Download

1 / 105
1.05k likes | 1.2k Views
Back to Basics, 2011 POPULATION HEALTH (1): Epidemiology Methods, Critical Appraisal, Biostatistical Methods. R.A. Spasoff, MD Epidemiology & Community Medicine Other resources available on Individual & Population Health web site. THE PLAN.

E N D
Back to Basics, 2011POPULATION HEALTH (1): Epidemiology Methods, Critical Appraisal,Biostatistical Methods R.A. Spasoff, MD Epidemiology & Community Medicine Other resources available on Individual & Population Health web site
THE PLAN • These lectures are based around the MCC Objectives for Qualifying Examination • Emphasis is on core ‘need to know’ rather than on depth and justification • Focus is on topics not well covered in the Toronto Notes (UTMCCQE)
THE PLAN(2) • First class • mainly lectures • Other classes • About 2 hours of lectures • Review MCQs for 60 minutes • A 10 minute break about half-way through • You can interrupt for questions, etc. if things aren’t clear.
THE PLAN (3) • Session 1 (April 11, 13:00-16:00) • Diagnostic tests • Sensitivity, specificity, validity, PPV • Critical Appraisal • Intro to Biostatistics • Brief overview of epidemiological research methods
Reliability • = reproducibility. Does it produce the same result every time? • Related to chance error • Averages out in the long run, but in patient care you hope to do a test only once; therefore, you need a reliable test
Validity • Whether it measures what it purports to measure in long run, viz., presence or absence of disease • Normally use criterion validity, comparing test results to a gold standard • Link to SIM web on validity
Reliability and Validity: the metaphor of target shooting.Here, reliability is represented by consistency, and validity by aim Reliability LowHigh • • • • • • • • Low Validity • • • • • • • • High • • • • • • • •
Test Properties (1) True positives False positives False negatives True negatives
2x2 Table for Testing a Test (columns) Gold standard Disease Disease Present Absent Test Positive a (TP) b (FP) Test Negative c (FN) d (TN) Sensitivity Specificity = a/(a+c) = d/(b+d)
Test Properties (2) Sensitivity = 0.90 Specificity = 0.95
Test Properties (6) • Sensitivity = Pr(test positive in a person with disease) • Specificity = Pr(test negative in a person without disease) • Range: 0 to 1 • > 0.9: Excellent • 0.8-0.9: Not bad • 0.7-0.8: So-so • < 0.7: Poor
Test Properties (7) • Values depend on cutoff point • Generally, high sensitivity is associated with low specificity and vice-versa. • Not affected by prevalence, if severity is constant • Do you want a test to have high sensitivity or high specificity? • Depends on cost of ‘false positive’ and ‘false negative’ cases • PKU – one false negative is a disaster • Ottawa Ankle Rules: insisted on sensitivity of 1.00
Test Properties (8) • Sens/Spec not directly useful to clinician, who knows only the test result • Patients don’t ask: “If I’ve got the disease, how likely is a positive test?” • They ask: “My test is positive. Does that mean I have the disease?” • → Predictive values.
Predictive Values • Based on rows, not columns • PPV = a/(a+b); interprets positive test • NPV = d/(c+d); interprets negative test • Depend upon prevalence of disease, so must be determined for each clinical setting • Immediately useful to clinician: they provide the probability that the patient has the disease
2x2 Table for Testing a Test (rows) Gold standard Disease Disease Present Absent Test + a (TP) b (FP) PPV = a/(a+b) Test - c (FN) d (TN) NPV= d/(c+d) a+c b+d N
Test Properties (9) PPV = 0.95 NPV = 0.90
Prevalence of Disease • Is your best guess about the probability that the patient has the disease, before you do the test • Also known as Pretest Probability of Disease • (a+c)/N in 2x2 table • Is closely related to Pre-test odds of disease: (a+c)/(b+d)
Test Properties (10) Prevalence proportion Prevalence odds
Prevalence and Predictive Values • Predictive values of a test are dependent on the pre-test prevalence of the disease • Tertiary hospitals see more pathology then FP’s; hence, their tests are more often true positives. • How to ‘calibrate’ a test for use in a different setting? • Relies on the stability of sensitivity & specificity across populations.
