Download

1 / 44
440 likes | 448 Views
This article discusses the use of multilevel regression to predict pizza quality in Chinatown based on factors such as cost, fuel type, and neighborhood. The analysis includes techniques such as linear regression, multiple regression, and interaction effects.

E N D
Predicting Pizza in Chinatown: An Intro to Multilevel Regression Harlan D. Harris, PhDJared P. Lander, MANYC Predictive Analytics MeetupOctober 14, 2010
1. How do costand fuel typeaffect pizza quality? 2. How do those factors vary by neighborhood?
Linear Regression (OLS) ratingi = β0 + βprice*pricei + εi find β’s to minimize Σεi2
Linear Regression (OLS) ratingi = βp + βprice*pricei + εi find β’s to minimize Σεi2
Multiple Regression 3 types of oven = 2 coefficients (gas is reference) ratingi = beta[intercept] * 1 + beta[price] * pricei + beta[oven=wood] * I(oveni=wood) + beta[oven=coal] * I(oveni=coal) + errori Goal: find betas/coefficients that minimize Σi errori2
Multiple Regression (OLS) ratingi = β0 + βprice*pricei + βwood*I(oveni = "wood") + βcoal*I(oveni = "coal") + εi find β’s to minimize Σεi2
Multiple Regression (OLS) with Interactions ratingi = β0 + βprice*pricei + βwood*I(oveni = "wood") + βwood,price*pricei* I(oveni = "wood") + βcoal*I(oveni = "coal") + βcoal,price*pricei* I(oveni = "coal") + εi
Groups Examples: teachers / test scores states / poll results pizza ratings / neighborhoods
Full Pooling (ignore groups) Examples: teachers / test scores states / poll results pizza ratings / neighborhoods ratingi = β0 + βprice*pricei +εi
No Pooling (groups as factors) ratingi = β0 + βprice*pricei + βB*I(groupi = "B") + βB,price*pricei* I(groupi = "B") + βC*I(groupi = "C") + βC,price*pricei* I(groupi = "C") + εi
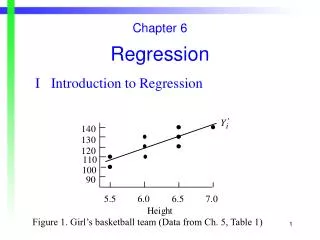
Data Summary in R > za.df <- read.csv("Fake Pizza Data.csv") > summary(za.df) Rating CostPerSlice HeatSource Neighborhood Min. :0.030 Min. :1.250 Coal: 17 Chinatown :14 1st Qu.:1.445 1st Qu.:2.000 Gas :158 EVillage :48 Median :4.020 Median :2.500 Wood: 25 LES :35 Mean :3.222 Mean :2.584 LittleItaly:43 3rd Qu.:4.843 3rd Qu.:3.250 SoHo :60 Max. :5.000 Max. :5.250 http://github.com/HarlanH/nyc-pa-meetup-multilevel-pizza
Viewing the Data in R > plot(za.df)
Visualize ggplot(za.df, aes(CostPerSlice, Rating, color=HeatSource)) + geom_point() + facet_wrap(~ Neighborhood) + geom_smooth(aes(color=NULL), color='black', method='lm', se=FALSE, size=2)
Multiple Regression in R > lm.full.main <- lm(Rating ~ CostPerSlice + HeatSource, data=za.df)> plotCoef(lm.full.main) http://www.jaredlander.com/code/plotCoef.r
Full-Pooling: Include Interaction > lm.full.int <- lm(Rating ~ CostPerSlice * HeatSource,data=za.df)> plotCoef(lm.full.int)
Visualize the Fit (Full-Pooling) > lm.full.int <- lm(Rating ~ CostPerSlice * HeatSource,data=za.df)
No Pooling Model lm(Rating ~ CostPerSlice * Neighborhood + HeatSource,data=za.df)
Visualize the Fit (No-Pooling) lm(Rating ~ CostPerSlice * Neighborhood + HeatSource,data=za.df)
Evaluation of Fitted Model • Cross-Validation Error • Adjusted-R2 • AIC • BIC • RSS • Tests for Normal Residuals
Use Natural Groupings • Cluster Sampling • Intercluster Differences • Intracluster Similarities
Multilevel Characteristics • Model gravitates toward big groups • Small groups gravitate toward the model • Best when groups are similar to each other • y_i = Intercept_j[i] + Slope_j[i] + noise • Intercept[j] = Intercept_alpha + Slope_alpha + noise • Slope[j] = Intercept_beta + Slope_beta + noise • Model the effects of the groups
Multi-Names for Multilevel Models • Multilevel • Hierarchical • Mixed-Effects • Bayesian • Partial-Pooling
