Download

1 / 31
310 likes | 471 Views
Eliminating the Store Queue. Stephen Somogyi. CALCM Seminar April 3, 2007. Out-of-order Execution. Extracts instruction level parallelism Independent instructions run out of program order Hides 10’s of cycles of latency Effectiveness dependent on window size

E N D
Eliminating the Store Queue Stephen Somogyi CALCM Seminar April 3, 2007
Out-of-order Execution • Extracts instruction level parallelism • Independent instructions run out of program order • Hides 10’s of cycles of latency • Effectiveness dependent on window size • Larger window higher performance • Instruction window difficult to scale • ROB, LSQ, wakeup, select…
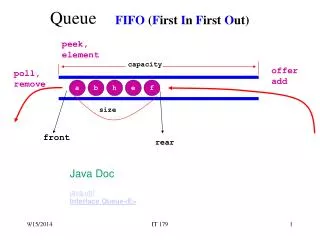
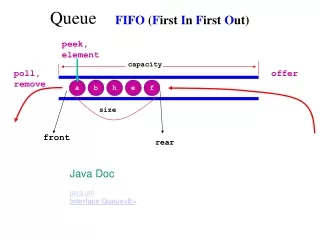
Store Queue • Part of load-store queue • Enforces ordering between loads and stores • Forwards data from stores to loads (same addr.) • In-order commit to memory system • Structure: CAM • Age-based search Newest Load A Store C Store A Load A Load B Store A Oldest Drain to cache
Solution: No Store Queue! • Store-load forwarding very repetitive • Between pairs of instructions • Predict & forward value directly from store to load • In-order re-execution for mispredictions • Commit already in program order • Buffer store values in register file until commit • No need for store queue
Contributions [MICRO `06] • Fire-and-Forget [Subramaniam and Loh, Georgia Tech] • Pushes store’s value into load queue • NoSQ [Sha, Martin and Roth, UPenn] • Pulls store’s value from register file • Both eliminate the store queue (solve scalability) • No performance loss
Outline • Store Vulnerability Window • Fire-and-Forget • NoSQ • Results • Conclusion
Store Vulnerability Window (SVW)[Roth, ISCA `05] • Motivation: • Frequent load re-execution hurts performance • Need to know which addresses written long ago • Solution: • Maintain dynamic store sequence number (SSN) • Track most recent store to each address • Using SSNs, can determine if a load is vulnerable
SVW Operation • At store commit: • Track SSN in store sequence bloom filter (SSBF)SSBF[address] = SSNcommit • SSNcommit++ SSNcommit = 11 SSBF Store A A, SSN: 11
SVW Operation • At load dispatch: • Remember SSNnvul = SSNcommit • Prior to load commit: • Lookup SSNcheck = SSBF[address] • Load is vulnerable only if SSNcheck > SSNnvul • Bloom filter aliasing • Possible false positives, but no false negatives
Outline • Store Vulnerability Window • Fire-and-Forget • NoSQ • Results • Conclusion
Fire-and-Forget • Pushes store value to load • Maintain dynamic load sequence number (LSN) • Incremented on every load • Stored in load queue
FnF Operation (1) • A store tracks where it would have been in LQ • Take LSNstore at rename • Save in store PC table (SPCT) on commit Load Queue SPCT newest LSN=9 A, PC1, LSN:9 PC1: Store A LSN=8 LSN=7 LSN=6 LSN=5 oldest
FnF Operation (2) • A load re-executes, finds incorrect value • Looks up most recent store to its address • Distance = LSNcurrent – LSNstore • Saves distance in load distance predictor (LDP) re-execute:PC2: Load A (LSN = 23) SPCT LDP A, PC1, LSN:9 PC1, dist: 14
FnF Operation (3) • Also on load re-execution • Set load consumption predictor (LCP) flag for load re-execute:PC2: Load A (LSN = 23) LCP PC2, useFwd: 1
Firing and Forgetting • When ready, store consults LDP • Predicted LQ entry = LSNcurrent + LDPdist • Write value into predicted entry • At dispatch, load consults LCP • If flag set, use forwarding (may have to wait) • If not set, use cache
Final Detail • SQ still used for storing values in program order • Instead, use ROB • May need to allocate physical register to hold value • Then SQ serves no remaining purpose
Outline • Store Vulnerability Window • Fire-and-Forget • NoSQ • Results • Conclusion
No Store Queue (NoSQ) • Pulls store value to load • Opposite of FnF • Does not dispatch stores to OoO engine • Uses dynamic store sequence numbers (SSN) • Separate counters for rename and commit
General NoSQ Forwarding • For loads far from forwarding store: • Forward through cache • For loads close to forwarding store: • Forward through register file • Map register input to store as output from load • Speculative Memory Bypassing [Moshovos and Sohi, MICRO `97]
Stores (1) • At rename: • Update store register queue (SRQ) • SSNrename++ SSNrename = 8 SRQ Store A,src reg. = 43 SSN:8, reg43
Stores (2) • At commit: • Normal operation for SVW • Update SSBF[address] = SSNcommit • SSNcommit++ SSNcommit = 11 SSBF Store A A, SSN: 11
Loads (1) • At commit: • Train store-load bypassing predictor (SLBP) • With distance from most recent store • Distance = SSNcommit – SSBF[address] SSNcommit = 27 SSBF SLBP PC2: Load A A, SSN: 11 PC2, dist: 16 –
Loads (2) • At rename: • Lookup predictor, calculate distance, lookup SRQ • Compare SSNpred with SSNcommit • Determine if most recent store already in cache SSNrename = 47 SLBP SRQ PC2: Load A PC2, dist: 16 SSN:31, reg22 –
Bypass During Rename At rename, a load may: • miss in predictor • Normal OoO execution; goes to cache • hit in predictor, store already committed • Normal OoO execution; goes to cache • hit in predictor, store not committed • Forward through register file • non-trivial forwarding (e.g., narrow write) • Delay load until store commits
Similarities • Rely on in-order back end • To correct mispredictions • SVW is the enabling idea • To update cache in program order • Additional register file pressure • Use dynamic instruction sequence numbers • For distance prediction • Most bypassed loads never access cache
Outline • Store Vulnerability Window • Fire-and-Forget • NoSQ • Results • Conclusion
Methodology • SimpleScalar • Aggressive out-of-order configurations • ROB: 512-entry (NoSQ), 128- & 256-entry (FnF) • SPEC CPU2000 & Mediabench • Additional pointer/game apps for FnF
Performance Results • Expectation: • Lower performance due to mis-speculations • Result: • Performance improves 1%–3% (both NoSQ & FnF) • Explanation: • Reduced issue queue / cache port contention
Selected Other Results • Power for Fire-and-Forget • CACTI 4.1, 65nm technology • FnF uses 50% power of traditional associative SQ • However, only accounts for 2% of total power • Data cache read bandwidth for NoSQ • Store-load forwarding reduces cache pressure • Load re-execution increases pressure • On average, ~10% reduction in read bandwidth
Related Work • Non-Associative Load Queue [Cain & Lipasti, ISCA 04] • Load re-execution to address power in LQ • Stores never forward, only write to cache • Store Queue Index Prediction [Sha, et al, MICRO 05] • Extension to SVW • Direct-mapped indexing instead of associative SQ • Much work on reducing complexity • Partitioned / hierarchical designs • Reduce, but do not eliminate, age-based search
Conclusion • Enabling idea: store vulnerability window • Lightweight detection for load re-execution • NoSQ and Fire-and-Forget • Predict store-load forwarding • Based on dynamic load/store instruction counts • Eliminate need for store queue structure • No performance loss relative to traditional SQ