Methods for Calibrating a Test Four methods can be used: • Apply definitive test to a consecutive series of patients (rarely feasible) • Hypothetical table • Bayes’s Theorem • Nomogram You need to be able to do one of the last 3. By far the easiest is using a hypothetical table. E.g., sens = 0.90, spec =0.95
Calibration by hypothetical table Fill cells in following order: “Truth” Disease Disease Total PV Present Absent Test Pos 4th 7th 8th 10th Test Neg 5th 6th 9th 11th Total 2nd 3rd 1st (10,000)
Test Properties (11) Tertiary care: research study. Prev=0.5 PPV = 0.89 Sens = 0.90 Spec = 0.95
Test Properties (12) Primary care: Prev=0.01 585 90 495 PPV = 0.1538 10 9,405 9,415 100 9,900 Sens = 0.90 Spec = 0.95
Calibration by Bayes’ Theorem • You don’t need to learn Bayes’ theorem • Instead, work with the Likelihood Ratio (+ve) • (Equivalent process exists for Likelihood Ratio (–ve), but we shall not calculate it here)
Test Properties (13) Post-test odds (+ve) = 18.0 Pre-test odds = 1.00 Post-test odds (+ve) = LR(+) * Pre-test odds = 18.0 * 1.0 = 18.0, but of course you do not know the LR(+)
Calibration by Bayes’s Theorem • You can convert sens and spec to likelihood ratios LR(+) = sens/(1-spec) • LR(+) is fixed across populations just like sensitivity & specificity. • Bigger is better. • Posttest odds(+) = pretest odds * LR(+) • Convert to posttest probability if desired…
Converting odds to probabilities • Pre-test odds = prevalence/(1-prevalence) • if prevalence = 0.20, then pre-test odds = .20/0.80 = 0.25 • Post-test probability = post-test odds/(1+post-test odds) • if post-test odds = 0.25, then prob = .25/1.25 = 0.20
Calibration by Bayes’s Theorem • How does this help? • Remember: • Post-test odds(+) = pretest odds * LR(+) • To ‘calibrate’ your test for a new population: • Use the LR(+) value from the reference source • Estimate the pre-test odds for your population • Compute the post-test odds • Convert to post-test probability to get PPV
Example of Bayes’s Theorem(‘new’ prevalence 1%, sens 90%, spec 95%) • LR(+) = .90/.05 = 18 (>>1, pretty good) • Pretest odds = .01/.99 = 0.0101 • Positive Posttest odds = .0101*18 = .1818 • PPV = .1818/1.1818 = 0.1538 = 15.38% • Compare to the ‘hypothetical table’ method (PPV=15.38%)
Calibration with Nomogram • Graphical approach avoids some arithmetic • Expresses prevalence and predictive values as probabilities (no need to convert to odds) • Draw lines from pretest probability (=prevalence) through likelihood ratios; extend to estimate posttest probabilities • Only useful if someone gives you the nomogram!
Example of Nomogram(pretest probability 1%, LR+ 18, LR– 0.105) 15% 18 1% .105 0.01% LR Pretest Prob. Posttest Prob. April 2011 31
Are sens & spec really constant? • Generally, assumed to be constant. BUT….. • Sensitivity and specificity usually vary with severity of disease, and may vary with age and sex • Therefore, you can use sensitivity and specificity only if they were determined on patients similar to your own • Risk of spectrum bias (populations may come from different points along the spectrum of disease)
Cautionary Tale #1: Data Sources The Government is extremely fond of amassing great quantities of statistics. These are raised to the nth degree, the cube roots are extracted, and the results are arranged into elaborate and impressive displays. What must be kept ever in mind, however, is that in every case, the figures are first put down by a village watchman, and he puts down anything he damn well pleases! Sir Josiah Stamp, Her Majesty’s Collector of Internal Revenue.
78.2: CRITICAL APPRAISAL (1) • “Evaluate scientific literature in order to critically assess the benefits and risks of current and proposed methods of investigation, treatment and prevention of illness” • UTMCCQE does not present hierarchy of evidence (e.g., as used by Task Force on Preventive Health Services)
Hierarchy of evidence(lowest to highest quality, approximately) • Expert opinion • Case report/series • Ecological (for individual-level exposures) • Cross-sectional • Case-Control • Historical Cohort • Prospective Cohort • Quasi-experimental • Experimental (Randomized) }similar/identical
Cautionary Tale #2: Analysis Consider a precise number: the normal body temperature of 98.6EF. Recent investigations involving millions of measurements have shown that this number is wrong: normal body temperature is actually 98.2EF. The fault lies not with the original measurements - they were averaged and sensibly rounded to the nearest degree: 37EC. When this was converted to Fahrenheit, however, the rounding was forgotten and 98.6 was taken as accurate to the nearest tenth of a degree.
