfs to build apps • Any parallel application of arbitrary complexity may be built by composing parallel and serial components • Serial code invoking parallel libraries, e.g., FFT, matrix ops.,…
Programming the HW • 2 types of programmers/2 layers • “The right tool for the right time” • Productivity Layer (90% of programmers) • Domain experts / Naïve programmers/productively build parallel apps using frameworks & libraries • Frameworks & libraries composed using C&C Language to provide app frameworks • Efficiency Layer (10% of programmers) • Expert programmers build: • Frameworks: software that supports general structural patterns of computation and communication: e. g. MapReduce • Libraries: software that supports compact computational expressions: e.g. Sketch for Combinational or Grid computation • “Bare metal” efficiency possible at Efficiency Layer • Effective composition techniques allows the efficiency programmers to be highly leveraged.
Coordination & Composition in CBIR Application • Parallelism in CBIR is hierarchical • Mostly independent tasks/data with combining DCT extractor output stream of feature vectors output stream of images feature extraction data parallel map DCT over tiles Face Recog ? DCT combine reduction on histograms from each tile … DWT ? output one histogram (feature vector) combine concatenate feature vectors stream parallel over images task parallel over extraction algorithms
Coordination & Composition Language • Coordination & Composition language for productivity • 2 key challenges • Correctness: ensuring independence using decomposition operators, copying and requirements specifications on frameworks • Efficiency: resource management during composition; domain-specific OS/runtime support • Language control features hide core resources, e.g., • Map DCT over tiles in language becomesset of DCTs/tiles per core • Hierarchical parallelism managed using OS mechanisms • Data structure hide memory structures • Partitioners on arrays, graphs, trees produce independent data • Framework interfaces give independence requirements: e.g., map-reduce function must be independent, either by copying or application to partitioned data object (set of tiles from partitioner)
How do we program the HW?What are the problems? • For parallelism to succeed, must provide productivity, efficiency, and correctness simultaneously • Can’t make SW productivity even worse! • Why do in parallel if efficiency doesn’t matter? • Correctness usually considered orthogonal problem • Productivity slows if code incorrect or inefficient • Correctness and efficiency slow if programming unproductive • Most programmers not ready for parallel programming • IBM SP customer escalations: concurrency bugs worst, can take months to fix • How make ≈90% today’s programmers productive on parallel computers? • How make code written by ≈90% of programmers efficient?
Ensuring Correctness • Productivity Layer: • Enforce independence of tasks using decomposition (partitioning) and copying operators • Goal: Remove concurrency errors (nondeterminism from execution order, not just low level data races) • E.g., the race-free program “atomic delete” + “atomic insert” does not compose to an “atomic replace”; need higher level properties, rather than just locks or transactions • Efficiency Layer: Check for subtle concurrency bugs (races, deadlocks, etc.) • Mixture of verification and automated directed testing • Error detection on framework and libraries; some techniques applicable to third-party software
Support Software: What are the problems? • Compilers and Operating Systems are large, complex, resistant to innovation • Takes a decade for compiler innovations to show up in production compilers? • Time for idea in SOSP to appear in production OS? • Traditional OSes brittle, insecure, memory hogs • Traditional monolithic OS image uses lots of precious memory * 100s - 1000s times (e.g., AIX uses GBs of DRAM / CPU)
21st Century Code Generation • Problem: generating optimal code is like searching for a needle in a haystack • New approach: “Auto-tuners” 1st run variations of program on computer to heuristically search for best combinations of optimizations (blocking, padding, …) and data structures, then produce C code to be compiled for that computer • E.g., PHiPAC (BLAS), Atlas (BLAS), Spiral (DSP), FFT-W • Can achieve 10X over conventional compiler • Example: Sparse Matrix (SPMv) for 3 multicores • Fastest SPMv: 2X OSKI/PETSc Clovertown, 4X Opteron • Optimization space: register blocking, cache blocking, TLB blocking, prefetching/DMA options, NUMA, BCOO v. BCSR data structures, 16b v. 32b indices, … • Search space for matmul block sizes: • Axes are block dim • Temp is speed
Parallelizing compiler + multicore + caches + prefetching Autotuner + multicore + local store + DMA Greater productivity and efficiency for SPMv? • Originally, caches to improve programmer productivity • Not always the case for manycore+autotuner • Easier to autotune single local store + DMA than multilevel caches + HW and SW prefetching
Deconstructing Operating Systems • Resurgence of interest in virtual machines • VM monitor thin SW layer btw guest OS and HW • Future OS: libraries where only functions needed are linked into app, on top of thin hypervisor providing protection and sharing of resources • Partitioning support for very thin hypervisors, and to allow software full access to hardware within partition