Multi-Names for Multilevel Models • (1) Fixed effects are constant across individuals, and random effects vary. For example, in a growth study, a model with random intercepts a_i and fixed slope b corresponds to parallel lines for different individuals i, or the model y_it = a_i + b t. Kreft and De Leeuw (1998) thus distinguish between fixed and random coefficients. • (2) Effects are fixed if they are interesting in themselves or random if there is interest in the underlying population. Searle, Casella, and McCulloch (1992, Section 1.4) explore this distinction in depth. • (3) "When a sample exhausts the population, the corresponding variable isfixed; when the sample is a small (i.e., negligible) part of the population the corresponding variable is random." (Green and Tukey, 1960) • (4) "If an effect is assumed to be a realized value of a random variable, it is called a random effect." (LaMotte, 1983) • (5) Fixed effects are estimated using least squares (or, more generally, maximum likelihood) and random effects are estimated with shrinkage ("linear unbiased prediction" in the terminology of Robinson, 1991). This definition is standard in the multilevel modeling literature (see, for example, Snijders and Bosker, 1999, Section 4.2) and in econometrics. http://www.stat.columbia.edu/~cook/movabletype/archives/2005/01/why_i_dont_use.html
Bayesian Interpretation • Everything has a distribution (including the groups) • Group-level model is prior information for the individual-level coefficients • Group-level model has an assumed-normal prior • (Can fit multilevel models with Bayesian methods, or with simpler/faster/easier approximations.)
R Options • lme4::lmer() • nlme::lme() • MCMCglmm() • BUGS • Others/niche approaches…
Back to the Pizza • Model the overall pattern among neighborhoods • Natural clustering of pizzerias in neighborhoods adds information • Neighborhoods with many/few pizzerias • Many: trust data, ala no-pooling model • Few: trust overall patterns, ala full-pooling model
Back to the Pizza Use Neighborhoods as natural grouping
Multilevel Pizza • 5 slope coefficients and 5 intercept coefficients, one of each per neighborhood • Slopes/intercepts are assumed to have Gaussian distribution • Ideally, could describe all 5 slopes with 2 numbers (mean/variance) • Neighborhoods with little data don’t get freedom to set their own coefficients – get pulled towards overall slope or intercept
R syntax lm.me.cost2 <- lmer(Rating ~ HeatSource + (1+CostPerSlice | Neighborhood), data=za.df)
Results (Partial-Pooling) lm.me.cost2 <- lmer(Rating ~ HeatSource + (1+CostPerSlice | Neighborhood), data=za.df)
Predicting a New Pizzeria Neighborhood: Chinatown Cost: $4.20 Fuel: Wood
Uncertainty in Prediction • Fitted coefficients are uncertain • arm::sim() • Model error term • rnorm(1, model matrix %*% sim$Neighborhood[ , ‘Chinatown’, ], variance) • New neighborhood – model possible coefficients • mvrnorm(1, 0, VarCorr(model)$Neighborhood) http://github.com/HarlanH/nyc-pa-meetup-multilevel-pizza
Other Examples • Red State Blue State
Other Examples • Tobacco Usage
Other Examples • Diabetes Prevalence
Other Examples • Insufficient Fruit and Vegetable Intake
Other Examples • Clean Drinking Water
Steps to Multilevel Models • Full-Pooling Model • No-Pooling Model • Separate Models • Two–Step Analysis
How Many Groups? How Many Observations? • As few as one or two groups • Even two observations per group • Can have many groups with just one observation
Larger Datasets • Andy Gelman: “The Blessing of Dimensionality” • More Data Add Complexity • Because you can
Resources • Gelman and Hill (ARM) • Pineiro & Bates • Snijders and Bosker • R-SIG-Mixed-Models (http://glmm.wikidot.com/faq) • (SAS/SPSS)