BIOSTATISTICSCore concepts (1) • Sample: A group of people, animals, etc. which is used to represent a larger ‘target’ population. • Best is a random sample • Most common is a convenience sample. • Subject to strong risk of bias. • Sample size: the number of units in the sample • Much of statistics concerns how samples relate to the population or to each other.
BIOSTATISTICSCore concepts (2) • Mean: average value. Measures the ‘centre’ of the data. Will be roughly in the middle. • Median: The middle value: 50% above and 50% below. Used when data is skewed. • Variance: A measure of how spread out the data are. Defined by subtracting the mean from each observation, squaring, adding them all up and dividing by the number of observations. • Standard deviation: square root of the variance.
Core concepts (3) • Standard error:SD/n, where n is sample size. Is the standard deviation of the sample mean, so measures the variability of that mean. • Confidence Interval: A range of numbers which tells us where we believe the correct answer lies. For a 95% confidence interval, we are 95% sure that the true value lies in the interval, somewhere. • Usually computed as: mean ± 2 SE
Example of Confidence Interval • If sample mean is 80, standard deviation is 20, and sample size is 25 then: • SE = 20/5 = 4. We can be 95% confident that the true mean lies within the range 80 ± (2*4) = (72, 88). • If the sample size were 100, then SE = 20/10 = 2.0, and 95% confidence interval is 80 ± (2*2) = (76, 84). More precise.
Core concepts (4) • Random Variation (chance): every time we measure anything, errors will occur. In addition, by selecting only a few people to study (a sample), we will get people with values different from the mean, just by chance. These are random factors which affect the precision (SD) of our data but not the validity. Statistics and bigger sample sizes can help here.
Core concepts (5) • Bias: A systematic factor which causes two groups to differ. For example, a study uses a collapsible measuring scale for height which was incorrectly assembled (with a 1” gap between the upper and lower section). • Over-estimates height by 1” (a bias). • Bigger numbers and statistics don’t help much; you need good design instead.
BIOSTATISTICSInferential Statistics • Draws inferences about populations, based on samples from those populations. Inferences are valid only if samples are representative (to avoid bias). • Polls, surveys, etc. use inferential statistics to infer what the population thinks based on talking to a few people. • RCTs use them to infer treatment effects, etc. • 95% confidence intervals are a very common way to present these results.
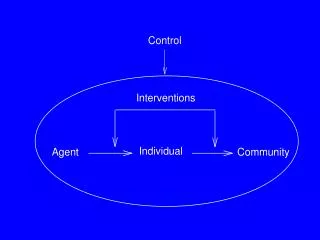
Your practicepatients Target population Inferences drawn (Confidence intervalused to indicateaccuracy of extrapolatingresults to broaderpopulation from which sample was drawn) Population from which sample is drawn Sample
Effects of bias and random error on study results ┼ ┼ ┼ ┼ ┼ Population parameter Increasing systematic error (bias) Increasing random error Results from different samples
Hypothesis Testing • Used to compare two or more groups. • We first assume that the two groups are the same. • Compute some statistic which, under this null hypothesis (H0), should be ‘0’. • If we find a large value for the statistic, then we can conclude that our assumption (hypothesis) is unlikely to be true (reject the null hypothesis). • Formal methods use this approach by determining the probability that the value you observe could occur (p-value). Reject H0 if that value exceeds the critical value expected from chance alone.
Hypothesis Testing (2) • Common methods used are: • T-test • Z-test • Chi-square test • ANOVA • Approach can be extended through the use of regression models • Linear regression • Toronto notes are wrong in saying this relates 2 variables. It can relate many independent variables to one dependent variable. • Logistic regression • Cox models
Hypothesis Testing (3) • Interpretation requires a p-value and understanding of type 1 and type 2 errors. • P-value: the probability of observing a value of your statistic which is as big or bigger than you would find IF the null hypothesis were true • This is not quite the same as saying the chance that the difference is ‘real’ • Power: The chance you will find a difference between groups when there really is a difference (of a given amount). Depends on how big a difference you treat as important
Hypothesis testing (4) Actual Situation Results of Stats Analysis
Example of significance test • Association between sex and smoking: 35 of 100 men smoke but only 20 of 100 women smoke • Calculated chi-square is 5.64. The critical value is 3.84 (from table, for α = 0.05). Therefore reject H0 • P=0.018 (from a table). Under H0 (chance alone), a chi-square value as large as 5.64 would occur only 1.8% of the time.